

En esta publicación del blog, comprenderás:
- Qué son los conjuntos de datos, los beneficios que ofrecen, cómo funcionan, cuándo tiene sentido usarlos y dónde encontrar conjuntos de datos de alta calidad y confiables.
- Qué son las APIs de scraping web, las ventajas que implican, cómo funcionan, cuándo depender de ellas y dónde encontrar las más escalables.
- Cómo usar ambas en escenarios similares a través de ejemplos guiados.
- Cómo se comparan los conjuntos de datos y las APIs de scraping web, y cuál es mejor según tus necesidades.
- Si tiene sentido usarlas juntas.
¡Comencemos!
Profundizando en el mundo de los conjuntos de datos
Comenzaremos esta guía de conjuntos de datos vs APIs de scraping web con una introducción a los conjuntos de datos.
¿Qué es un conjunto de datos?
Un conjunto de datos es una colección estructurada de información organizada para facilitar el análisis, procesamiento y reutilización. Generalmente se almacenan en formatos como CSV, JSON o SQL, y pueden incluir texto, números, imágenes, videos y otros tipos de datos.
La mayoría de los conjuntos de datos se centran en un tema, industria, mercado o área de interés específica, como B2B, retail y otros. Este enfoque más específico ayuda a las empresas e investigadores a extraer información, identificar tendencias y apoyar la toma de decisiones basada en datos.
Los conjuntos de datos generalmente se consideran instantáneas estáticas de datos recopilados en un momento específico. Sin embargo, la mayoría de los mejores proveedores de conjuntos de datos ofrecen servicios para recibir registros actualizados periódicamente obteniendo información actualizada de las fuentes de datos subyacentes.
Específicamente, los tres principales beneficios que ofrecen los conjuntos de datos son:
- Listos para usar: Datos pre-recopilados y estructurados, inmediatamente utilizables para análisis, IA o aplicaciones empresariales. No se requieren conocimientos técnicos.
- Eficiencia de costos: Reduce la necesidad de recursos internos de recopilación de datos e ingeniería.
- Escalabilidad: Proporciona acceso a grandes conjuntos de datos que cubren millones o miles de millones de registros en distintas industrias.
Cómo funcionan los conjuntos de datos
La mayoría de los conjuntos de datos modernos provienen de la web, que es la fuente de información pública más grande y actualizada del mundo. Después de todo, constantemente se generan nuevos datos en sitios web, mercados y plataformas de redes sociales.
El proceso de creación de conjuntos de datos implica los siguientes pasos:
- Recopilación de datos: La información se obtiene de una o más fuentes, más comúnmente sitios web mediante scraping web, APIs o feeds públicos. Dependiendo del caso de uso, esto puede incluir listados de productos, precios, reseñas, ofertas de empleo, contenido de redes sociales o datos de empresas.
- Limpieza y validación de datos: Los datos sin procesar suelen estar desordenados, incompletos o duplicados. En este paso, se eliminan los errores, se estandarizan los formatos y se gestionan los valores faltantes. Los datos se validan para garantizar precisión y consistencia.
- Estructuración de datos: Los datos limpios se organizan en un formato consistente como CSV, JSON o Parquet. Esto facilita su almacenamiento en bases de datos o almacenes de datos para consultas y su uso en análisis de datos o flujos de trabajo de IA.
Aunque estos pasos técnicamente pueden realizarse internamente, generalmente se delegan a un proveedor de conjuntos de datos. Esto se debe a que recopilar y procesar datos a gran escala requiere herramientas y experiencia especializadas. Recuerda que algunos conjuntos de datos pueden incluir miles de millones de registros.
Una vez procesados, los proveedores de conjuntos de datos distribuyen los datos a través de diferentes métodos de entrega. Estos incluyen descargas directas para conjuntos de datos más pequeños, integraciones con S3 y acceso basado en API.
Nota: No todos los conjuntos de datos provienen de la web. Algunos se crean a través de encuestas, estudios de investigación, sensores, sistemas internos de empresas o combinando múltiples fuentes. Por ejemplo, pueden combinar datos públicos abiertos con información propietaria o recopilada de forma privada.
Casos de uso
A continuación se presentan algunos de los escenarios más relevantes para los conjuntos de datos en empresas grandes, pequeñas empresas, individuos y el sector público:
- Entrenamiento de modelos de IA: Los conjuntos de datos son el núcleo de los procesos de entrenamiento de machine learning e IA. Al alimentar los modelos con grandes volúmenes de datos de alta calidad, aprenden patrones y desarrollan capacidades como comprensión del lenguaje, reconocimiento de imágenes, recomendaciones y predicciones.
- Análisis de tendencias de mercado: Analiza datos históricos del mercado para estudiar tendencias de la industria y comprender el comportamiento del cliente. Valida ideas de productos y apoya decisiones estratégicas basadas en datos externos del mundo real en lugar de suposiciones.
- Análisis de redes sociales: Extrae información sobre el comportamiento del usuario, el engagement y el sentimiento. Monitorea marcas, analiza audiencias, identifica influencers y evalúa el rendimiento del contenido en plataformas como Reddit, Facebook y otras.
- Inteligencia empresarial y toma de decisiones: Estudia precios, competidores y señales del mercado para descubrir oportunidades, optimizar la asignación de recursos y mejorar la toma de decisiones estratégicas.
- Reclutamiento e inteligencia de talento: Analiza datos del mercado laboral para encontrar candidatos, comprender tendencias de contratación, evaluar la demanda de habilidades y mapear las estructuras de la fuerza laboral de los competidores para mejorar las estrategias de reclutamiento.
- Desarrollo de productos y optimización de la experiencia del usuario: Analiza reseñas de usuarios, comentarios y datos de comportamiento para mejorar los productos. Perfecciona funciones, personaliza experiencias y optimiza los recorridos del usuario para aumentar la satisfacción y la retención.
Dónde obtener conjuntos de datos actualizados, estructurados y listos para IA
Entre los principales marketplaces de conjuntos de datos, Bright Data ocupa el primer lugar, ya que combina una infraestructura web
de datos a gran escala con conjuntos de datos listos para usar de nivel empresarial.
Su marketplace de conjuntos de datos ofrece conjuntos de datos pre-recopilados de más de 350 dominios web, con un total de más de 17 mil millones de registros. Estos cubren comercio electrónico, redes sociales, bienes raíces, finanzas, redes profesionales y muchas otras industrias. Los conjuntos de datos están limpios, estructurados, estandarizados y optimizados para IA y ML. Se entregan en formatos como JSON, CSV, Parquet y NDJSON.
Los conjuntos de datos de Bright Data también pueden personalizarse para objetivos muy específicos filtrándolos en múltiples dimensiones, incluidos criterios aplicados a campos de datos. Una capa adicional de filtrado con IA permite a los usuarios refinar grandes conjuntos de datos mediante consultas en lenguaje natural, haciendo la selección de datos más accesible.
Los datos se entregan a través de múltiples canales, incluido acceso por API, Amazon S3, Snowflake, webhooks, integraciones de almacenamiento en la nube y descargas directas. Esta flexibilidad lo hace adecuado tanto para casos de uso ligeros como para pipelines a escala empresarial.
Los conjuntos de datos de Bright Data cumplen con los estándares de cumplimiento GDPR y CCPA. También cuenta con procesos de validación, seguridad y control de calidad que garantizan la fiabilidad y el origen ético de los datos disponibles públicamente.
Los precios comienzan en $250 por conjunto de datos (100K registros), según el volumen y la frecuencia de actualización (mensual, trimestral o semestral).
Una visión general de las APIs de scraping web
Ahora que sabes qué son los conjuntos de datos y cuándo usarlos, estás listo para explorar los mismos aspectos de las APIs de scraping web.
¿Qué es una API de scraping web?
Una API de scraping web es un servicio que te permite extraer datos de sitios web sin gestionar tu propia infraestructura de scraping. Se encarga de tareas como recuperar páginas web de destino, eludir protecciones anti-scraping y anti-bots, y parsear los resultados en formatos estructurados.
Las APIs de scraping web tienden a apuntar a sitios web o fuentes de datos específicas, como plataformas de comercio electrónico, motores de búsqueda o sitios de redes sociales. Algunas son más genéricas o pueden ampliarse mediante IA para devolver datos estructurados de cualquier sitio web. Esto permite a las empresas y desarrolladores obtener datos en vivo o bajo demanda de fuentes en línea relevantes.
En particular, las tres ventajas principales de las APIs de scraping web son:
- Acceso a datos en tiempo real: Recupera información actualizada directamente de los sitios web cuando sea necesario.
- Sin gestión de infraestructura: No es necesario construir ni mantener scrapers, proxies y sistemas anti-bot.
- Escalabilidad: Recopila datos de cientos o miles de páginas de forma fiable y eficiente.
Cómo funcionan las APIs de scraping web
Internamente, una API de scraping web funciona así:
- Gestión de solicitudes: Un usuario envía una solicitud a la API especificando la URL de la página web de destino, con posibles argumentos para personalizar el comportamiento de scraping subyacente (por ejemplo, renderizado de JavaScript, ubicación de IP, etc.).
- Recuperación de páginas y gestión de acceso: La API obtiene las páginas web de destino mientras se ocupa de los desafíos técnicos como el renderizado de JavaScript, proxies, límites de velocidad, CAPTCHAs y otras protecciones anti-bot.
- Extracción de datos y parseo: El HTML sin procesar o el contenido de respuesta se procesa y transforma en formatos estructurados (por ejemplo, JSON, CSV y otros). Algunas APIs utilizan plantillas predefinidas, mientras que otras se basan en IA para extraer dinámicamente campos estructurados de cualquier página web.
- Entrega de datos: Los datos estructurados finales se devuelven al usuario a través de la respuesta de la API. Opcionalmente, también pueden enviarse a sistemas de almacenamiento como S3, webhooks o bases de datos para su posterior procesamiento.
Casos de uso
Aquí están los escenarios más importantes donde las APIs de scraping web marcan la diferencia:
- Estudio de mercado y seguimiento competitivo: Monitorea sitios web de competidores, cambios de precios y disponibilidad de productos. Detecta tendencias a medida que emergen y adapta las estrategias empresariales basándose en señales de mercado en constante evolución.
- Toma de decisiones financieras: Extrae datos de mercado en vivo como precios de acciones, movimientos de criptomonedas y actualizaciones de empresas. Apoya estrategias de trading, análisis de inversiones y gestión de riesgos basándose en actualizaciones en streaming.
- Monitoreo de comercio electrónico y optimización de precios: Rastrea listados de productos, niveles de inventario y fluctuaciones de precios en múltiples plataformas. Habilita precios dinámicos, descubrimiento de ofertas y optimización de catálogos usando datos web actualizados frecuentemente.
- Monitoreo de noticias y eventos: Recopila noticias de última hora, actualizaciones regulatorias y anuncios de la industria de múltiples fuentes. Mejora la conciencia situacional y apoya respuestas más rápidas a cambios del mercado o de políticas.
- Generación de leads e inteligencia de ventas: Extrae datos de negocios y contactos actualizados de directorios, sitios web de empresas y plataformas profesionales. Identifica nuevos prospectos y enriquece los pipelines de ventas con información constantemente actualizada.
- Monitoreo de marca y seguimiento de reputación: Observa menciones en chatbots de IA y motores de búsqueda. Rastrea el sentimiento de reseñas y discusiones en foros, redes sociales y sitios de noticias. Detecta cambios de sentimiento tempranamente y responde con prontitud a riesgos u oportunidades de reputación.
- Fundamentación de agentes de IA y acceso a la web: Equipa a los agentes de IA con acceso directo a APIs de scraping web para recuperar datos externos contextuales y frescos bajo demanda. Esto permite un razonamiento fundamentado, reduce las alucinaciones y permite a los agentes actuar sobre la información más reciente disponible en línea.
APIs de scraping web: ¿Cuál es el mejor proveedor?
Bright Data se destaca como el mejor proveedor de APIs de scraping web. Combina redes de proxies a gran escala con un ecosistema completo de Web Scraper API diseñado para la extracción de datos fiable, conforme y escalable.
Su biblioteca de Web Scraper API admite más de 600 scrapers prediseñados que cubren las principales fuentes de datos. Estos incluyen Amazon, LinkedIn, X/Twitter, Instagram, TikTok, YouTube, Walmart, Zillow, Indeed, Glassdoor, Booking, Airbnb, Yelp, Yahoo Finance, Facebook y muchos más. Estas APIs de scraping permiten la extracción directa de datos estructurados específicos de cada dominio en JSON, NDJSON o CSV.
Lo que hace destacar a Bright Data es su red global subyacente de más de 400M de IPs residenciales en 195 países. Esto permite una arquitectura a gran escala, lista para empresas, con un tiempo de actividad del 99,99% respaldado por SLA y una tasa de éxito de solicitudes del 99,95%.
La Web Scraper API de Bright Data gestiona automáticamente el ciclo de vida completo del scraping, incluida la rotación de proxies, la resolución de CAPTCHA, el renderizado de JavaScript, la limitación de velocidad y la elusión de anti-bots. También admiten solicitudes masivas (hasta 5K URLs por trabajo), scraping programado y pipelines de entrega flexibles.
Los precios son basados en uso y solo pagas por las solicitudes exitosas. El modelo de pago por uso comienza en $1,5 por 1K registros, con varios planes basados en suscripción disponibles para empresas y grandes corporaciones.
Conjuntos de datos y APIs de scraping web en un escenario del mundo real
Para entender cómo recuperar datos usando conjuntos de datos o APIs de scraping web, considera el mismo caso de uso de alto nivel. Quieres extraer datos de empresas de Crunchbase, en un caso para la prospección de clientes y en el otro para el análisis de empresas en vivo con IA.
El primer caso de uso requiere un conjunto de datos de Crunchbase, mientras que el segundo requiere una API de scraping web de Crunchbase. En los próximos dos capítulos, verás cómo acceder a ambos tipos de datos usando las soluciones de Bright Data.
Nota: El requisito previo para las secciones guiadas a continuación es que ya tengas una cuenta de Bright Data. De lo contrario, crea una nueva.
Comienza con los conjuntos de datos de Bright Data
En esta sección paso a paso, verás cómo recuperar un conjunto de datos de Crunchbase listo para usar de Bright Data.
Paso #1: Accede al conjunto de datos de Crunchbase
Comienza iniciando sesión en tu cuenta de Bright Data. En el panel de control, selecciona la opción “Dataset Marketplace” bajo el menú “Datasets”.
En la página “My datasets”, navega a la pestaña “Dataset Marketplace” y llegarás a esta página:
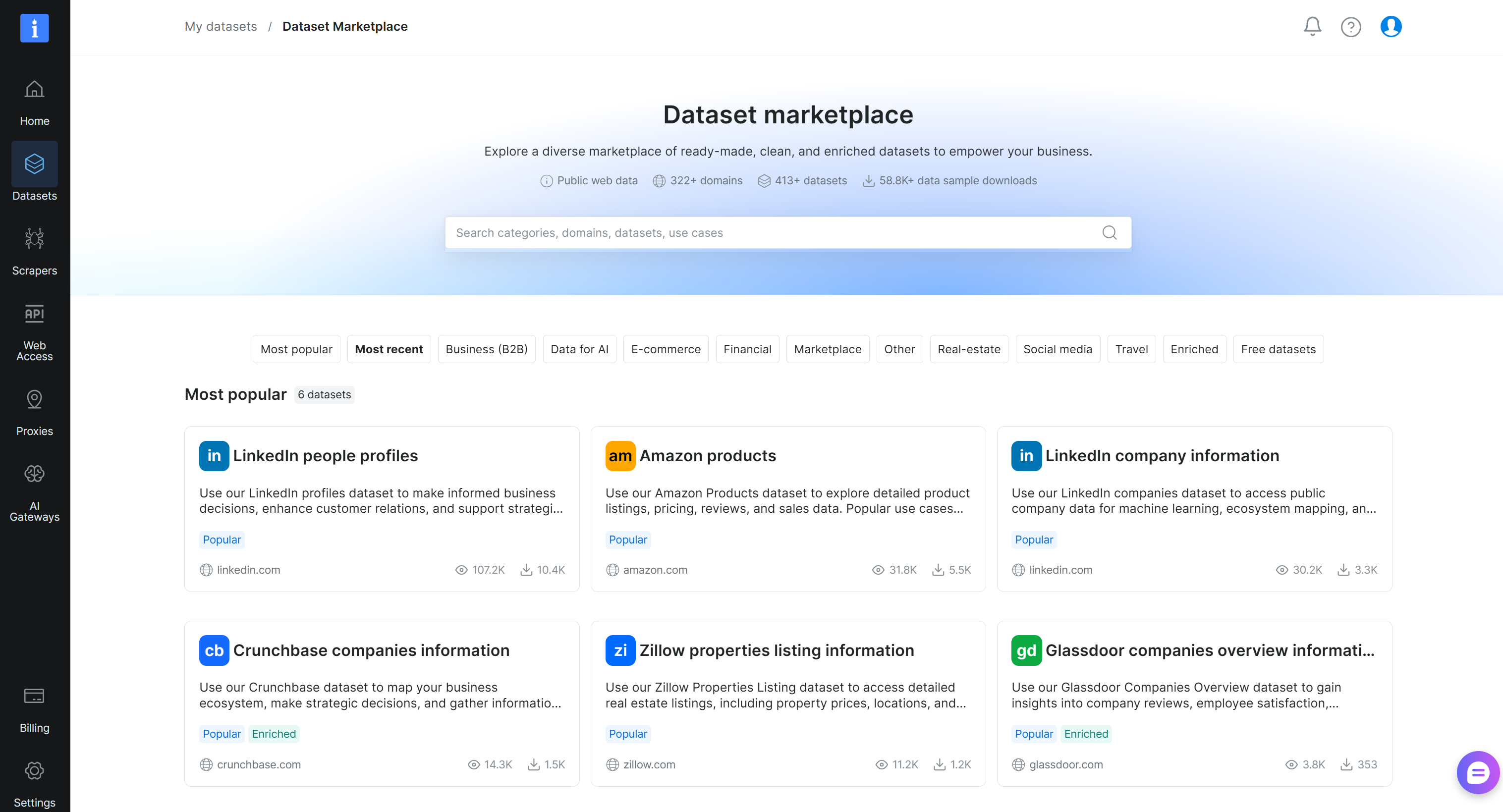
Busca “crunchbase” y selecciona el conjunto de datos “Crunchbase companies information”:
Luego serás llevado a la página del conjunto de datos “Crunchbase companies information”. ¡Excelente!
Paso #2: Familiarízate con el conjunto de datos
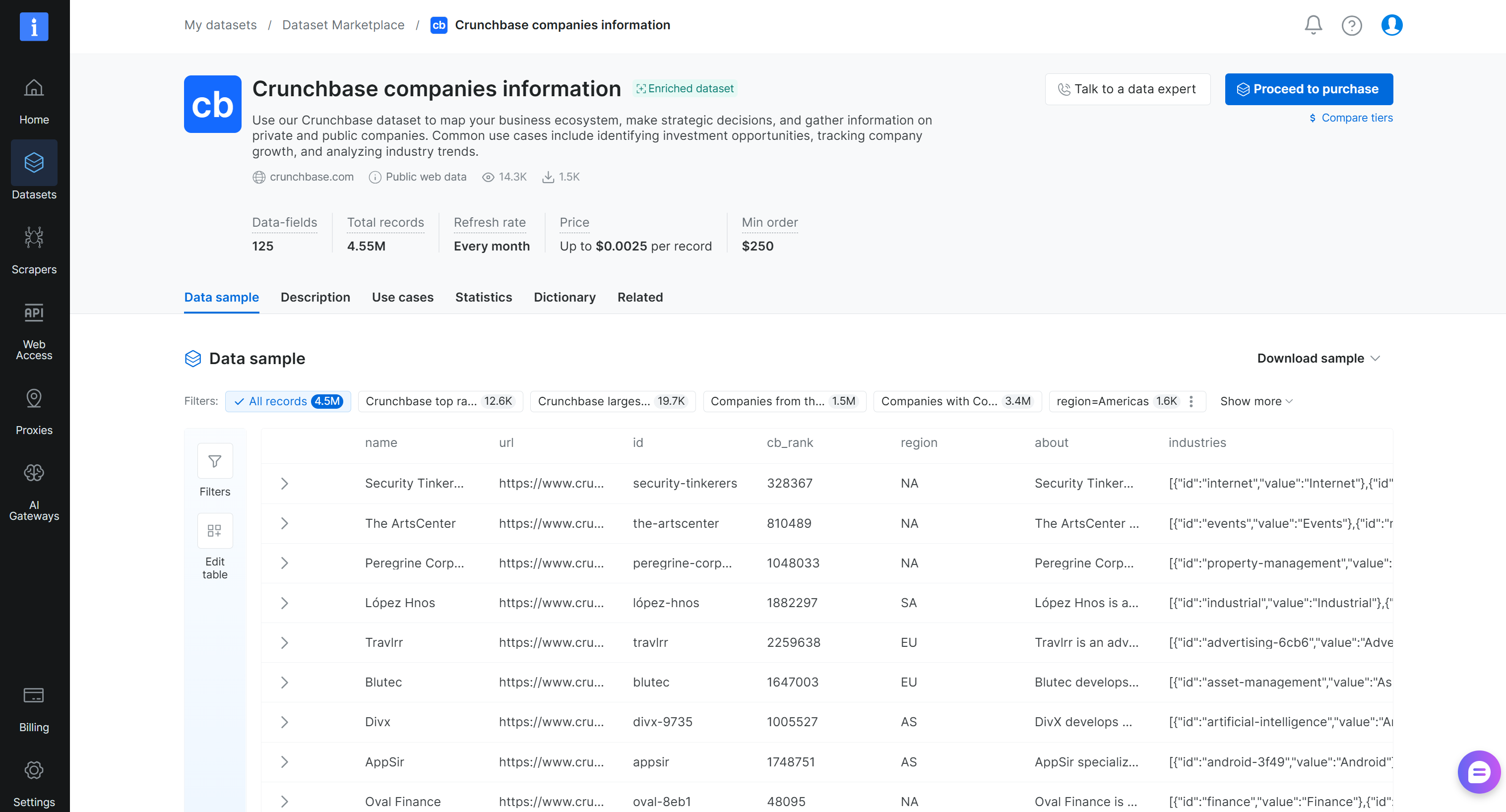
En la página del conjunto de datos “Crunchbase companies information”, puedes explorar el conjunto de datos. En detalle, puedes acceder a registros de muestra, explorar subconjuntos prediseñados (por ejemplo, las empresas de Crunchbase mejor clasificadas) y revisar estadísticas clave como las tasas de llenado de campos. También puedes ver el diccionario de datos completo, incluidos nombres de campos, tipos y descripciones, y aplicar filtros para refinar el conjunto de datos.
Si haces clic en el botón “Filters” de la izquierda, se abrirá el siguiente modal:
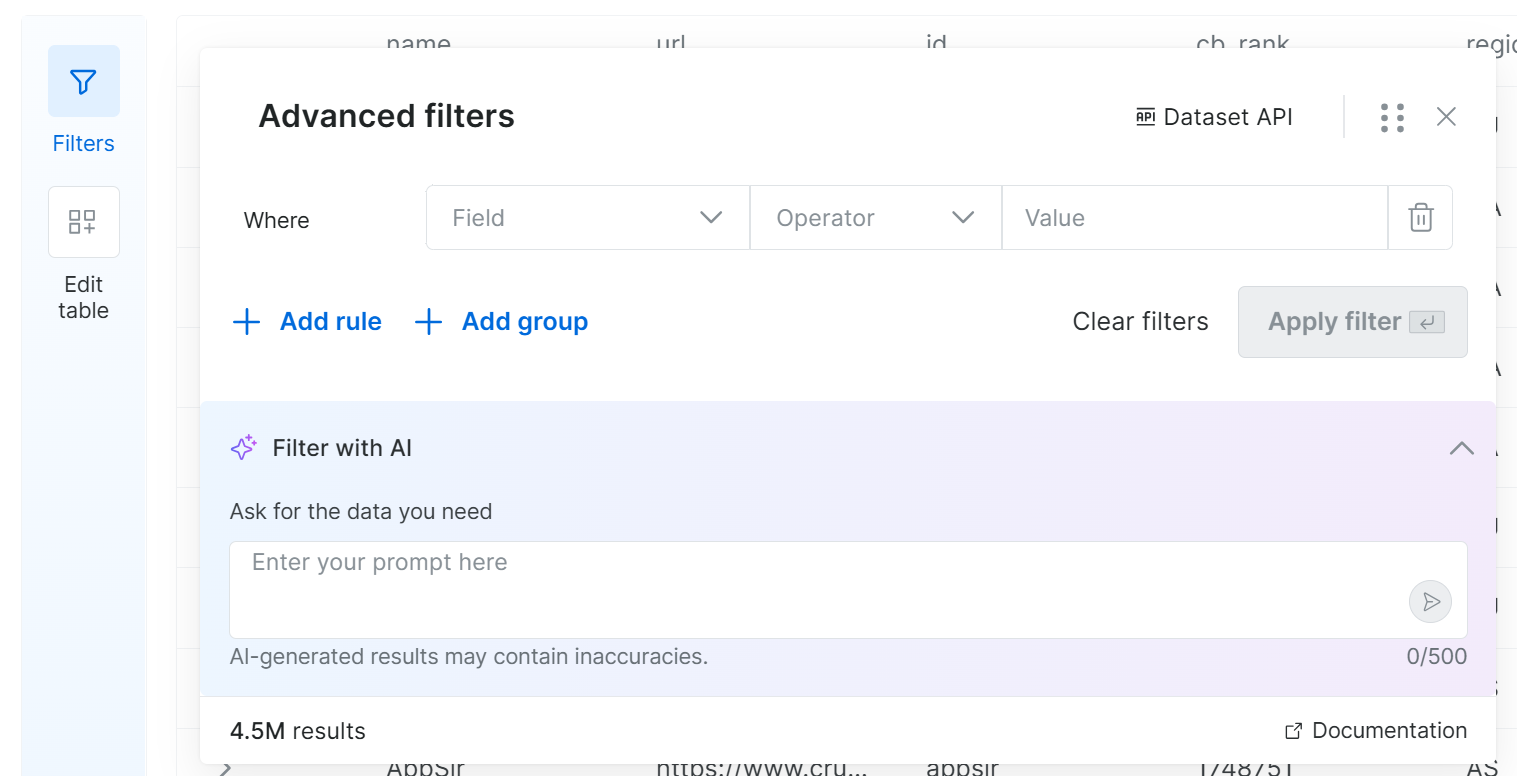
Gracias a esta función, puedes definir filtros estableciendo uno o más criterios en los campos seleccionados. De lo contrario, simplemente escribe un prompt en lenguaje natural y deja que el sistema genere los filtros por ti. ¡Increíble!
Paso #3: Compra el conjunto de datos
Después de filtrar los datos para tu caso de uso específico (o dejándolos como están), presiona el botón “Proceed to purchase”:

A continuación, define el tamaño del snapshot del conjunto de datos y selecciona la frecuencia de actualización:
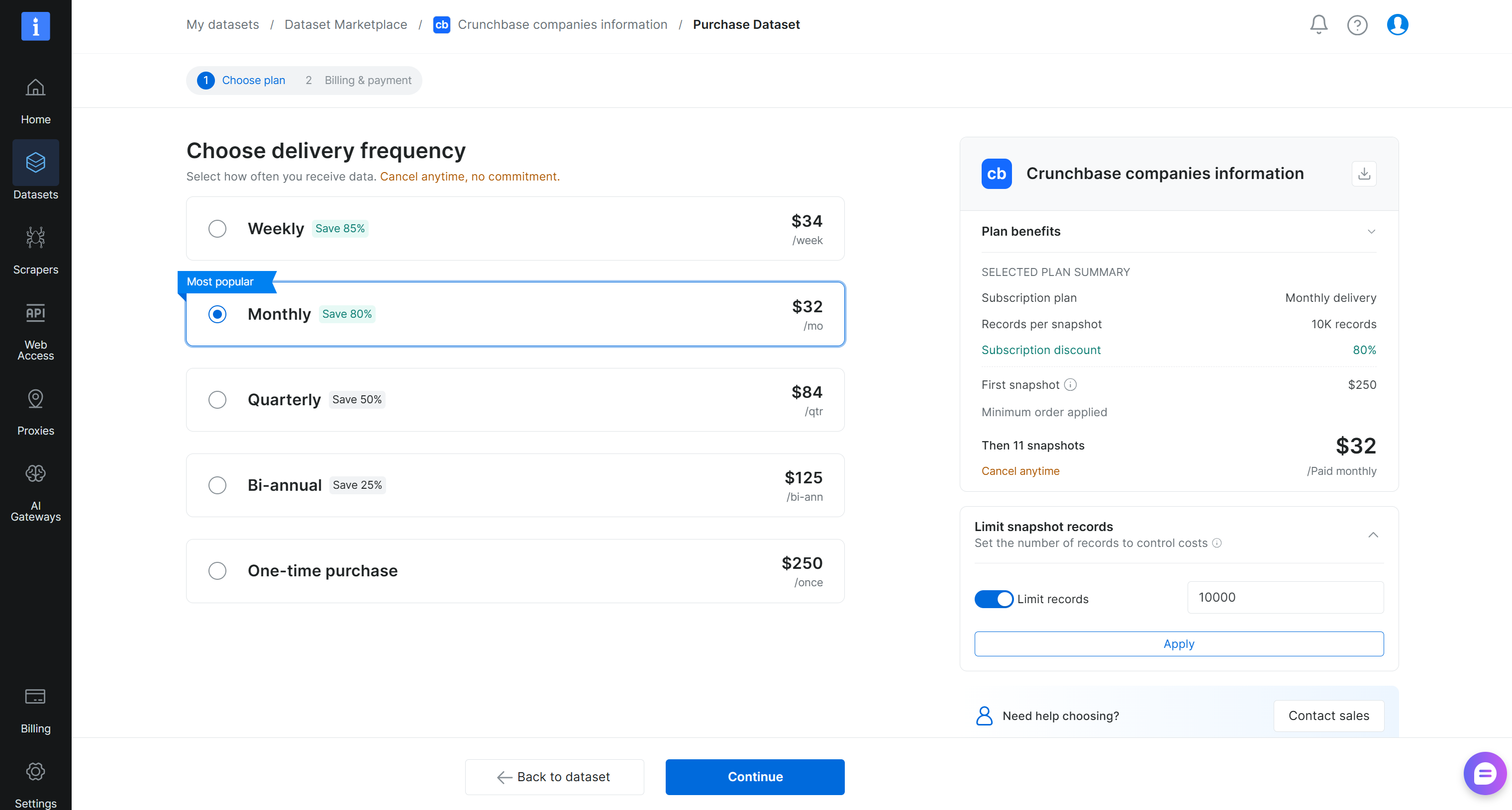
En este ejemplo, configuramos la entrega para incluir 10,000 registros de forma inmediata, seguidos de 11 actualizaciones mensuales continuas. Haz clic en “Continue” y completa el proceso de pago añadiendo tus datos de pago. ¡Genial!
Paso #4: Explora el conjunto de datos recibido
Cuando el conjunto de datos esté listo, recibirás una notificación por correo electrónico y podrás descargarlo desde el panel de control de Bright Data. Desde allí, puedes definir en qué formato descargar el conjunto de datos y configurar tu método de entrega preferido (descarga de archivo, S3, etc.).
En el caso de entrega en archivo plano en CSV, recibirás un archivo como este:
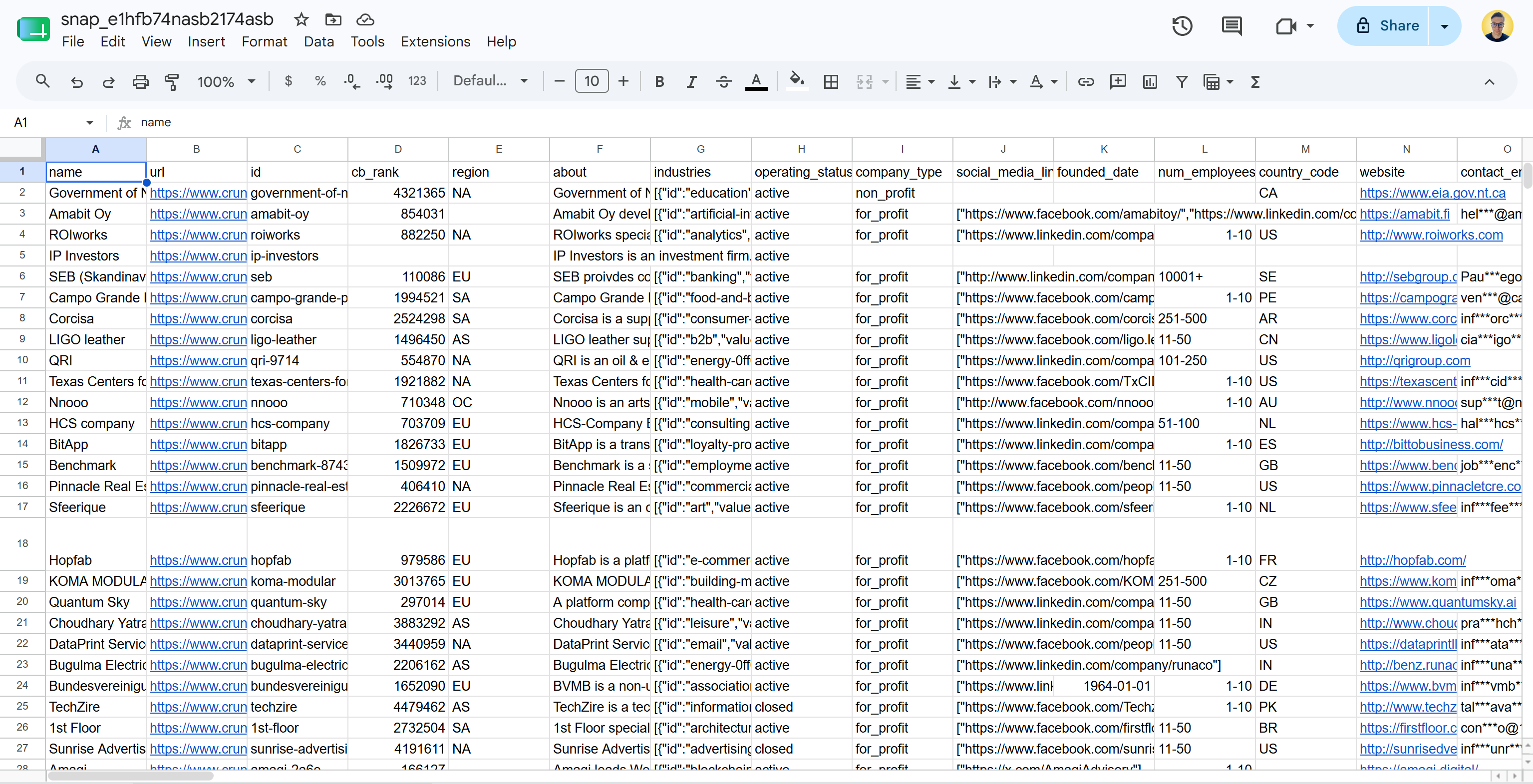
Ten en cuenta que esto incluye datos reales de Crunchbase listos para analizar en un formato estructurado. ¡Misión cumplida!
Próximos pasos
Con el conjunto de datos listo, ingrésalo en tu almacén de datos o base de datos para facilitar las consultas. También puedes integrarlo en tus pipelines de análisis y procesamiento de datos.
Por ejemplo, podrías:
- Usarlo para ajustar fino un modelo de IA.
- Alimentarlo a un sistema de IA para análisis, detección de tendencias o predicciones.
- Integrarlo en dashboards de BI para informes y monitoreo.
- Combinarlo con otros conjuntos de datos para enriquecer tus datos internos.
Estas son solo algunas ideas para convertir datos sin procesar en información útil para tu caso de uso específico.
Recopila datos frescos y estructurados mediante las APIs de scraping web de Bright Data
Aquí aprenderás cómo comenzar con las APIs de scraping web. Verás cómo recuperar datos estructurados y actualizados de Crunchbase usando la API Scraper de Crunchbase de Bright Data.
Nota: El requisito previo para esta sección es que ya tengas una clave API de Bright Data configurada. Si no es así, sigue la guía oficial para generar tu clave API de Bright Data.
Paso #1: Accede a la Web Scraper API de Crunchbase
Comienza iniciando sesión en tu cuenta de Bright Data. A continuación, selecciona la página “Scrapers Library” del menú:
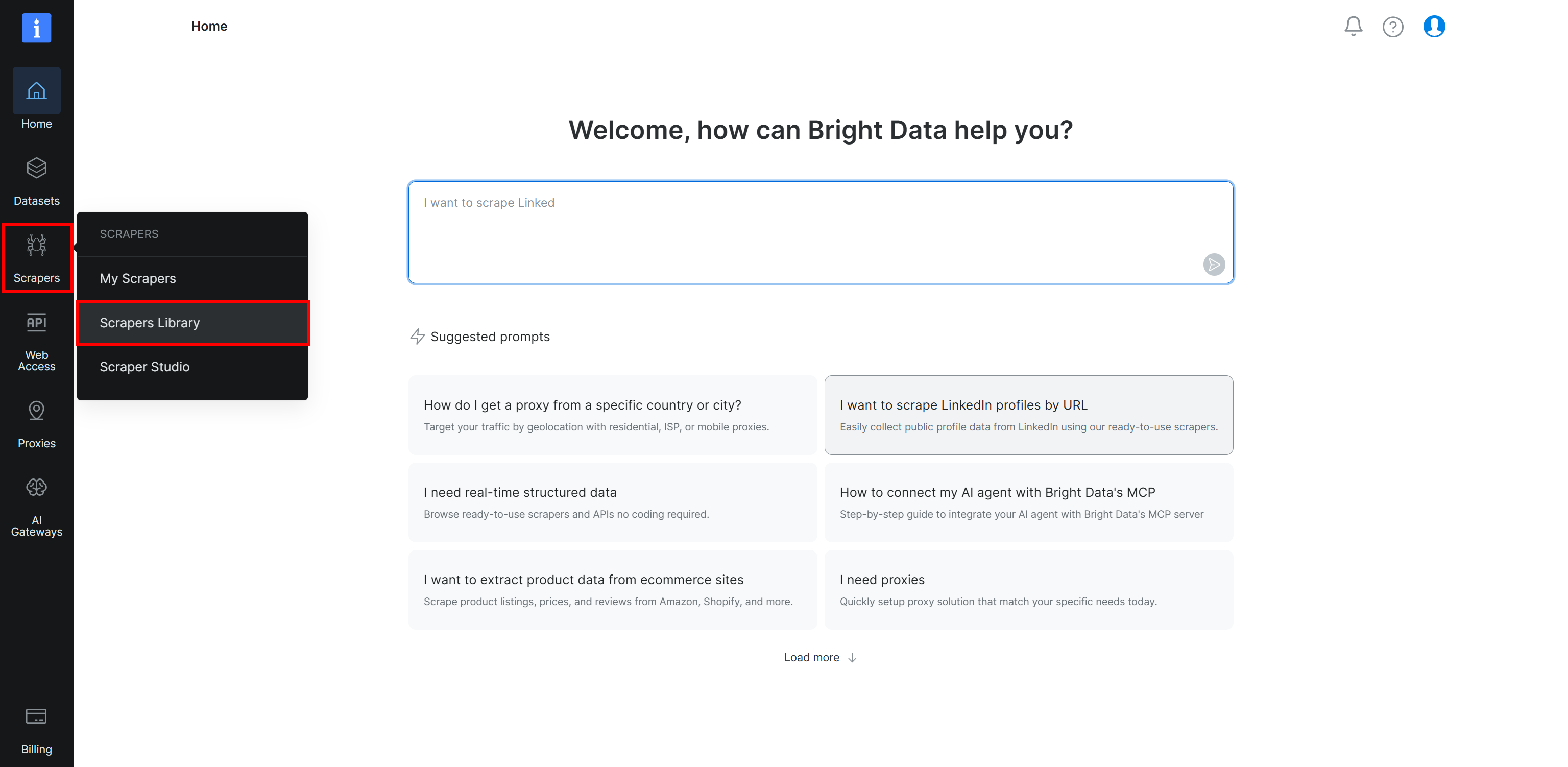
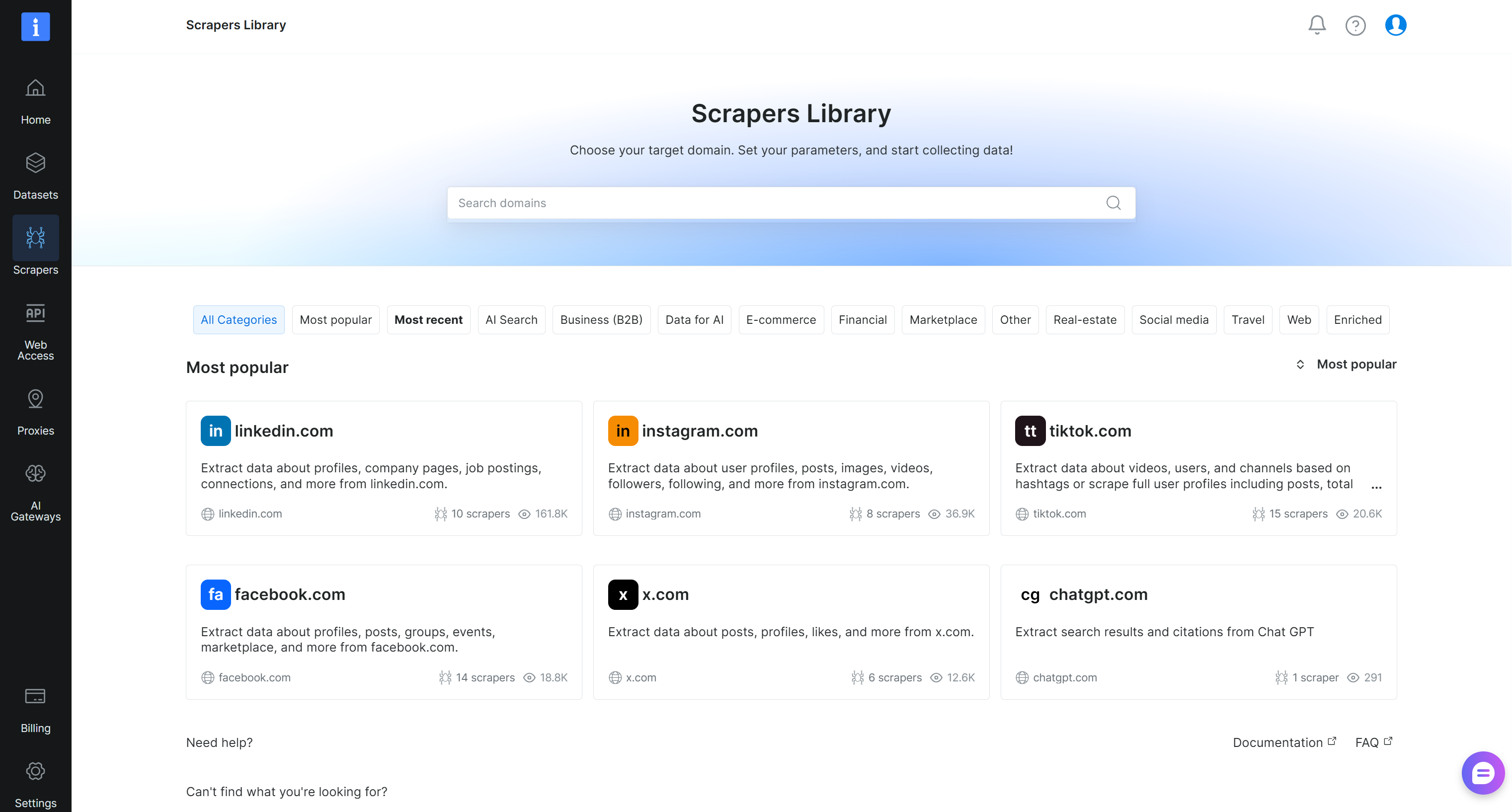
Llegarás a la página “Scrapers Library”, donde puedes explorar todas las APIs de Web Scraper de Bright Data disponibles:
Busca “crunchbase.com” y selecciona el scraper “crunchbase.com”:
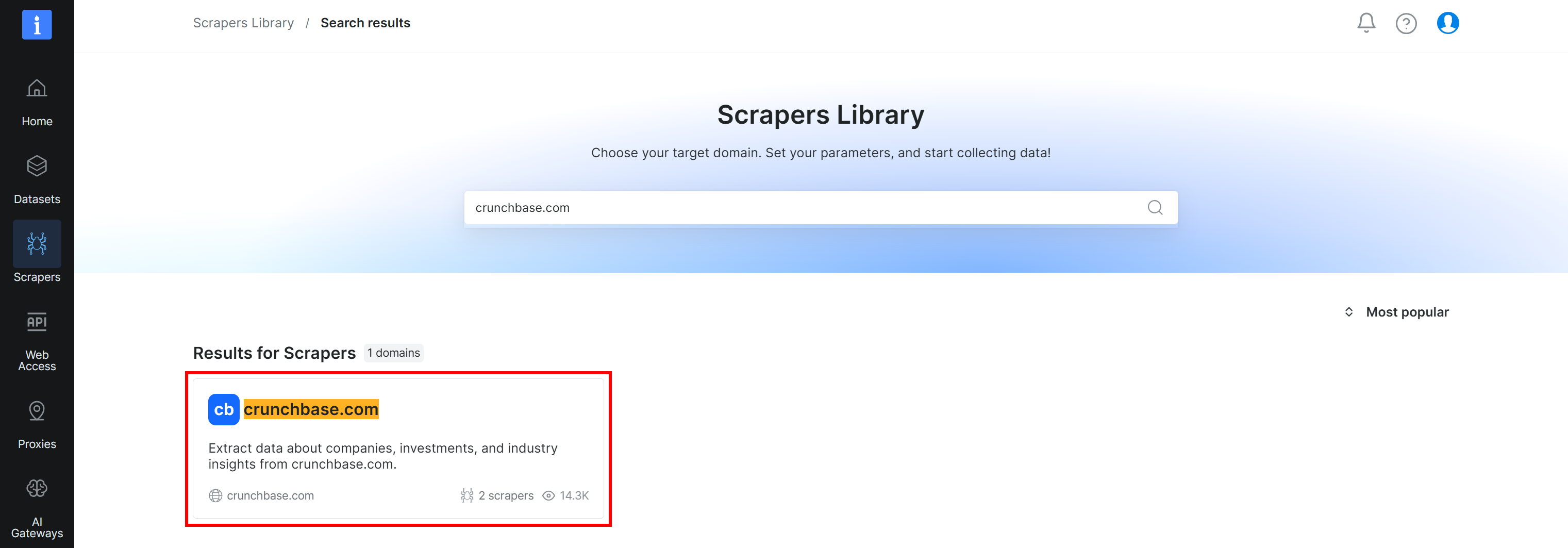
Luego llegarás a la página “crunchbase.com Scraper API” en el panel de control. ¡Excelente!
Paso #2: Comprende las opciones de la Scraper API
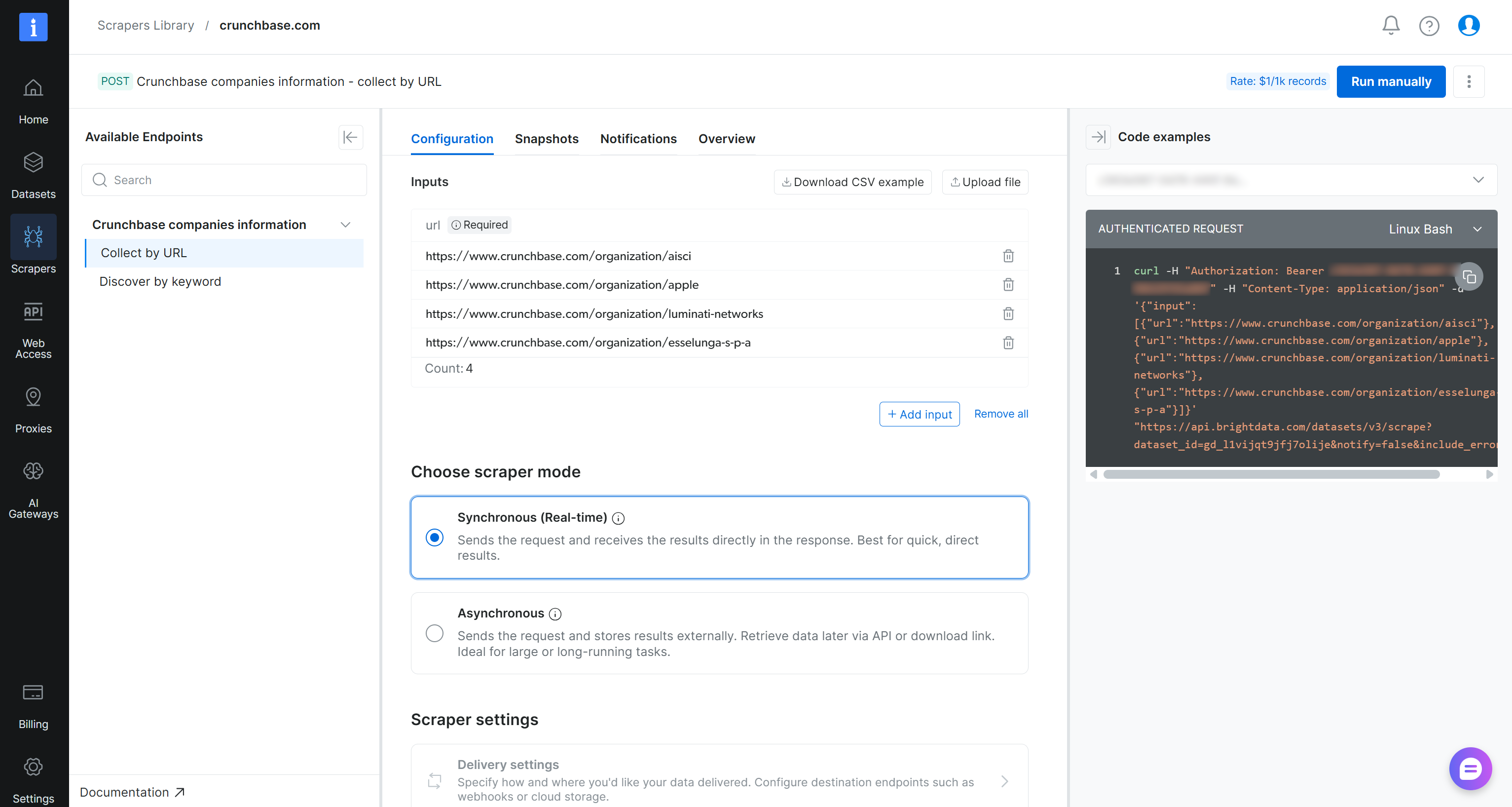
En la página de la Scraper API “crunchbase.com”, puedes acceder a todos los endpoints de scraping disponibles en el panel izquierdo. Para cada endpoint, puedes configurar una llamada a la API añadiendo las URLs de destino. También puedes elegir el modo de scraping (síncrono o asíncrono) y configurar las opciones de entrega de datos.
Importante: Ejecuta la API directamente haciendo clic en el botón “Run manually”. Una vez listo, podrás acceder a los datos extraídos desde la pestaña “Snapshots”. Este flujo de trabajo hace que la API sea accesible para usuarios no técnicos.
¡Excelente! Es momento de configurar una llamada específica a la API para obtener datos frescos de Crunchbase.
Paso #3: Configura la llamada a la API
En el lado derecho de la página, puedes acceder a fragmentos de código predefinidos para llamar a la API de scraping web. Estos se configuran automáticamente con tu clave API de Bright Data.
Por ejemplo, si quieres recuperar datos de la empresa Anthropic en Crunchbase usando Python, pega la URL de destino en la sección Inputs (es decir, https://www.crunchbase.com/organization/anthropic). Elige el modo “Synchronous (Real-time)” y luego selecciona el fragmento “Python (requests)” de las opciones disponibles:
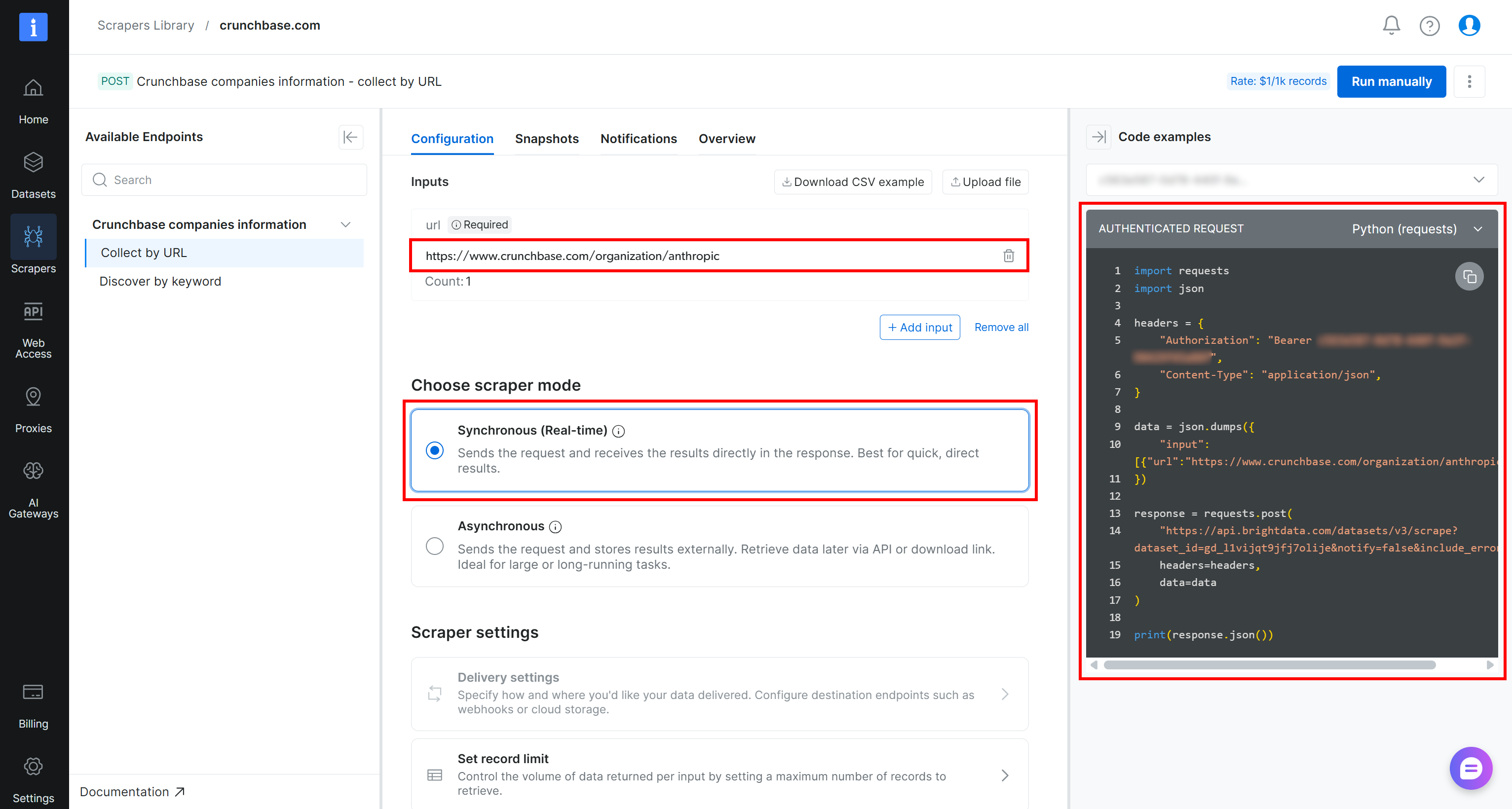
Este es el script que recibirás:
import requests
import json
headers = {
"Authorization": "Bearer <YOUR_BRIGHT_DATA_API_KEY>",
"Content-Type": "application/json",
}
data = json.dumps({
"input": [{"url":"https://www.crunchbase.com/organization/anthropic"}],
})
response = requests.post(
"https://api.brightdata.com/datasets/v3/scrape?dataset_id=gd_l1vijqt9jfj7olije¬ify=false&include_errors=true",
headers=headers,
data=data
)
print(response.json())¡Es hora de ejecutarlo para obtener los resultados!
Paso #4: Explora los resultados
Guarda el fragmento del panel de control de Bright Data localmente en un archivo como script.py.
Suponiendo que tienes Python instalado localmente, instala la dependencia requerida:
pip install requestsA continuación, ejecuta el script con:
python script.pyEl resultado se verá así:
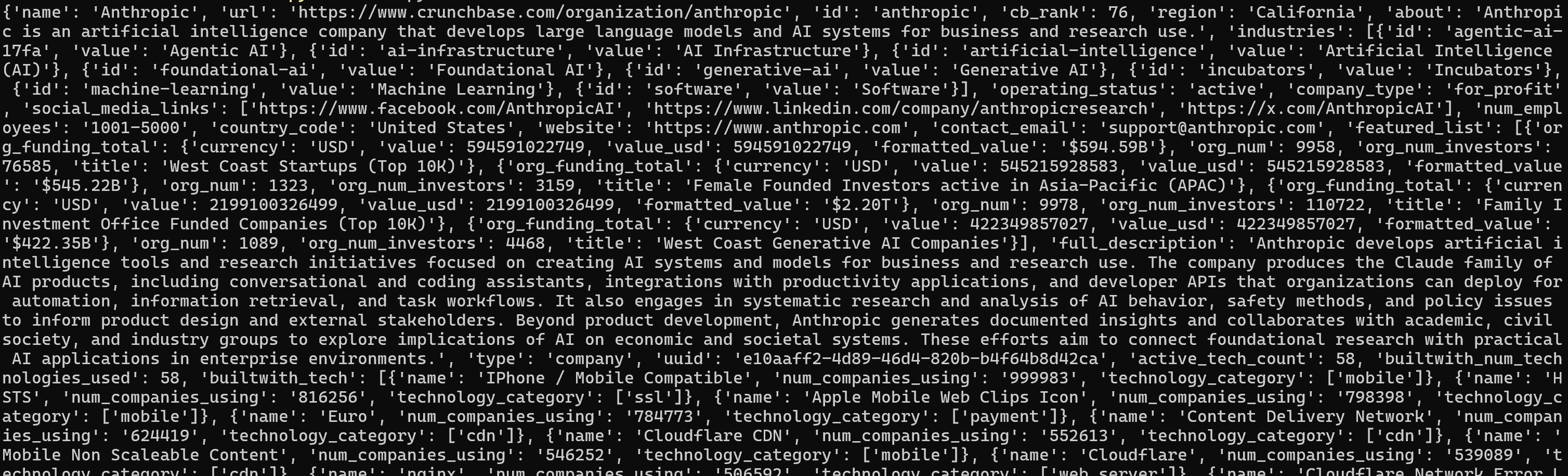
Para una mejor visualización, pega la salida en un visor de JSON:
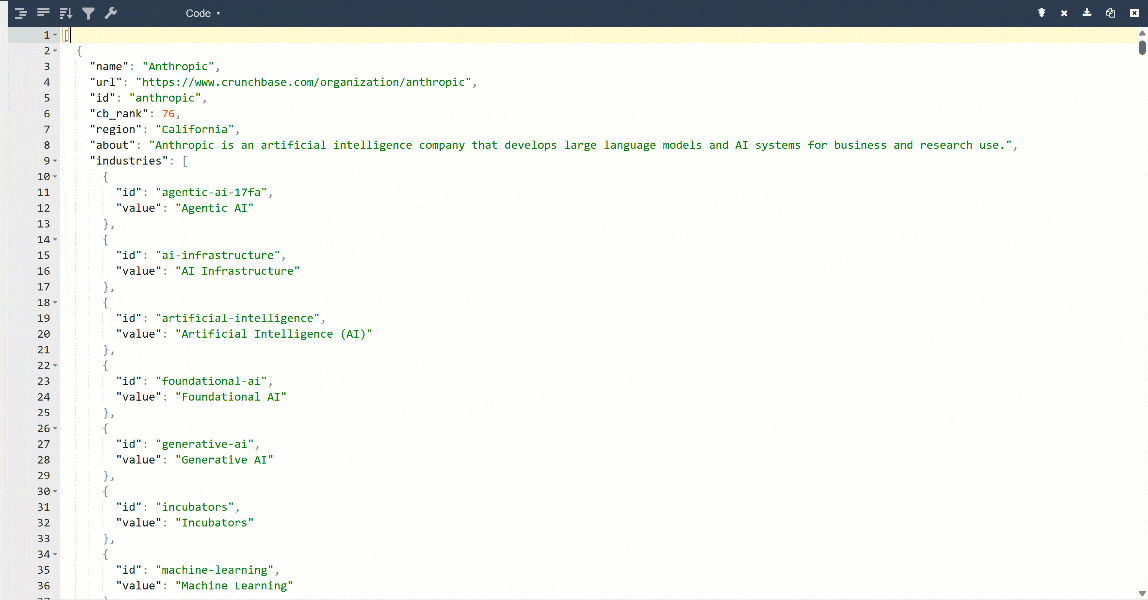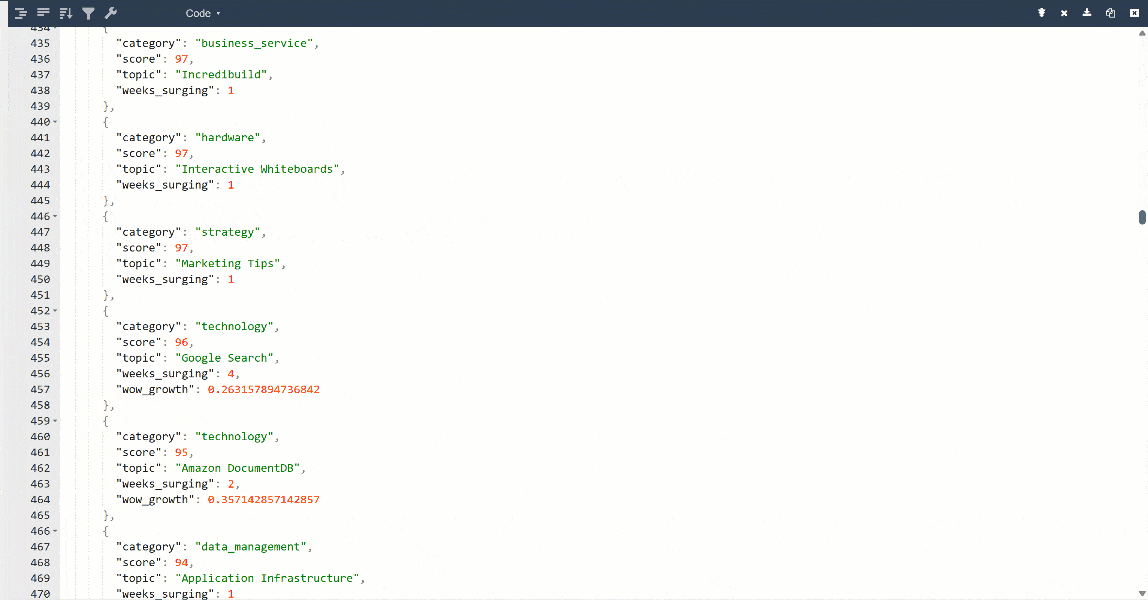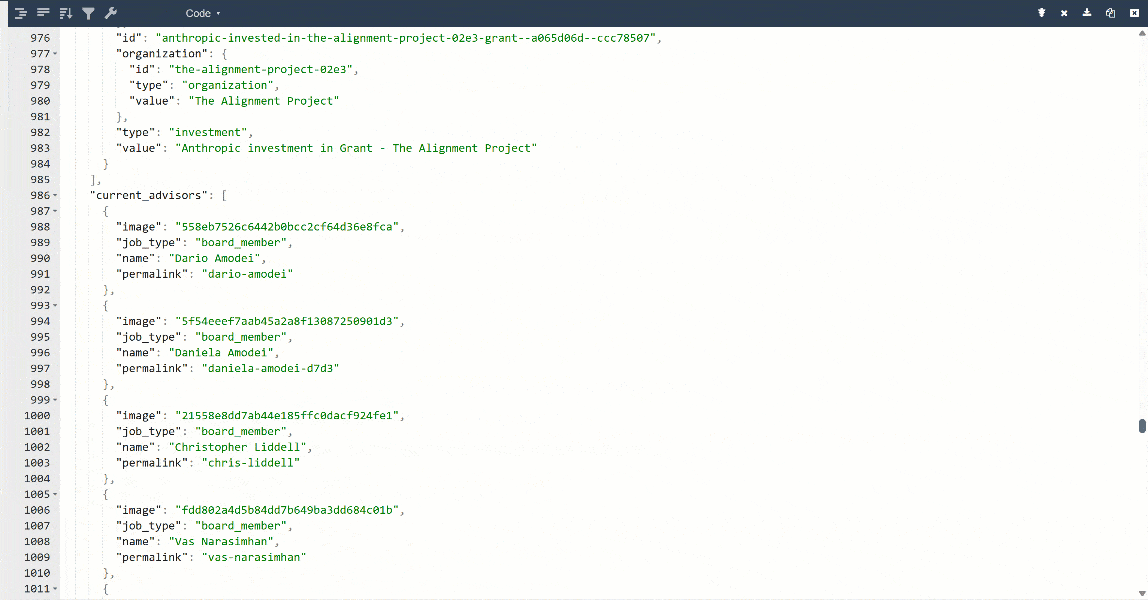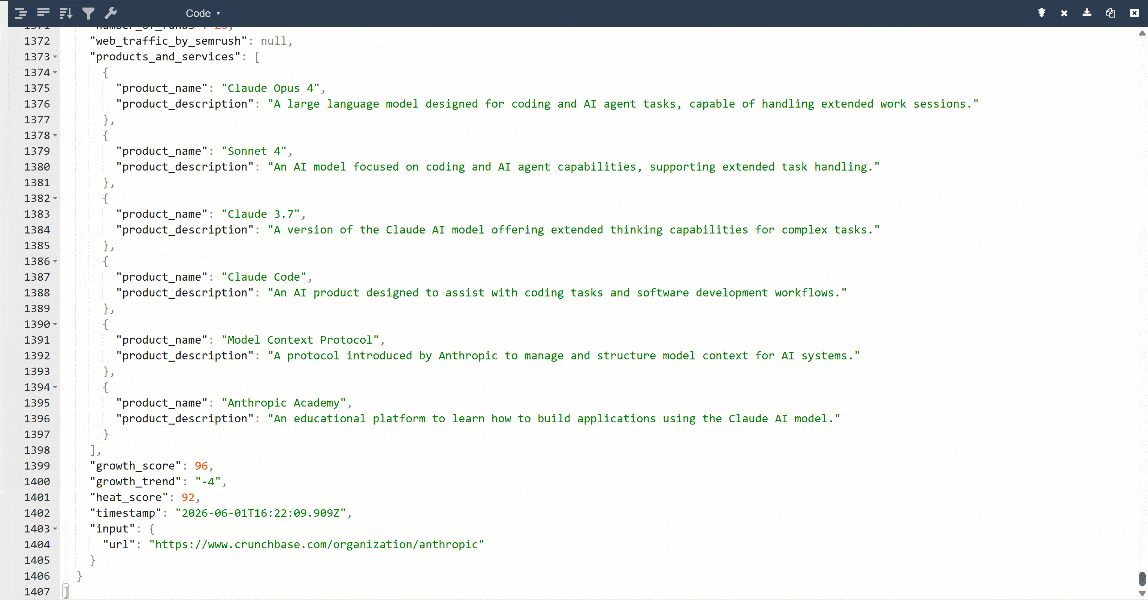
Estos son los mismos datos extraídos de la página de destino, pero en un formato estructurado:
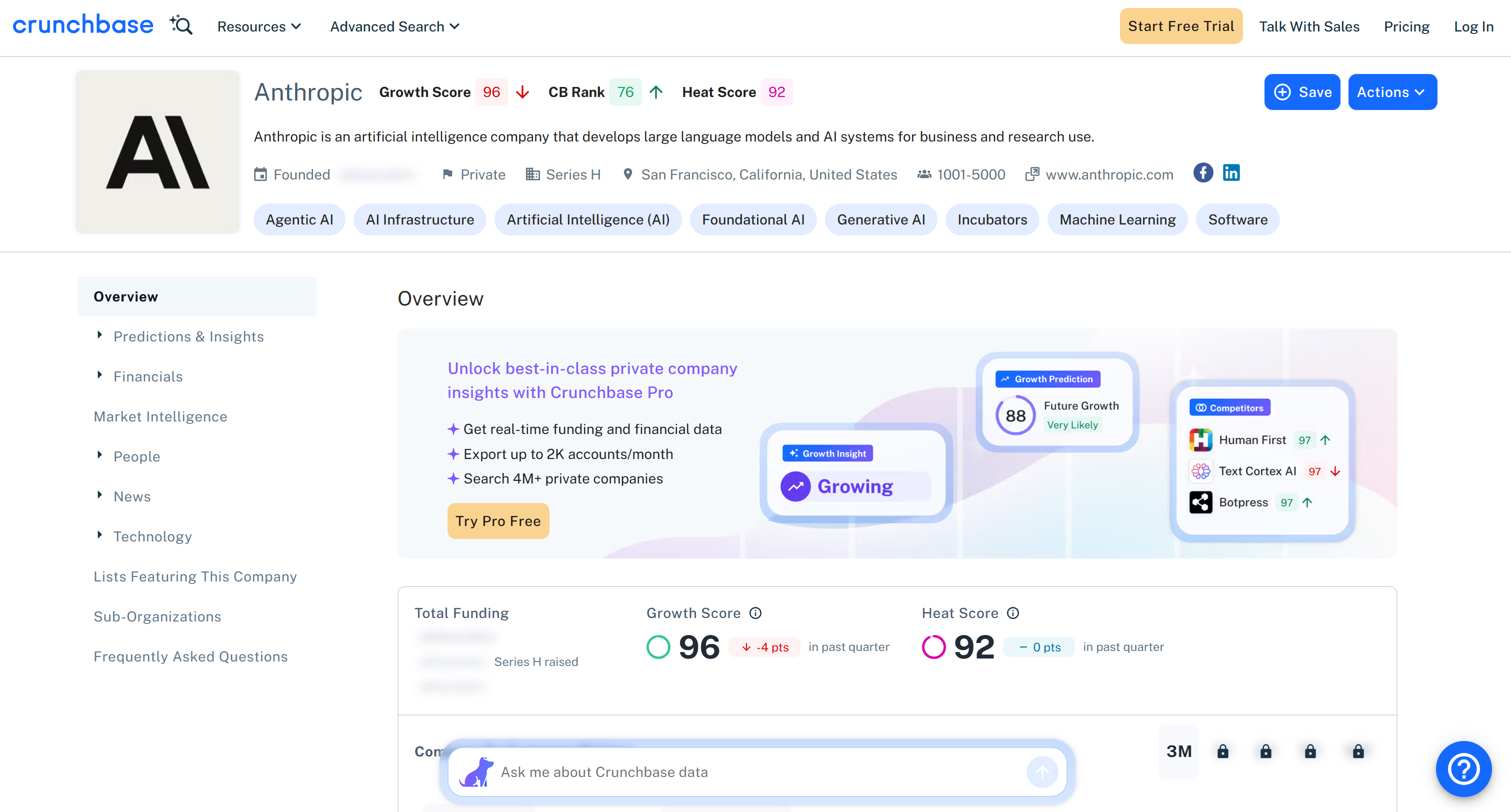
Ten en cuenta que toda la información devuelta por la API Scraper de Crunchbase de Bright Data coincide con el contenido de la página de destino. Esto se debe a que los datos se recuperan al instante mediante scraping web, por lo que siempre están actualizados.
¡Et voilà! Has recuperado datos con éxito usando la API de scraping web de Bright Data.
Próximos pasos
El capítulo anterior mostró un ejemplo simple de cómo llamar a una API de scraping web de Bright Data en Python. Sin embargo, las APIs de scraping web pueden hacer mucho más que eso. Gracias a ellas, puedes transmitir datos estructurados y actualizados directamente a tus aplicaciones, sistemas o flujos de trabajo de IA.
Para casos de uso de agentes de IA en particular, estas APIs actúan como una capa de fundamentación en vivo, alimentando continuamente contexto externo fresco a tus sistemas. Por ejemplo, puedes:
- Potenciar agentes de IA con datos web reales y actualizados para recuperación y razonamiento (por ejemplo, a través del Web MCP de Bright Data).
- Fundamentar las salidas de LLM con información en vivo de fuentes como Crunchbase, plataformas de comercio electrónico o redes sociales.
- Construir pipelines RAG en tiempo real donde los datos web extraídos se inyectan en prompts o bases de datos vectoriales.
- Apoyar agentes financieros o empresariales que dependen de precios actuales, actualizaciones de empresas, señales de mercado, etc.
En general, las APIs de scraping web de Bright Data son una capa de infraestructura central para construir sistemas dinámicos y conscientes de los datos que dependen de inteligencia web fresca.
Conjuntos de datos o APIs de scraping web: Tabla de comparación final
Compara los dos enfoques de recuperación de datos de un vistazo en la tabla comparativa de conjuntos de datos vs APIs de scraping web a continuación:
| Conjuntos de datos | APIs de scraping web | |
|---|---|---|
| Descripción | Colecciones de datos pre-recopiladas y estructuradas | APIs que extraen y devuelven datos web en vivo de sitios web de destino bajo demanda |
| Formatos de datos | CSV, JSON, Excel, Parquet, NDJSON, etc. | JSON, CSV |
| Frescura de los datos | Instantáneas estáticas o actualizadas periódicamente | Tiempo real |
| Modelo de actualización | Ciclos de actualización diarios, mensuales, trimestrales | Tiempo real |
| Escalabilidad | Miles de millones de registros | Alta, dependiendo de los límites de velocidad e infraestructura del proveedor de API |
| Infraestructura requerida | Ninguna (gestionada por el proveedor) | Ninguna (gestionada por el proveedor) |
| Cobertura | Amplia pero limitada por el alcance del conjunto de datos | Potencialmente cualquier sitio web o dominio |
| Complejidad para el usuario | Muy baja | Baja a media (se requiere integración de API) |
| Uso de IA | Principalmente para entrenamiento | Fundamentación en tiempo real y más (compatible con Web MCP) |
Elige conjuntos de datos cuando…
- Necesitas datos limpios y estructurados inmediatamente listos para análisis o entrenamiento de ML.
- Tu caso de uso se basa en información histórica o agregada, sin necesidad de actualizaciones en tiempo real.
- Prefieres evitar cualquier complejidad de ingeniería de datos o scraping.
- Quieres acceso rentable a datos curados a gran escala.
- Prefieres un flujo de trabajo orientado a lotes (descargar → almacenar → consultar).
Prefiere las APIs de scraping web cuando…
- Necesitas datos frescos y en tiempo real de la web.
- Tu sistema debe reaccionar a cambios o eventos en vivo (precios, noticias, actualizaciones de empresas, etc.).
- Estás construyendo agentes de IA que requieren fundamentación externa.
- Quieres datos web sin mantener una infraestructura de scraping internamente.
- Requieres extracción continua o repetida de datos en evolución.
Conjuntos de datos + APIs de scraping web: ¿Es posible?
Usar conjuntos de datos junto con APIs de scraping web no solo es posible, sino que a menudo es la configuración más práctica para los sistemas modernos de datos e IA.
Los conjuntos de datos te proporcionan instantáneas históricas limpias, estructuradas y listas para usar. Son perfectos cuando necesitas consistencia, repetibilidad y análisis a gran escala sin preocuparte por la infraestructura.
Por otro lado, las APIs de scraping web proporcionan datos frescos y bajo demanda directamente de la web. Son más adecuadas para aplicaciones en tiempo real y fuentes que cambian rápidamente.
En la práctica, los dos enfoques son muy complementarios. Un patrón común es comenzar con un conjunto de datos para definir el estado base de un dominio. Luego usar las APIs de scraping web para enriquecer o actualizar partes específicas de él. Esta combinación es especialmente útil en escenarios donde se requieren tanto conocimiento de fondo estable como contexto en vivo.
Para un ejemplo del mundo real sobre Crunchbase, consulta nuestro artículo “Filtra un conjunto de datos de Crunchbase y procésalo con IA para prospectar nuevos clientes“. Explica cómo construir un flujo de trabajo de prospección de clientes con IA filtrando primero un conjunto de datos de Crunchbase y luego usando APIs de scraping web para obtener sitios web de empresas en vivo y puntuar clientes potenciales con IA.
Conclusión
En esta publicación del blog, comprendiste lo que ofrecen los conjuntos de datos y las APIs de scraping web. Aprendiste que los conjuntos de datos son ideales para escenarios donde necesitas grandes volúmenes de datos estáticos y estructurados. En cambio, las APIs de scraping web son mejores cuando necesitas datos frescos recuperados directamente de la web.
En ambos casos, independientemente del enfoque que elijas, necesitas un proveedor de datos web confiable. Bright Data te apoya con:
- Marketplace de conjuntos de datos: Datos web públicos pre-construidos y filtrados de más de 350 dominios en JSON, CSV, Parquet y otros formatos. Te da acceso a una colección de más de 17 mil millones de registros de datos.
- APIs de scraping web: Una colección de más de 600 endpoints de scraping que automatizan la extracción de datos web en tiempo real en más de 250 dominios. Gestionan la rotación de IPs, los CAPTCHAs y los sistemas anti-bot, y devuelven datos estructurados sin sobrecarga de infraestructura.
¡Crea una cuenta de Bright Data hoy y prueba nuestras soluciones de datos web de forma gratuita!




