

En esta guía, verá:
- Qué es AG2 y cómo admite el desarrollo de sistemas de agente único y multiagente, así como las ventajas de ampliarlo con Bright Data.
- Los requisitos previos para empezar a utilizar esta integración.
- Cómo potenciar una arquitectura multiagente AG2 con Bright Data a través de herramientas personalizadas.
- Cómo conectar AG2 al Web MCP de Bright Data.
¡Empecemos!
Introducción a AG2 (antes AutoGen)
AG2 es un marco AgentOS de código abierto para crear agentes de IA y sistemas multiagente capaces de colaborar de forma autónoma para resolver tareas complejas. Permite crear flujos de trabajo de un solo agente, coordinar varios agentes especializados e integrar herramientas externas en procesos modulares listos para la producción.
AG2, anteriormente AutoGen, es una evolución de la biblioteca Microfost AutoGen. Conserva la arquitectura original y la compatibilidad con versiones anteriores, al tiempo que permite flujos de trabajo multiagente, integración de herramientas e IA con intervención humana. Escrito en Python, tiene más de 4000 estrellas en GitHub.
(Si buscas orientación sobre cómo integrar Bright Data con AutoGen, consulta la entrada del blog dedicada a este tema).
AG2 proporciona la flexibilidad y los patrones de orquestación avanzados necesarios para llevar los proyectos de IA agencial de la experimentación a la producción.
Algunas de sus características principales incluyen patrones de conversación multiagente, soporte humano en el bucle, integración de herramientas y gestión estructurada del flujo de trabajo. Su objetivo final es ayudarle a construir sistemas de IA sofisticados con una sobrecarga mínima.
A pesar de estas maravillosas capacidades, los agentes AG2 siguen enfrentándose a las limitaciones básicas del LLM: ¡conocimiento estático a partir de datos de entrenamiento y sin acceso nativo a la información web en tiempo real!
La integración de AG2 con un proveedor de datos web como Bright Data resuelve todos estos problemas. La conexión de los agentes AG2 a las API de Bright Data para el Scraping web, la búsqueda y la automatización del navegador permite obtener datos web estructurados en tiempo real, lo que aumenta su inteligencia, autonomía y utilidad práctica.
Requisitos previos
Para seguir esta guía, necesita:
- Python 3.10 o superior instalado en su máquina local.
- Una cuenta de Bright Data con la API Web Unlocker, la API SERP y una clave API configurada. (Este tutorial le guiará a través de todas las configuraciones necesarias).
- Una clave API de OpenAI (o una clave API de cualquier otro LLM compatible con AG2).
También es útil estar familiarizado con los productos y servicios de Bright Data, así como tener un conocimiento básico del funcionamiento del sistema de herramientas AG2.
Cómo integrar Bright Data en un flujo de trabajo multiagente de AG2
En esta sección paso a paso, creará un flujo de trabajo AG2 multiagente basado en los servicios de Bright Data. En concreto, un agente dedicado a la recuperación de datos web accederá a Web Unlocker y API SERP de Bright Data a través de funciones personalizadas de la herramienta AG2.
Este sistema multiagente identificará a los principales influencers en plataformas como Twitch en la industria alimentaria para apoyar la promoción de un nuevo tipo de hamburguesa. Este ejemplo demuestra cómo AG2 puede automatizar la recopilación de datos, producir informes comerciales estructurados y permitir la toma de decisiones informadas, todo ello sin esfuerzo manual.
¡Vea cómo implementarlo!
Paso n.º 1: Crear un proyecto AG2
Abra un terminal y cree una nueva carpeta para su proyecto AG2. Por ejemplo, llámela ag2-bright-data-agent:
mkdir ag2-bright-data-agentag2-bright-data-agent/ contendrá el código Python para implementar y orquestar agentes AG2 que se integran con las funciones de Bright Data.
A continuación, vaya al directorio del proyecto y cree un entorno virtual dentro de él:
cd ag2-bright-data-agent
python -m venv .venvAñada un nuevo archivo llamado agent.py a la raíz del proyecto. La estructura de su proyecto debería tener ahora este aspecto:
ag2-bright-data-agent/
├── .venv/
└── agent.py # <----El archivo agent.py contendrá la definición del agente AG2 y la lógica de orquestación.
Abra la carpeta del proyecto en su IDE de Python preferido, como Visual Studio Code con la extensión Python o PyCharm Community Edition.
Ahora, active el entorno virtual que acaba de crear. En Linux o macOS, ejecute:
source .venv/bin/activateDe forma equivalente, en Windows, ejecute:
.venv/Scripts/activateCon el entorno virtual activado, instala las dependencias PyPI necesarias:
pip install ag2[openai] requests python-dotenvEsta aplicación se basa en las siguientes bibliotecas:
ag2[openai]: para crear y coordinar flujos de trabajo de IA multiagente impulsados por modelos OpenAI.requests: para realizar solicitudes HTTP a los servicios de Bright Data a través de herramientas personalizadas.python-dotenv: para cargar los secretos necesarios desde las variables de entorno definidas en un archivo.env
¡Bien hecho! Ahora ya tienes un entorno Python listo para usar para el desarrollo de IA multiagente con AG2.
Paso n.º 2: Configurar la integración LLM
Los agentes AG2 que vas a crear en los siguientes pasos requieren un cerebro, que es proporcionado por un LLM. Cada agente puede utilizar su propia configuración LLM, pero para simplificar, conectaremos todos los agentes al mismo modelo OpenAI.
AG2 incluye un mecanismo integrado para cargar la configuración LLM desde un archivo de configuración dedicado. Para ello, añade el siguiente código a agent.py:
from autogen import LLMConfig
# Cargar la configuración LLM desde el archivo de lista de configuración de OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")Este código carga la configuración LLM desde un archivo llamado OAI_CONFIG_LIST.json. Cree este archivo en el directorio raíz de su proyecto:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json # <----
└── agent.pyAhora, rellene OAI_CONFIG_LIST.json con el siguiente contenido:
[
{
"model": "gpt-5-mini",
"api_key": "<YOUR_OPENAI_API_KEY>"
}
]Reemplaza el marcador de posición <YOUR_OPENAI_API_KEY> con tu clave API de OpenAI real. Esta configuración potencia tus agentes AG2 utilizando el modelo GPT-5 Mini, pero puedes cambiarlo por cualquier otro modelo OpenAI compatible si es necesario.
La variable llm_config se pasará a sus agentes y al coordinador de chat grupal. Eso les permite razonar, comunicarse y ejecutar tareas utilizando el LLM configurado. ¡Genial!
Paso n.º 3: gestionar la lectura de variables de entorno
Sus agentes AG2 ahora pueden conectarse a OpenAI, pero también necesitan acceder a otro servicio de terceros: Bright Data. Al igual que OpenAI, Bright Data autentica las solicitudes utilizando una clave API externa.
Para evitar riesgos de seguridad, nunca debe codificar las claves API directamente en su código. En su lugar, la mejor práctica es cargarlas desde variables de entorno. Esta es precisamente la razón por la que instaló python-dotenv anteriormente.
En primer lugar, importe python-dotenv en agent.py. Utilícelo para cargar variables de entorno desde un archivo .env utilizando la función load_dotenv():
from dotenv import load_dotenv
import os
# Cargar variables de entorno desde el archivo .env
load_dotenv()A continuación, añada un archivo .env al directorio raíz de su proyecto, que debe contener:
ag2-bright-data-agent/
├── .venv/
├── OAI_CONFIG_LIST.json
├── .env # <----
└── agent.pyDespués de añadir tus valores secretos al archivo .env, podrás acceder a ellos en el código utilizando os.getenv():
ENV_VALUE = os.getenv("ENV_NAME")¡Genial! Su script puede cargar de forma segura secretos de integración de terceros desde variables de entorno.
Paso n.º 4: Configurar los servicios de Bright Data
Como se anticipó en la introducción, el agente de datos web se conectará a la API SERP y a la API Web Unlocker de Bright Data para gestionar las búsquedas web y la recuperación de contenido de las páginas web. Juntos, estos servicios proporcionan al agente la capacidad de obtener datos web en tiempo real en una capa de recuperación de datos de estilo RAG.
Para interactuar con esos dos servicios, tendrás que definir dos herramientas AG2 personalizadas más adelante. Antes de hacerlo, debes configurar todo en tu cuenta de Bright Data.
Empiece por crear una cuenta de Bright Data, si aún no tiene una. De lo contrario, inicie sesión y acceda a su panel de control. Desde allí, navegue hasta la página «Proxies y scraping» y revise la tabla «Mis zonas», que enumera los servicios configurados en su perfil: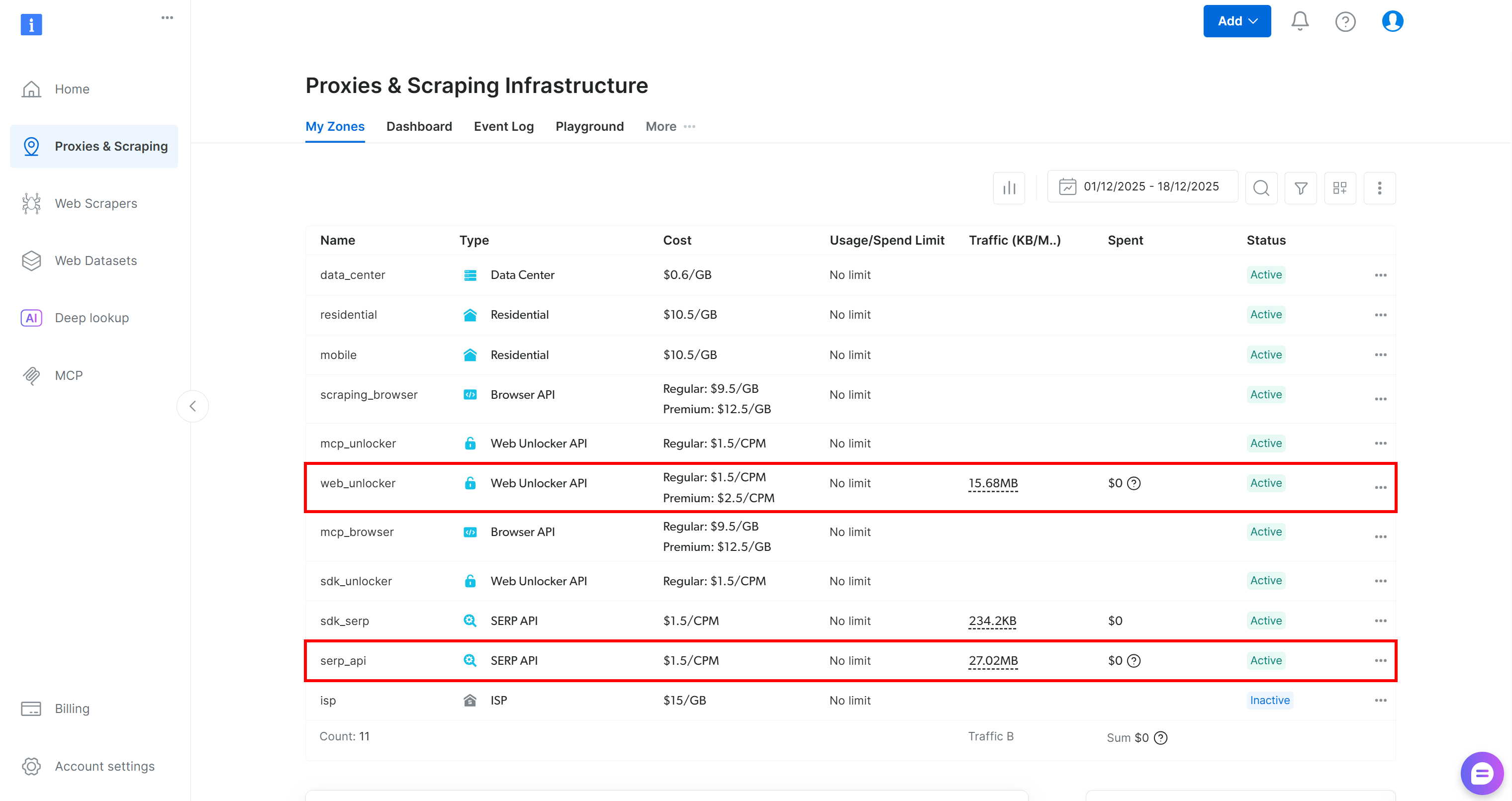
Si, como en el ejemplo anterior, la tabla ya incluye una zona Web Unlocker API (en este caso, llamada web_unlocker) y una zona API SERP (en este caso, llamada serp_api), entonces ya está todo listo. Estas dos zonas serán utilizadas por sus herramientas AG2 personalizadas para llamar a los servicios Bright Data necesarios.
Si falta una o ambas zonas, desplácese hacia abajo hasta las tarjetas «Unblocker API» y «API SERP» y haga clic en «Crear zona» para cada una de ellas. Siga el asistente de configuración para crear ambas zonas: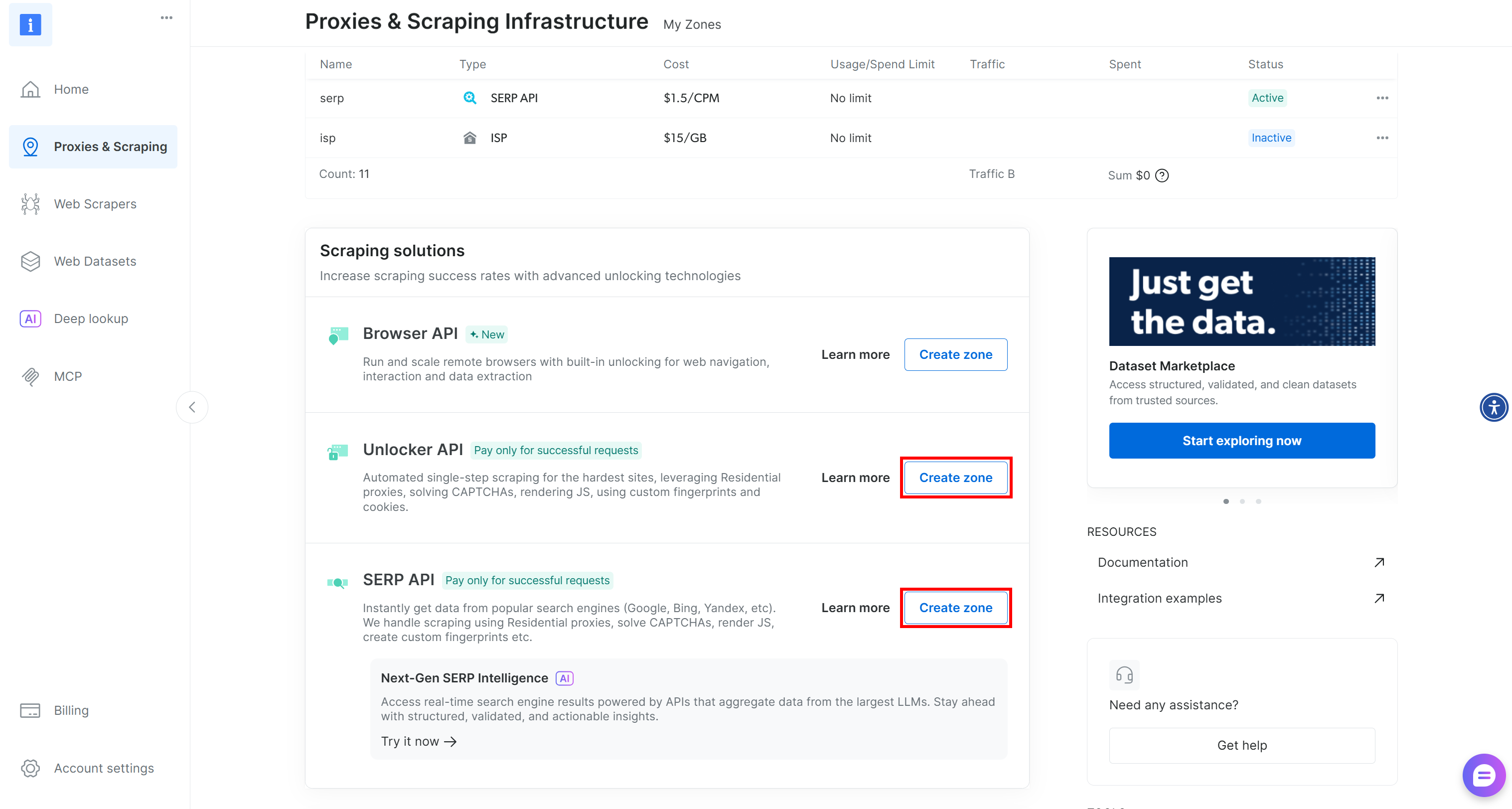
Para obtener instrucciones detalladas paso a paso, consulta la documentación oficial:
Importante: A partir de ahora, daremos por hecho que sus zonas se llaman serp_api y web_unlocker, respectivamente.
Una vez que sus zonas estén listas, genere su clave API de Bright Data. Guárdela como una variable de entorno en .env:
BRIGHT_DATA_API_KEY="<SU_CLAVE_DE_API_DE_BRIGHT_DATA>"A continuación, cárguela en agent.py como se muestra a continuación:
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")¡Perfecto! Ya tiene todos los elementos necesarios para conectar sus agentes AG2 a los servicios API SERP y Web Unlocker de Bright Data a través de herramientas personalizadas.
Paso n.º 5: Defina las herramientas de Bright Data para sus agentes AG2
En AG2, las herramientas proporcionan capacidades especializadas que los agentes pueden invocar para realizar acciones y tomar decisiones. En realidad, las herramientas son simplemente funciones Python personalizadas que AG2 expone a los agentes de forma estructurada.
En este paso, implementará dos funciones de herramienta en agent.py:
serp_api_tool(): se conecta a la API SERP de Bright Data para realizar búsquedas en Google.web_unlocker_api_tool(): se conecta a la API de Bright Data Web Unlocker para recuperar el contenido de la página web, eludiendo todos los sistemas antibots.
Ambas herramientas utilizan el cliente HTTP Requests Python para realizar solicitudes POST autenticadas a Bright Data según la documentación:
- Envía tu primera solicitud con la API SERP de Bright Data
- Envía tu primera solicitud con la API Web Unlocker de Bright Data
Para definir las dos funciones de la herramienta, añada el siguiente código a agent.py:
from typing import Annotated
import requests
import urllib.parse
def serp_api_tool(
query: Annotated[str, "La consulta de búsqueda de Google"],)
-> str:
payload = {
"zone": "serp_api", # Reemplázalo con el nombre de tu zona API SERP de Bright Data
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "URL de la página de destino que se va a recuperar"],
data_format: Annotated[
str | None,
"Formato de la página de salida (por ejemplo, 'markdown', u omitir para HTML sin formato)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Reemplácelo con el nombre de su zona Bright Data Web Unlocker
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.textLas dos herramientas autentican las solicitudes utilizando su clave API de Bright Data y envían solicitudes POST al punto final de la API de Bright Data:
serp_api_tool()consulta Google y recupera los resultados de búsqueda en formato JSON estructurado habilitando el parámetrobrd_json=1.web_unlocker_api_tool()recupera cualquier página web y devuelve su contenido en Markdown (o HTML sin formato, si se desea).
Importante: Tanto JSON como Markdown son formatos excelentes para la ingestión de LLM en agentes de IA.
Tenga en cuenta que ambas funciones utilizan tipado Python junto con Annotated para describir sus argumentos. Los tipos son necesarios para transformar estas funciones en herramientas AG2 adecuadas, mientras que las descripciones de las anotaciones ayudan al LLM a comprender cómo rellenar cada argumento al invocar las herramientas desde un agente.
¡Genial! Su aplicación AG2 ahora incluye dos herramientas de Bright Data, listas para ser configuradas y utilizadas por sus agentes de IA.
Paso n.º 6: Implementar los agentes AG2
Ahora que sus herramientas están en su lugar, es el momento de construir la estructura del agente de IA descrita en la introducción. Esta configuración consta de tres agentes complementarios:
user_proxy: actúa como capa de ejecución, ejecutando de forma segura las llamadas a las herramientas y coordinando el flujo de trabajo sin intervención humana. Es una instancia deUserProxyAgent, un agente AG2 especial que funciona como Proxy para el usuario, ejecutando código y proporcionando información a otros agentes según sea necesario.web_data_agent: responsable del descubrimiento y la recuperación de datos web. Este agente busca en la web utilizando la API SERP de Bright Data y recupera el contenido de la página a través de la API Web Unlocker. ComoConversableAgent, puede comunicarse con otros agentes y con humanos, procesar información, seguir las instrucciones definidas en su mensaje del sistema y mucho más.reporting_agent: Analiza los datos recopilados y los transforma en un informe Markdown estructurado y listo para su uso empresarial para los responsables de la toma de decisiones.
Juntos, estos agentes forman un canal multiagente totalmente autónomo diseñado para la identificación de streamers de Twitch y la promoción de un producto específico.
En agent.py, especifique los tres agentes con el siguiente código:
from autogen import (
UserProxyAgent,
ConversableAgent,)
# Ejecuta llamadas a herramientas y coordina el flujo de trabajo sin intervención humana.
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Responsable de buscar y recuperar datos web
web_data_agent = ConversableAgent(
name="web_data_agent",
code_execution_config=False,
llm_config=llm_config,
system_message=(
"""
Eres un agente de recuperación de datos web.
Buscas en la web utilizando la herramienta Bright Data API SERP
y recuperas el contenido de las páginas utilizando la herramienta Web Unlocker API.
"""
),
)
# Analiza los datos recopilados y elabora un informe estructurado.
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Eres un analista de marketing.
Elaboras informes Markdown estructurados y listos para su uso empresarial
destinados a los responsables de la toma de decisiones.
"""
),
llm_config=llm_config,
# Termina automáticamente la conversación cuando aparezca la palabra «informe».
is_termination_msg=lambda msg: "report" in (msg.get("content", "") or "").lower()
)En el código anterior, ten en cuenta que:
- Los agentes AG2 pueden ejecutar código contenido en mensajes (por ejemplo, bloques de código) y pasar los resultados al siguiente agente. En esta configuración, la ejecución de código está desactivada mediante
code_execution_config=Falsepor motivos de seguridad. - Todos los agentes funcionan con
llm_configcargado en el paso n.º 2. - El
reporting_agentincluye una funciónis_termination_msgpara finalizar automáticamente el flujo de trabajo una vez que el mensaje contiene la palabra «report», lo que indica que se ha producido el resultado final.
A continuación, registrará las herramientas de Bright Data con el agente web_data_agent para habilitar la recuperación web.
Paso n.º 7: Registrar las herramientas AG2 Bright Data
Registre las funciones de Bright Data como herramientas y asígnelas al web_data_agent a través de register_function(). El agente user_proxy actuará como ejecutor de estas herramientas, tal y como requiere la arquitectura de AG2:
from autogen import register_function
# Registrar la herramienta de búsqueda SERP para el agente de datos web
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Utilizar la API SERP de Bright Data para realizar una búsqueda en Google y devolver los resultados sin procesar."
)
# Registrar la herramienta Web Unlocker para obtener páginas protegidas
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Obtener una página web utilizando la API Web Unlocker de Bright Data, eludiendo las protecciones anti-bot habituales.",
)Tenga en cuenta que cada función incluye una descripción concisa para ayudar al LLM a comprender su propósito y saber cuándo llamarla.
Con estas herramientas registradas, web_data_agent ahora puede planificar búsquedas web y acceso a páginas web, mientras que user_proxy se encarga de la ejecución.
Su canalización multiagente AG2 ahora es totalmente capaz de descubrir y extraer datos de forma autónoma utilizando las API de Bright Data. ¡Misión cumplida!
Paso n.º 8: Introducir la lógica de orquestación multiagente AG2
AG2 admite varias formas de orquestar y gestionar múltiples agentes. En este ejemplo, verá el patrón GroupChat.
La esencia de un chat grupal AG2 es que todos los agentes contribuyen a un único hilo de conversación, compartiendo el mismo contexto. Este enfoque es ideal para tareas que requieren la colaboración entre varios agentes, como en nuestro canal.
A continuación, un GroupChatManager se encarga de la coordinación de los agentes dentro del chat grupal. Admite diferentes estrategias para seleccionar el siguiente agente que actuará. Aquí, configurará la estrategia automática predeterminada, que aprovecha el LLM del administrador para decidir qué agente debe hablar a continuación.
Combine todo para la orquestación multiagente como se muestra a continuación:
from autogen import (
GroupChat,
GroupChatManager,)
# Definir el chat grupal multiagente
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Gestor responsable de coordinar las interacciones de los agentes
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config
)Nota: El flujo de trabajo finalizará cuando el reporting_agent genere un mensaje que active su lógica is_termination_msg o después de 20 rondas de interacciones entre los agentes (debido al argumento max_round ), lo que ocurra primero.
¡Ya está! Las definiciones de los agentes y la lógica de orquestación están completas. El último paso es iniciar el flujo de trabajo y exportar los resultados.
Paso n.º 9: Iniciar el flujo de trabajo de Agentic y exportar el resultado
Describa la tarea de búsqueda de influencers en Twitch Streamer en detalle y pásela como un mensaje al agente user_proxy para su ejecución:
prompt_message = """
Escenario:
---------
Una marca de alimentos y bebidas quiere promocionar un nuevo tipo de hamburguesa.
Objetivo:
- Buscar la página de la categoría Alimentos y bebidas en TwitchMetrics
- Obtener el contenido de la página de la categoría TwitchMetrics recuperada de la SERP y seleccionar los 5 streamers principales
- Visitar la página de perfil de TwitchMetrics de cada streamer y recuperar la información relevante.
- Elaborar un informe Markdown estructurado que incluya:
- Nombre del canal.
- Alcance estimado.
- Enfoque del contenido.
- Adecuación de la audiencia.
- Viabilidad de la difusión de la marca.
"""
# Iniciar el flujo de trabajo multiagente.
user_proxy.initiate_chat(recipient=manager, message=prompt_message)Una vez finalizado el flujo de trabajo, guarda el resultado (es decir, el informe Markdown) en el disco con:
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])¡Increíble! Su flujo de trabajo multiagente AG2 + Bright Data ya está completamente operativo y listo para recopilar, analizar y generar informes sobre los datos de los influencers de Twitch.
Paso n.º 10: Ponlo todo junto
El código final en su archivo agent.py será:
from autogen import (
LLMConfig,
UserProxyAgent,
ConversableAgent,
register_function,
GroupChat,
GroupChatManager,)
from dotenv import load_dotenv
import os
from typing import Annotated
import requests
import urllib.parse
# Cargar la configuración LLM desde el archivo de lista de configuración de OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Cargar las variables de entorno desde el archivo .env
load_dotenv()
# Recuperar la clave API de Bright Data desde las variables de entorno
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Definir las funciones para implementar las herramientas de Bright Data
def serp_api_tool(
query: Annotated[str, "La consulta de búsqueda de Google"],)
-> str:
payload = {
"zone": "serp_api", # Reemplazarlo con el nombre de la zona de la API SERP de Bright Data
"url": f"https://www.google.com/search?q={urllib.parse.quote_plus(query)}&brd_json=1",
"format": "raw",
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers,
)
response.raise_for_status()
return response.text
def web_unlocker_api_tool(
url_to_fetch: Annotated[str, "URL de la página de destino que se va a recuperar"],
data_format: Annotated[
str | None,
"Formato de la página de salida (por ejemplo, 'markdown', u omitir para HTML sin formato)"
] = "markdown",)
-> str:
payload = {
"zone": "web_unlocker", # Reemplácelo con el nombre de su zona Bright Data Web Unlocker
"url": url_to_fetch,
"format": "raw",
"data_format": data_format,
}
headers = {
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}",
"Content-Type": "application/json",
}
response = requests.post(
"https://api.brightdata.com/request",
json=payload,
headers=headers
)
response.raise_for_status()
return response.text
# Ejecuta llamadas a herramientas y coordina el flujo de trabajo sin intervención humana.
user_proxy = UserProxyAgent(
name="user_proxy",
code_execution_config=False,
human_input_mode="NEVER",
llm_config=llm_config,
)
# Responsable de buscar y recuperar datos web
agente_datos_web = ConversableAgent(
nombre="agente_datos_web",
configuración_ejecución_código=False,
configuración_llm=configuración_llm,
mensaje_sistema=(
"""
Eres un agente de recuperación de datos web.
Buscas en la web utilizando la herramienta Bright Data API SERP
y recuperas el contenido de las páginas utilizando la herramienta Web Unlocker API.
"""
),
)
# Analiza los datos recopilados y elabora un informe estructurado.
reporting_agent = ConversableAgent(
name="reporting_agent",
code_execution_config=False,
system_message=(
"""
Eres un analista de marketing.
Elaboras informes Markdown estructurados y listos para su uso empresarial
destinados a los responsables de la toma de decisiones.
"""
),
llm_config=llm_config,
# Termina automáticamente la conversación una vez que aparece la palabra «informe».
is_termination_msg=lambda msg: «informe» en (msg.get(«content», «») o «»).lower()
)
# Registrar la herramienta de búsqueda SERP para el agente de datos web.
register_function(
serp_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Utilizar la API SERP de Bright Data para realizar una búsqueda en Google y devolver los resultados sin procesar."
)
# Registrar la herramienta Web Unlocker para obtener páginas protegidas.
register_function(
web_unlocker_api_tool,
caller=web_data_agent,
executor=user_proxy,
description="Obtener una página web utilizando la API Web Unlocker de Bright Data, eludiendo las protecciones anti-bot habituales.",
)
# Definir el chat grupal multiagente
groupchat = GroupChat(
agents=[user_proxy, web_data_agent, reporting_agent],
speaker_selection_method="auto",
messages=[],
max_round=20
)
# Gestor responsable de coordinar las interacciones de los agentes
manager = GroupChatManager(
name="group_manager",
groupchat=groupchat,
llm_config=llm_config)
prompt_message = """
Escenario:
---------
Una marca de alimentos y bebidas quiere promocionar un nuevo tipo de hamburguesa.
Objetivo:
- Buscar la página de la categoría Comida y bebida en TwitchMetrics
- Obtener el contenido de la página de la categoría TwitchMetrics recuperada de la SERP y seleccionar los 5 streamers principales
- Visitar la página de perfil de TwitchMetrics de cada streamer y recuperar la información relevante.
- Elaborar un informe Markdown estructurado que incluya:
- Nombre del canal.
- Alcance estimado.
- Enfoque del contenido.
- Adecuación de la audiencia.
- Viabilidad de la difusión de la marca.
"""
# Iniciar el flujo de trabajo multiagente.
user_proxy.initiate_chat(recipient=manager, message=prompt_message)
# Guarda el informe final en un archivo Markdown
with open("report.md", "w", encoding="utf-8") as f:
f.write(user_proxy.last_message()["content"])Gracias a la potente API AG2, con solo unas 170 líneas de código, ¡ha creado un flujo de trabajo multiagente complejo, listo para empresas y basado en Bright Data!
Paso n.º 11: Prueba el sistema multiagente
En tu terminal, comprueba que tu aplicación de agente AG2 funciona con:
python agent.pyEl resultado esperado será similar a este: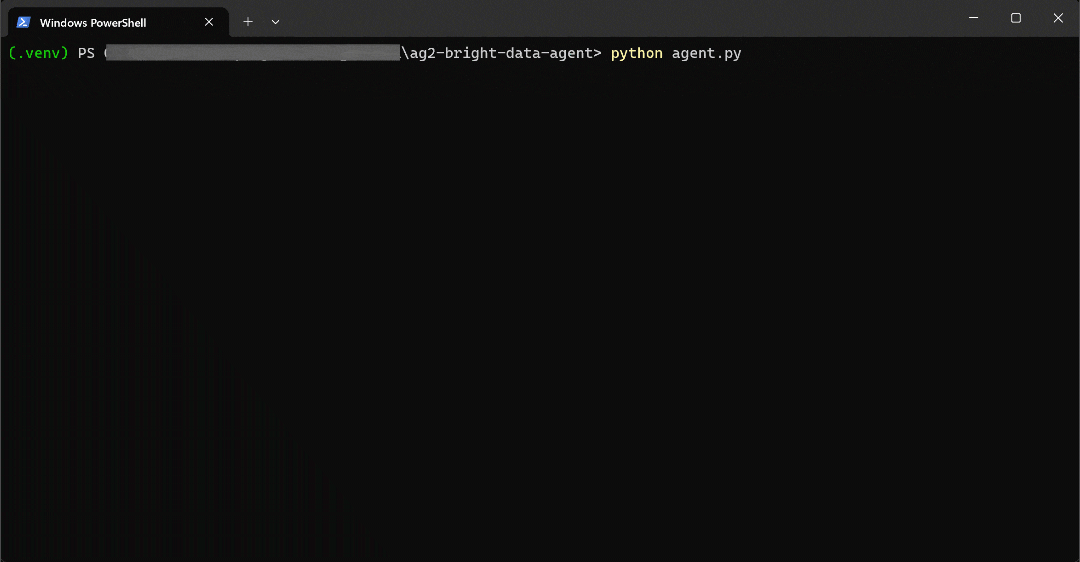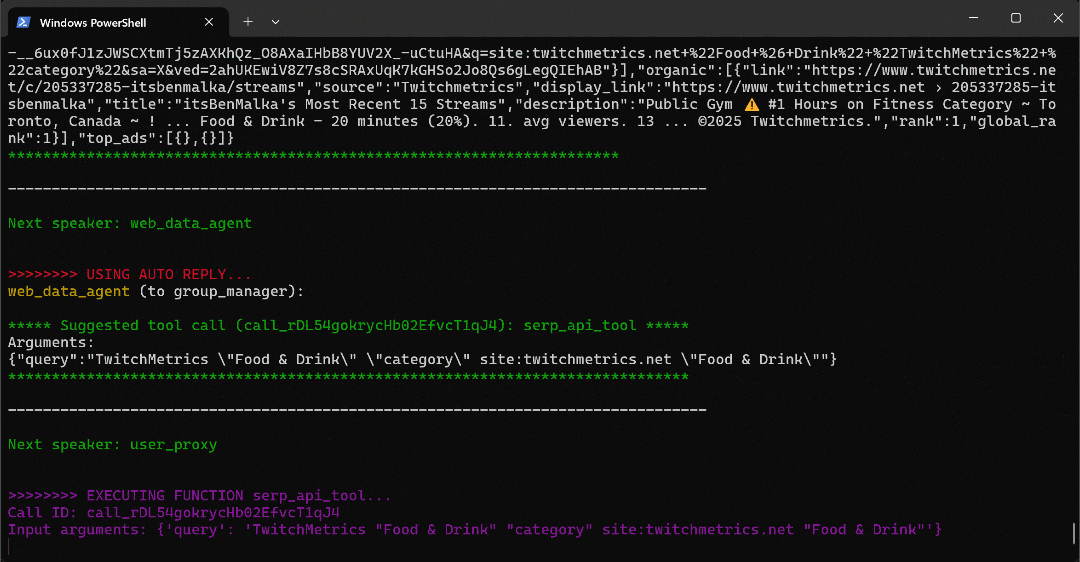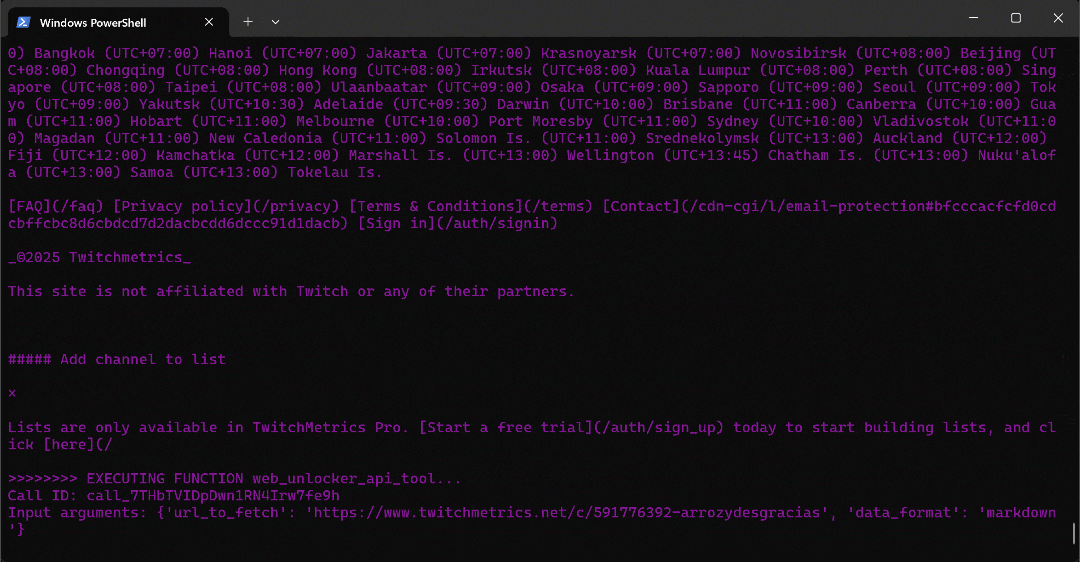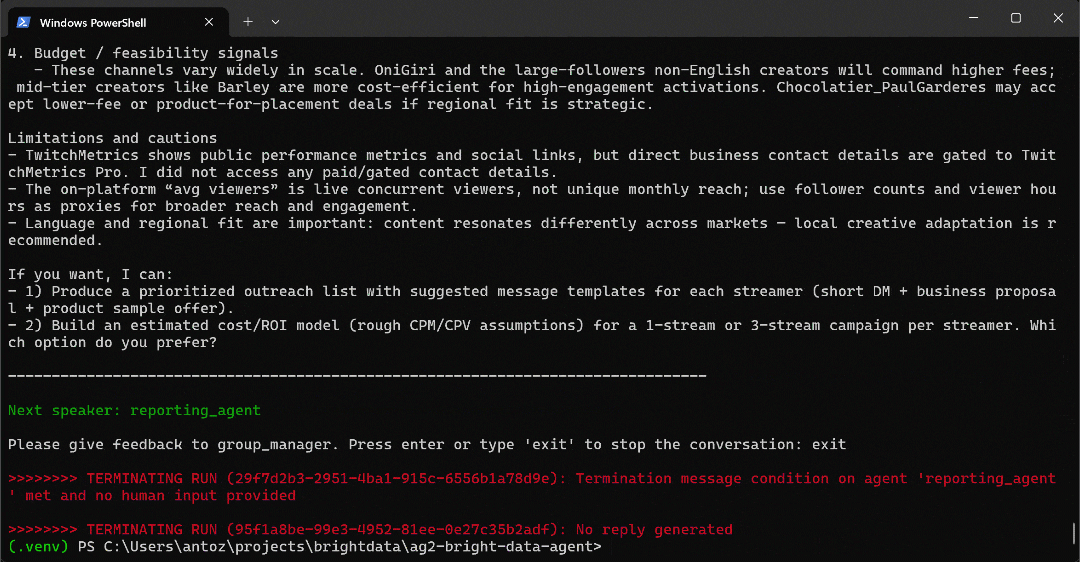
En detalle, observa cómo avanza paso a paso el flujo de trabajo multiagente:
- El agente
web_data_agentdetermina que necesita llamar a la herramientaserp_api_toolpara localizar la página de la categoría «Comida y bebida» de TwitchMetrics. - A través del agente
user_proxy, la herramienta ejecuta varias consultas de búsqueda. - Una vez identificada la página de categoría correcta de TwitchMetrics, llama a la herramienta
web_unlocker_api_toolpara extraer el contenido en formato Markdown. - A partir de la salida de Markdown, extrae las URL de los 5 perfiles de TwitchMetrics más influyentes en la categoría «Comida y bebida».
- Se vuelve a llamar a la herramienta
web_unlocker_api_toolpara recuperar el contenido de la página de cada perfil en Markdown. - Todos los datos recopilados se pasan al
reporting_agent, que los analiza y genera el informe final.
Este informe final se guarda en el disco como report.md, tal y como se especifica en el código:
Véalo en VS Code utilizando la vista previa de Markdown para comprobar lo detallado y rico en información que es el informe: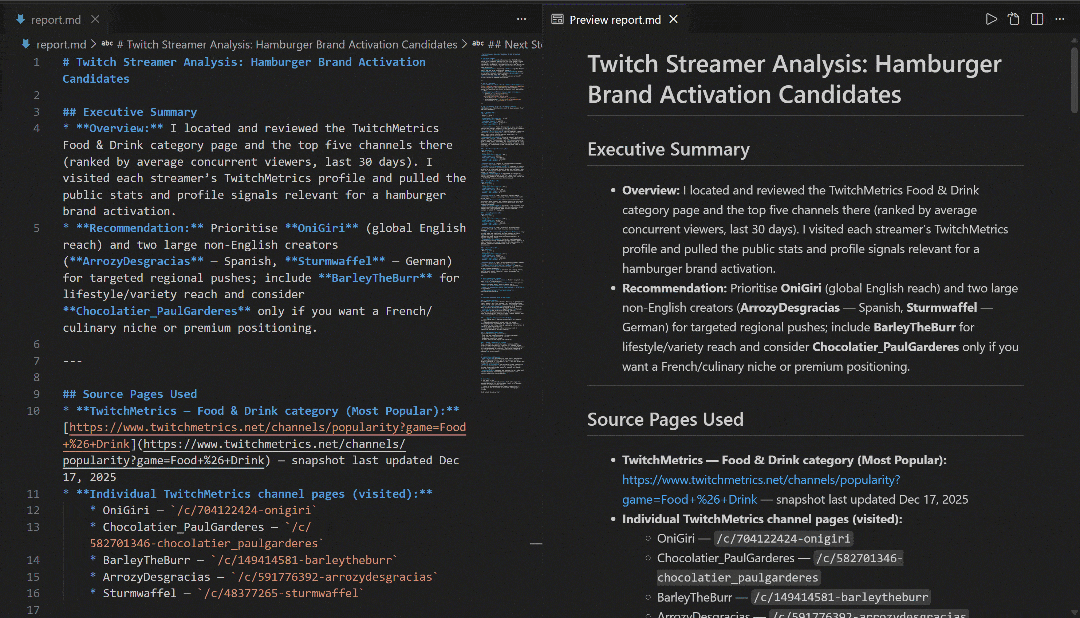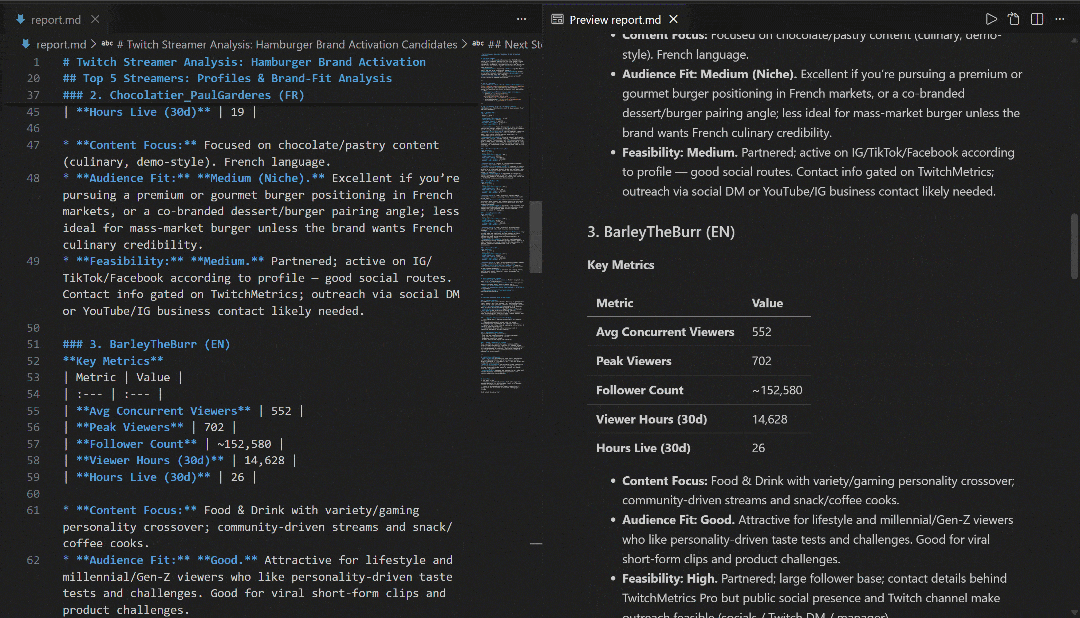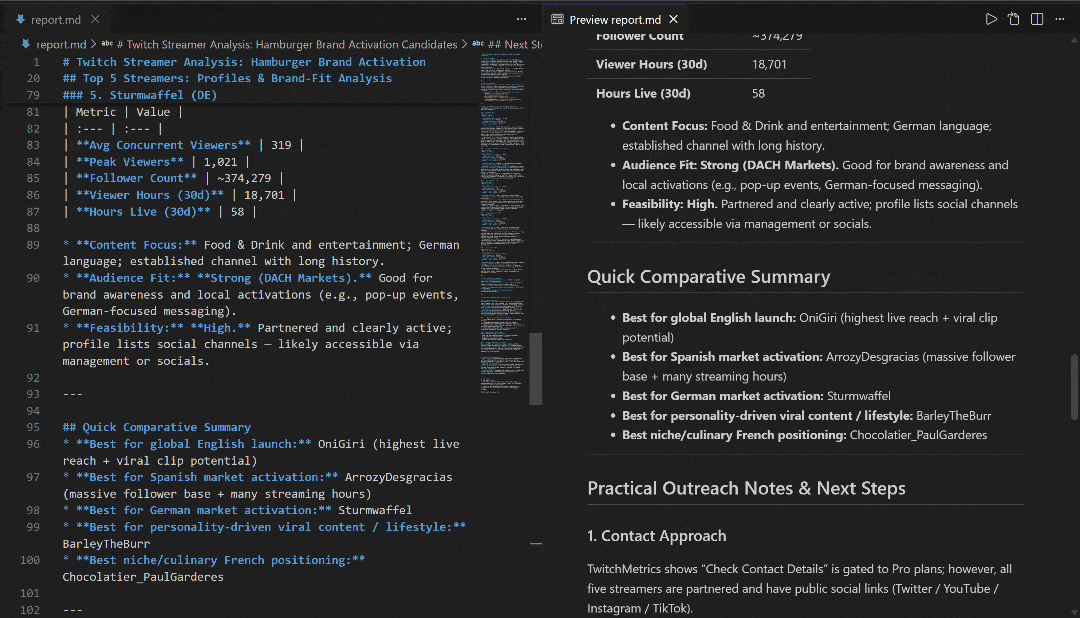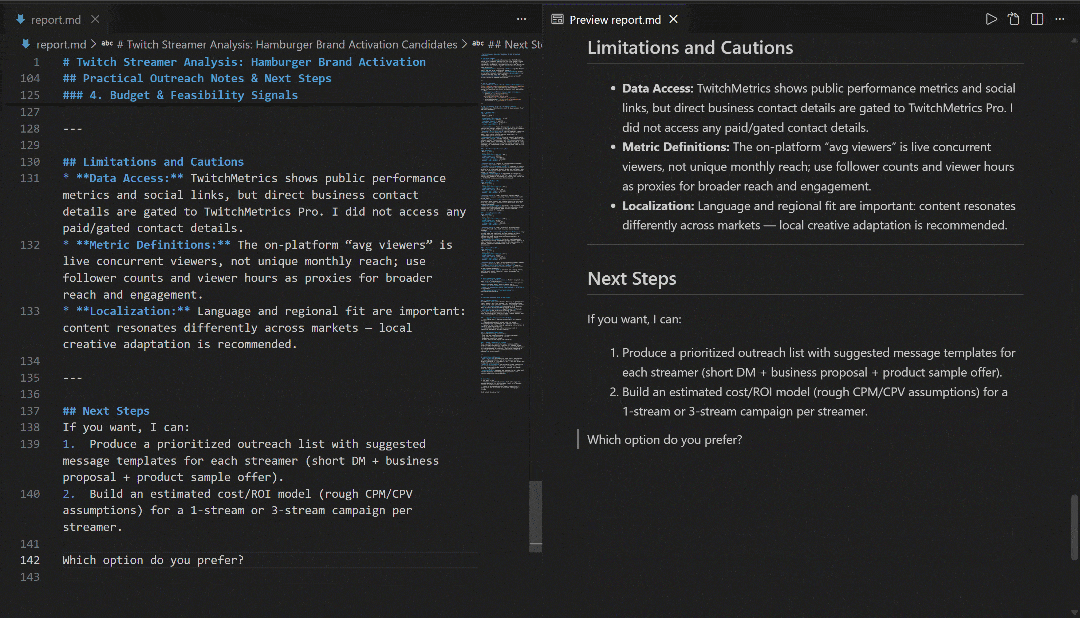
Si te preguntas de dónde provienen los datos de origen, consulta la página de la categoría de transmisiones de Twitch «Comida y bebida» en TwitchMetrics: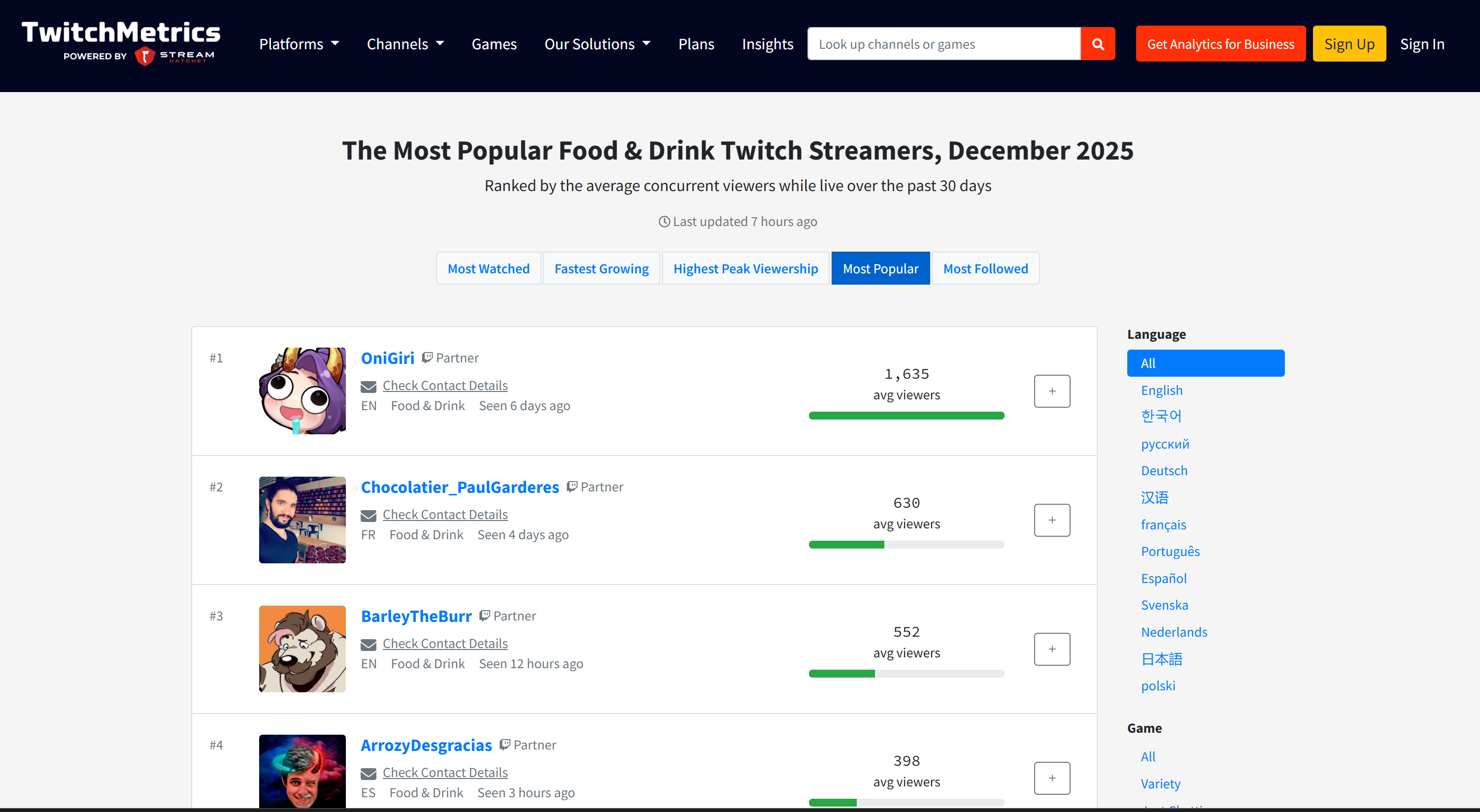
Tenga en cuenta que la información de los streamers de Twitch que aparece en el informe coincide con las páginas de perfil dedicadas de TwitchMetrics para cada uno de los 5 perfiles principales: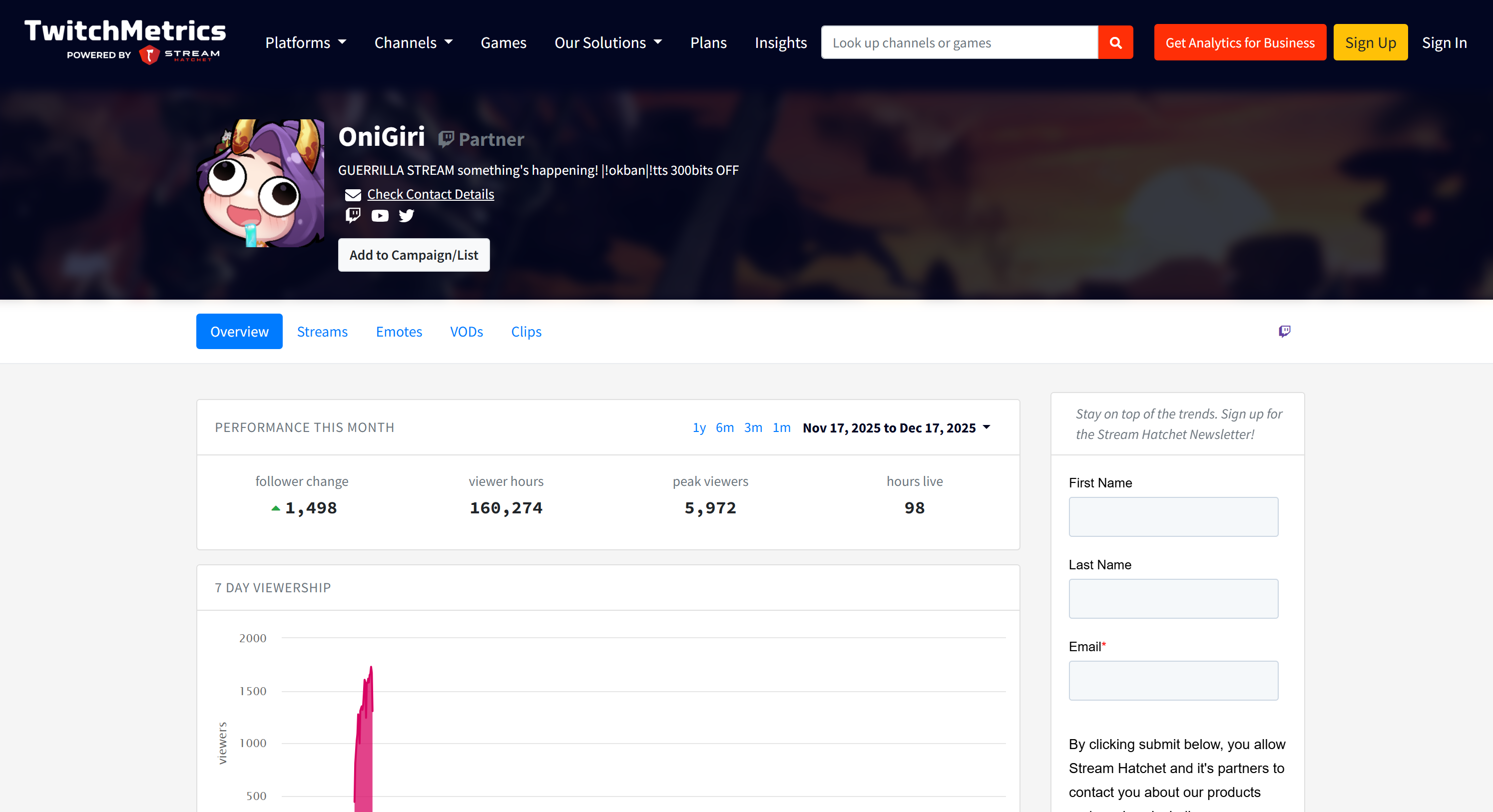
Toda esa información fue recuperada automáticamente por el sistema multiagente, lo que demuestra la potencia de AG2 y su integración con Bright Data.
Ahora, no dude en experimentar con diferentes indicaciones de entrada. Gracias a Bright Data, su flujo de trabajo multiagente AG2 puede manejar una variedad de tareas del mundo real.
¡Et voilà! Acaba de ser testigo de las capacidades de un flujo de trabajo AG2 mejorado con Bright Data
Conectar AG2 a Bright Data Web MCP: una guía paso a paso
Otra forma de integrar Bright Data en AG2 es a través del servidor Bright Data Web MCP.
Web MCP le da acceso a más de 60 herramientas creadas sobre la plataforma de automatización web y recopilación de datos de Bright Data. Incluso en el nivel gratuito, ofrece dos potentes herramientas:
| Herramienta | Descripción |
|---|---|
search_engine |
Obtiene resultados de Google, Bing o Yandex en formato JSON o Markdown. |
scrape_as_markdown |
Extrae cualquier página web en Markdown limpio, evitando las medidas anti-bot. |
El modo Pro de Web MCP lleva la funcionalidad aún más lejos. Esta opción premium desbloquea la extracción de datos estructurados para las principales plataformas, como Amazon, LinkedIn, Instagram, Reddit, YouTube, TikTok, Google Maps y muchas más. También añade herramientas para la automatización avanzada del navegador.
Nota: Para configurar el proyecto, consulta el paso n.º 1 del capítulo anterior.
A continuación, veamos cómo utilizar Web MCP de Bright Data dentro de AG2.
Requisitos
Para seguir esta sección del tutorial, necesita tener Node.js instalado localmente, ya que es necesario para ejecutar Web MCP en su máquina.
También debe instalar el paquete MCP para AG2 con:
pip install ag2[mcp]Esto permite que AG2 actúe como un cliente MCP.
Paso n.º 1: Empiece a utilizar Web MCP de Bright Data
Antes de conectar AG2 a Web MCP de Bright Data, asegúrate de que tu máquina local puede ejecutar el servidor MCP. Esto es importante porque se te mostrará cómo conectarte al servidor Web MCP localmente.
Nota: Web MCP también está disponible como servidor remoto a través de Streamable HTTP, que es más adecuado para casos de uso de nivel empresarial gracias a su escalabilidad ilimitada.
En primer lugar, asegúrese de que tiene una cuenta de Bright Data. Si ya la tiene, simplemente inicie sesión. Para una configuración rápida, siga las instrucciones de la sección«MCP»de su panel de control:
Para obtener más ayuda, consulte los pasos que se indican a continuación.
Comience por generar su clave API de Bright Data. Guárdela en un lugar seguro, ya que la utilizará en breve para autenticar su instancia local de Web MCP.
A continuación, instale Web MCP globalmente en su máquina utilizando el paquete @brightdata/mcp:
npm install -g @brightdata/mcpInicie el servidor MCP ejecutando:
API_TOKEN="<YOUR_BRIGHT_DATA_API>" npx -y @brightdata/mcpO, de forma equivalente, en PowerShell:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; npx -y @brightdata/mcpReemplace <YOUR_BRIGHT_DATA_API> con su token API de Bright Data. Estos comandos establecen la variable de entorno API_TOKEN necesaria e inician el servidor MCP web localmente.
Si se ejecutan correctamente, debería ver un resultado similar a este:
De forma predeterminada, Web MCP crea dos zonas en su cuenta de Bright Data al iniciarse por primera vez:
mcp_unlocker: una zona para Web Unlocker.mcp_browser: una zona para Browser API.
Estas zonas alimentan las más de 60 herramientas disponibles en Web MCP.
Puede verificar que las zonas se han creado visitando «Proxies e Infraestructura de scraping» en su panel de control de Bright Data: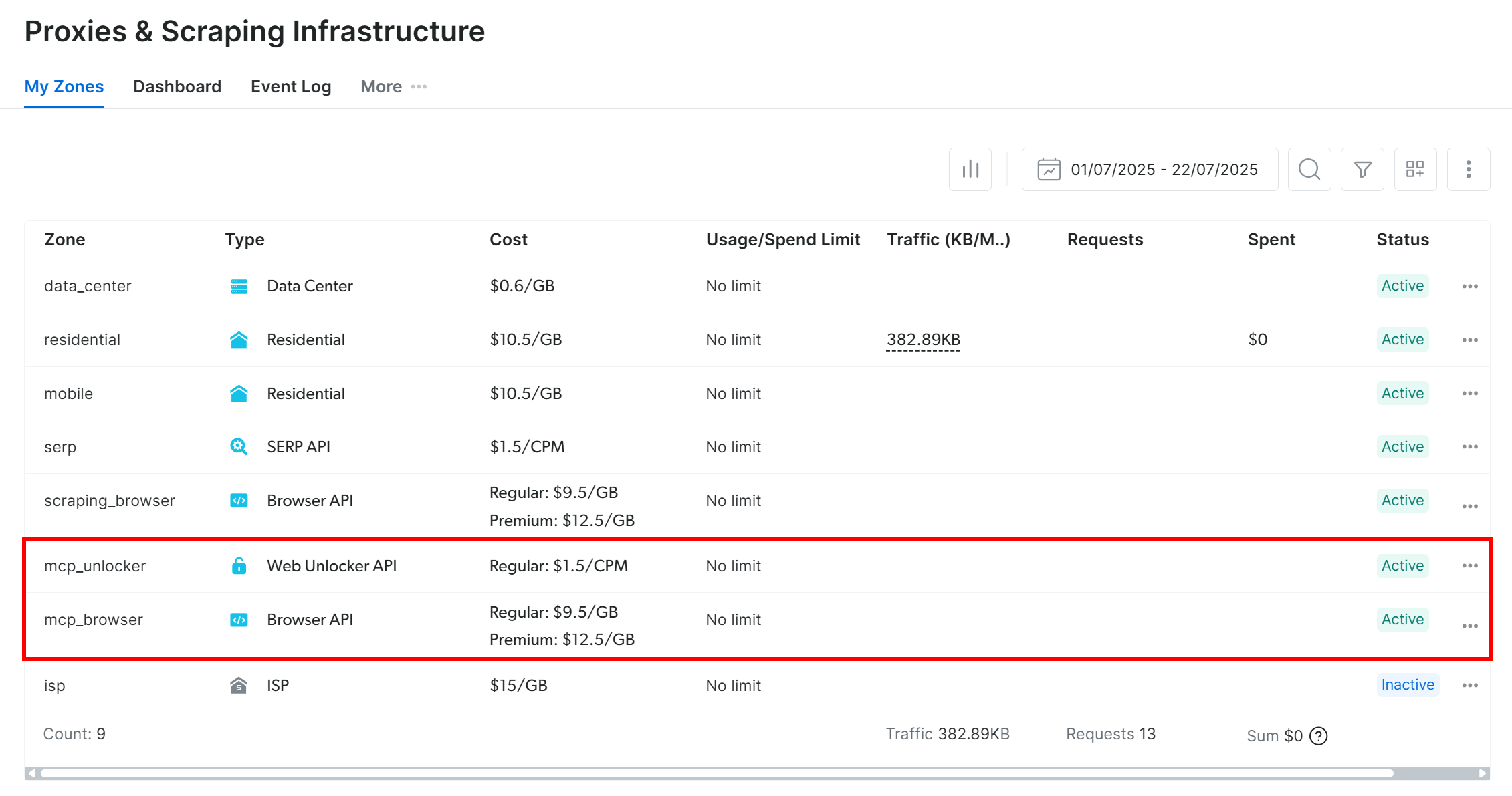
En el nivel gratuito de Web MCP, solo están disponibles las herramientas search_engine y scrape_as_markdown (y sus versiones por lotes).
Para desbloquear todas las herramientas, habilite el modo Pro configurando la variable de entorno PRO_MODE="true":
API_TOKEN="<YOUR_BRIGHT_DATA_API>" PRO_MODE="true" npx -y @brightdata/mcpO, en Windows:
$Env:API_TOKEN="<YOUR_BRIGHT_DATA_API>"; $Env:PRO_MODE="true"; npx -y @brightdata/mcpEl modo Pro desbloquea las más de 60 herramientas, pero no está incluido en el nivel gratuito y puede incurrir en cargos adicionales.
¡Listo! Ya ha verificado que el servidor Web MCP se ejecuta localmente. Detenga el proceso MCP por ahora, ya que el siguiente paso es configurar AG2 para iniciar el servidor localmente y conectarse a él.
Paso n.º 2: Integración de Web MCP en AG2
Utilice el cliente AG2 MCP para conectarse a una instancia local de Web MCP a través de STDIO y recuperar las herramientas disponibles:
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Instrucciones para conectarse a una instancia local de Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Opcional
},)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# Crear una sesión de conexión MCP y recuperar las herramientas
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)El objeto StdioServerParameters refleja el comando npx que ejecutaste anteriormente, incluidas las variables de entorno para las credenciales y la configuración:
API_TOKEN: Obligatorio. Establezca su clave API de Bright Data.PRO_MODE: Opcional. Elimínelo si desea permanecer en el nivel gratuito (solosearch_engineyscrape_as_markdowny sus versiones por lotes).
La sesión se utiliza para conectarse a Web MCP y crear un kit de herramientas AG2 MCP utilizando create_toolkit.
Nota: Como se destaca en un tema específico de GitHub, la opción use_mcp_resources=False es necesaria para evitar el error mcp.shared.exceptions.McpError: Método no encontrado.
Una vez creado, el objeto web_mcp_toolkit contiene todas las herramientas de Web MCP. Compruébelo con:
for tool in web_mcp_toolkit.tools:
print(tool.name)
print(tool.description)
print("---n")El resultado será: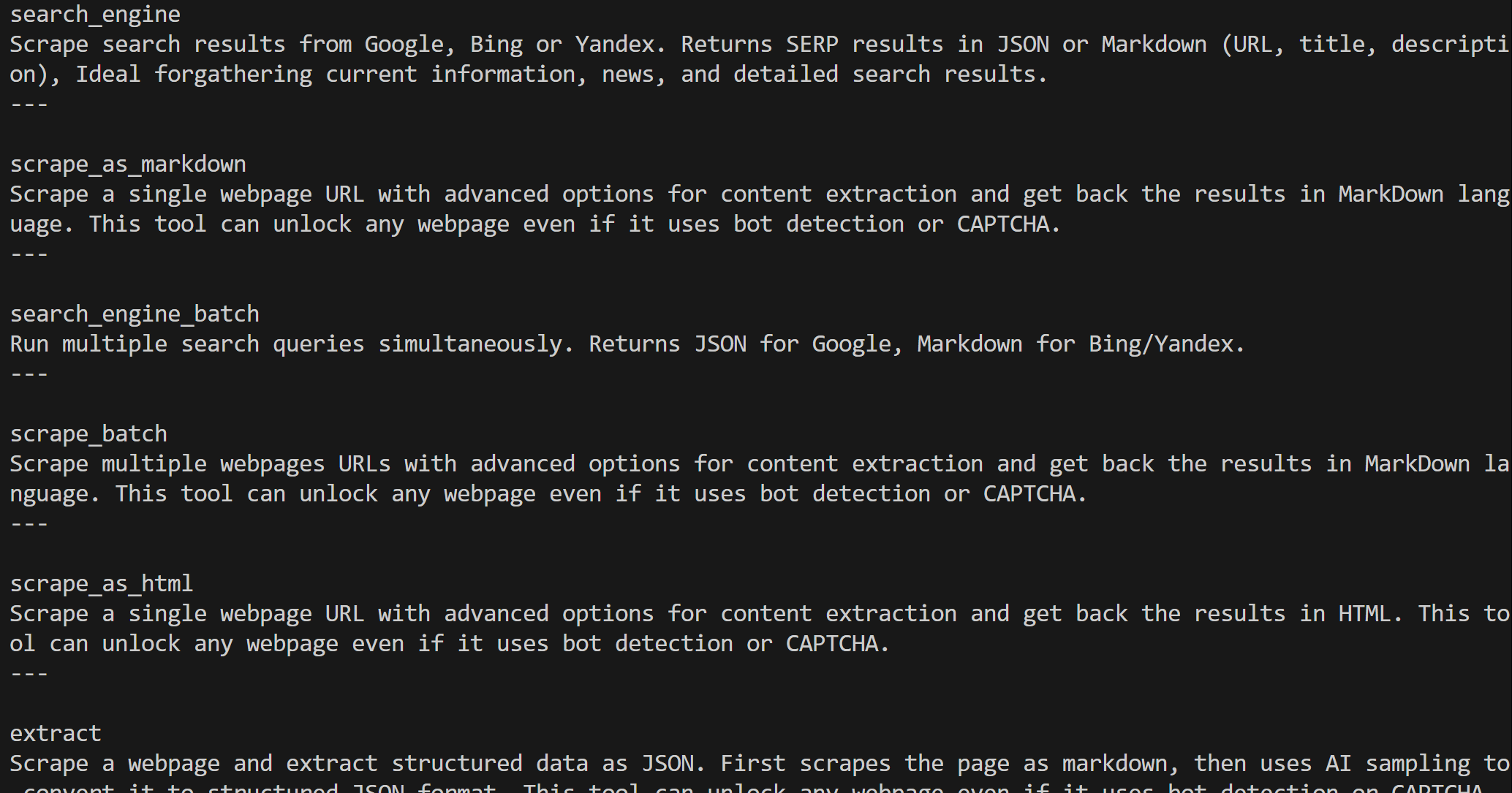
Dependiendo del nivel configurado, dispondrá de las más de 60 herramientas Web MCP (modo Pro) o solo de las herramientas del nivel gratuito.
¡Excelente! Su conexión Web MCP ya es totalmente funcional en AG2.
Paso n.º 3: conectar las herramientas Web MCP a un agente
La forma más sencilla de probar la integración de Web MCP en AG2 es a través de AssistantAgent, una subclase de ConversableAgent diseñada para resolver rápidamente tareas utilizando el LLM. En primer lugar, defina el agente y registre el kit de herramientas Web MCP con él:
from autogen import AssistantAgent
# Defina un agente capaz de buscar y recuperar datos web.
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Tiene acceso a todas las herramientas expuestas por Web MCP, incluyendo:
- Búsqueda web
- Scraping web y obtención de páginas
- Fuentes de datos web
- Simulación de usuario basada en navegador
Utilice estas herramientas cuando sea necesario.
""")
# Registrar las herramientas Web MCP con el agente
web_mcp_toolkit.register_for_llm(assistant_agent)Una vez registrado, puede iniciar el agente utilizando la función a_run() y especificar directamente las herramientas que desea utilizar. Por ejemplo, a continuación se muestra cómo probar el agente en una tarea de Scraping web de Amazon:
prompt = """
Recupera los datos del siguiente producto de Amazon y elabora un resumen rápido con la información principal:
"""
# Ejecutar el agente ampliado con Web MCP de forma asíncrona
result = await assistant_agent.a_run(
message=prompt,
tools=web_mcp_toolkit.tools,
user_input=False,)
await result.process()Importante: Ten en cuenta que esto es solo una demostración para mostrar la integración. Gracias a todas las herramientas Web MCP, el agente puede manejar tareas mucho más complejas y de varios pasos en diferentes plataformas web y fuentes de datos.
Paso n.º 4: Código final + Ejecución
A continuación se muestra el código final para la integración de AG2 + Bright Data Web MCP:
import asyncio
from autogen import (
LLMConfig,
AssistantAgent,)
from dotenv import load_dotenv
import os
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from autogen.mcp import create_toolkit
# Cargar variables de entorno desde el archivo .env
load_dotenv()
# Recuperar la clave API de Bright Data desde las variables de entorno
BRIGHT_DATA_API_KEY = os.getenv("BRIGHT_DATA_API_KEY")
# Definir el kit de herramientas MCP que contiene todas las herramientas Web MCP
async def launch_mcp_agent():
# Cargar la configuración LLM desde el archivo de lista de configuración de OpenAI
llm_config = LLMConfig.from_json(path="OAI_CONFIG_LIST")
# Instrucciones para conectarse a una instancia Web MCP local
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": BRIGHT_DATA_API_KEY,
"PRO_MODE": "true" # Opcional
},
)
async with stdio_client(server_params) as (read, write), ClientSession(read, write) as session:
# Crear una sesión de conexión MCP y recuperar las herramientas
await session.initialize()
web_mcp_toolkit = await create_toolkit(session, use_mcp_resources=False)
# Definir un agente capaz de buscar y recuperar datos web
assistant_agent = AssistantAgent(
name="assistant",
code_execution_config=False,
llm_config=llm_config,
system_message="""
Tienes acceso a todas las herramientas expuestas por el MCP web, incluyendo:
- Búsqueda web
- Scraping web y obtención de páginas
- Fuentes de datos web
- Simulación de usuario basada en navegador
Utilice estas herramientas cuando sea necesario.
"""
)
# Registrar las herramientas Web MCP con el agente
web_mcp_toolkit.register_for_llm(assistant_agent)
# El mensaje que se debe pasar al agente
prompt = """
Recupera los datos del siguiente producto de Amazon y elabora un resumen rápido con la información principal:
"""
# Ejecutar el agente extendido MCP web de forma asíncrona
resultado = await assistant_agent.a_run(
mensaje=prompt,
herramientas=web_mcp_toolkit.tools,
entrada_del_usuario=False,
)
await resultado.process()
asyncio.run(launch_mcp_agent())Ejecútelo y el resultado será: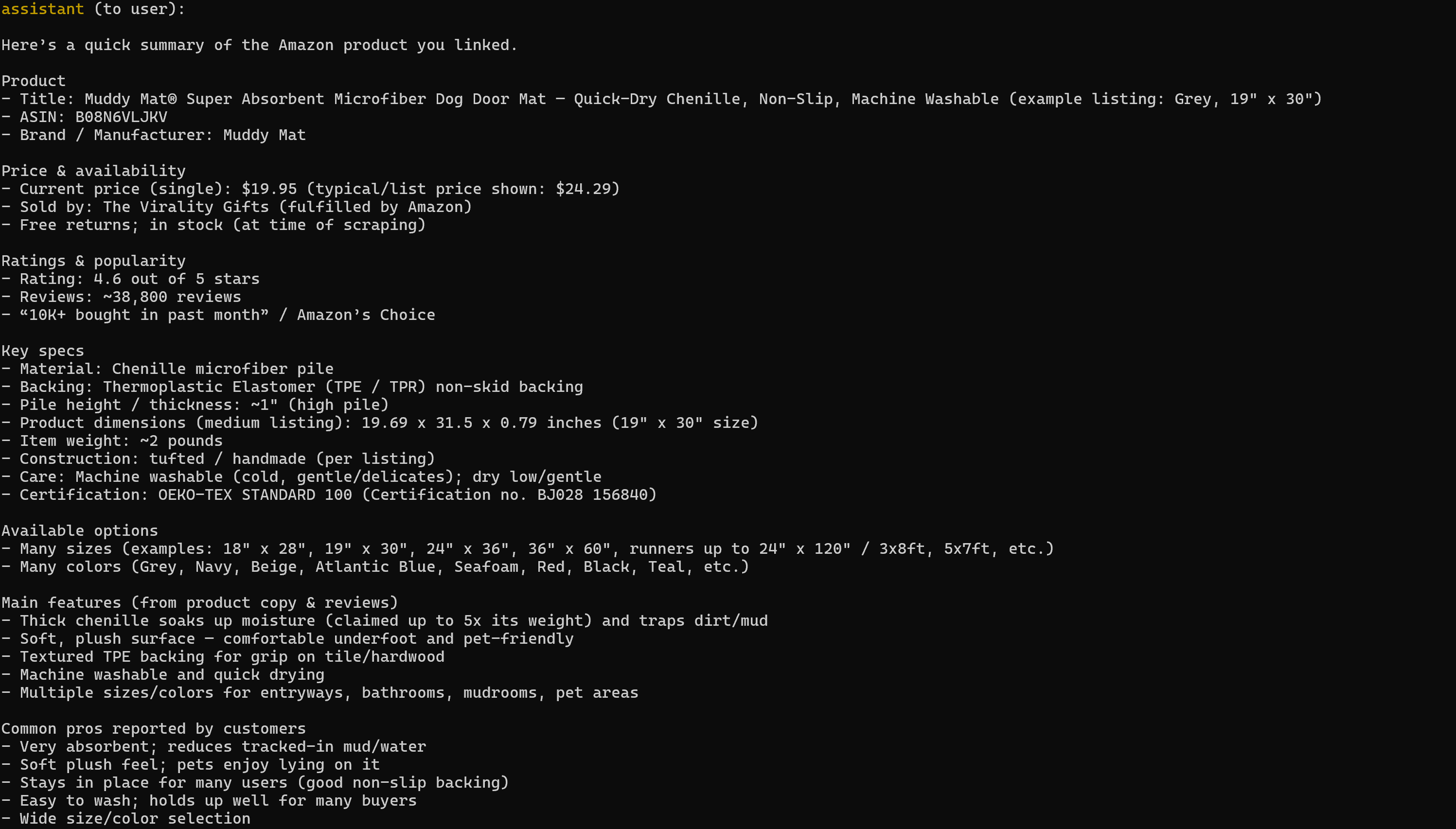
Ten en cuenta que el informe generado incluye todos los datos relevantes de la página del producto de Amazon en cuestión: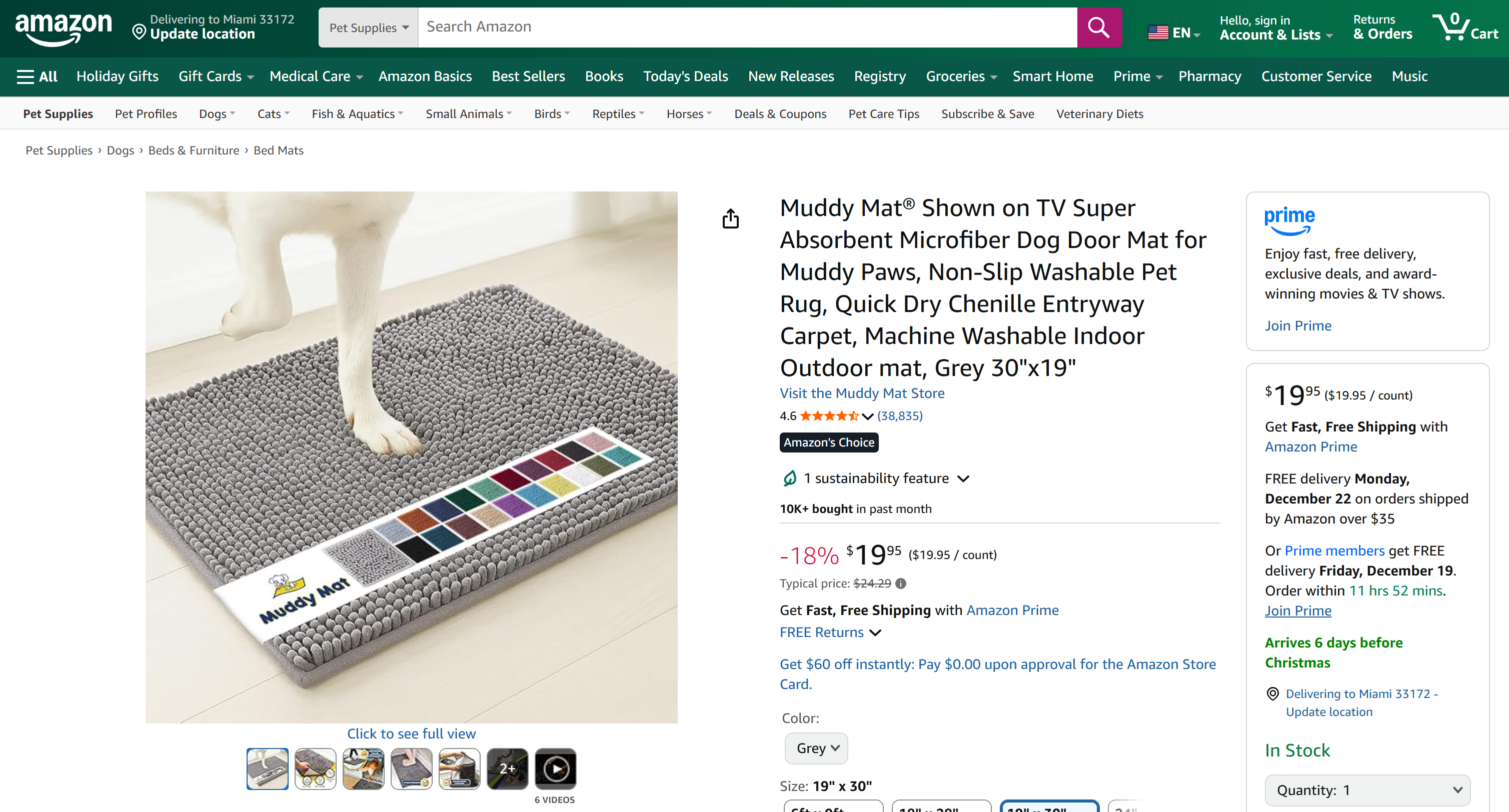
Si alguna vez ha intentado extraer datos de productos de Amazon en Python, sabrá que no es tarea fácil. Amazon emplea el famoso CAPTCHA de Amazon, además de otras medidas antibots. Además, las páginas de productos cambian constantemente y tienen estructuras variables.
Web MCP de Bright Data se encarga de todo eso por ti. En el nivel gratuito, llama a la herramienta scrape_as_markdown entre bastidores para recuperar la estructura de la página en Markdown limpio a través de Web Unlocker. En el modo Pro, aprovecha el producto web_data_amazon_product, que llama al Amazon Scraper de Bright Data para recopilar datos de productos totalmente estructurados.
¡Eso es todo! Ahora ya sabe cómo ampliar AG2 con Bright Data Web MCP.
Conclusión
En este tutorial, ha aprendido a integrar Bright Data con AG2, ya sea a través de funciones personalizadas o mediante Web MCP.
Esta integración permite a los agentes de AG2 realizar búsquedas en la web, extraer datos estructurados, acceder a fuentes web en directo y automatizar las interacciones web. Todo ello gracias al conjunto de servicios de Bright Data para IA.
¡Crea una cuenta gratuita en Bright Data y empieza a explorar hoy mismo nuestras herramientas de datos web preparadas para la IA!




