

Crawl4AI y Firecrawl son dos de los productos de IA más populares en el sector de la recopilación de datos. En esta guía, repasaremos el uso básico y las estadísticas de ambos productos.
Cuando hayas terminado de leer, serás capaz de responder a las siguientes preguntas.
- ¿Qué es Crawl4AI?
- ¿Qué es Firecrawl?
- ¿Dónde brilla cada uno de ellos?
- ¿Dónde se quedan cortos?
- ¿Por qué Bright Data es una gran alternativa a ambos?
Comprender cómo se comparan estas nuevas herramientas ayuda a destacar las soluciones completas y escalables de Bright Data. Tanto si necesita capacidades generales de scraping como una suite de recopilación de datos a gran escala, Bright Data le ofrece una tecnología probada.
Visión general y objetivo
Antes de entrar en detalles, veamos en qué consiste cada uno de estos productos y a quién van dirigidos. Dado que cada uno tiene una finalidad distinta, no se trata de una comparación de manzanas con manzanas. Es más una comparación de “caja de herramientas frente a navaja suiza”.
Crawl4AI

Crawl4AI es una biblioteca Python de código abierto que facilita y hace más accesible el raspado web basado en IA. Está más orientada a los desarrolladores que desean ampliar sus canales de extracción. Es completamente de código abierto. El código está disponible gratuitamente en su página de GitHub. Crawl4AI se alinea más con las herramientas de raspado tradicionales de Bright Data.
Firecrawl
Firecrawl es uno de los líderes empresariales en el raspado web impulsado por IA. Ofrecen un marco de trabajo independiente del idioma y muchas opciones de integración. Firecrawl despierta el interés de personas que tradicionalmente no se dedican a la recopilación de datos o incluso al desarrollo. Con Firecrawl, el scraping se hace accesible a personas que no siempre tienen conocimientos de codificación.
Características únicas
Crawl4AI
Crawl4AI destaca porque es completamente de código abierto y utiliza licencias permisivas. Eche un vistazo a las características que hacen de Crawl4AI una opción muy atractiva para los desarrolladores. Esta herramienta ofrece opciones configurables y confianza a través de la transparencia en el código.
- Código abierto: Cualquiera puede consultar el código. La comunidad suele detectar los errores y corregirlos rápidamente. La transparencia del código implica que no hay sorpresas, si sabes leer código.
- Extracción con LLM y sin LLM: Con Crawl4AI, puede elegir entre utilizar un pequeño modelo local para la extracción o conectarse a un modelo externo como Deepseek.
- Licencias permisivas: La licencia de Crawl4AI es muy flexible y permisiva. Esto atrae el interés tanto de aficionados como de desarrolladores empresariales.
- Biblioteca Python: Crawl4AI no es un servicio de suscripción. Es una librería Python. Puedes conectarlo a otras cosas y si quisieras, podrías construir tu propio scraper usando Crawl4AI como backend.
Firecrawl
Firecrawl es una de las herramientas empresariales más populares para el web scraping. Ofrecen un marco de trabajo independiente del lenguaje: puede utilizar Python, JavaScript o su sitio web GUI para realizar la extracción. Ofrecen una variedad de planes adaptados a los aficionados y clientes empresariales por igual.
- Paraempresas: Firecrawl es un producto para empresas. Ofrecen una opción de código abierto. Sin embargo, su principal línea de productos está orientada a personas que desean una recopilación de datos escalable hoy en día.
- Lenguaje agnóstico: Firecrawl ofrece soporte GUI a través de su aplicación web. También ofrecen soporte SDK para Python y JavaScript. Hay SDKs impulsados por la comunidad en Go y Rust también. Con Firecrawl, no estás limitado a Python. Ni siquiera estás limitado a un entorno de programación.
- Procesamiento del lenguaje natural (PLN): Firecrawl está orientado al desarrollo y recopilación de datos mediante lenguaje natural. Usted le dice al modelo lo que tiene que hacer. A continuación, el modelo realiza la tarea de recopilación.
Facilidad de uso
Crawl4AI
Empezar a utilizar Crawl4AI es relativamente sencillo. Puede instalarlo mediante pip y llamarlo desde su entorno Python. Los siguientes fragmentos muestran cómo instalarlo y verificar su instalación.
Instala Crawl4AI con el siguiente comando.
pip install crawl4aiEjecute la configuración para instalar los navegadores y las herramientas.
crawl4ai-setupUtilice el comando doctor para verificar su instalación e identificar cualquier problema.
crawl4ai-doctorEl código de abajo es muy simple. Viene directamente de la documentación de Crawl4AI aquí. Péguelo en cualquier archivo Python y ejecútelo con python nombre-del-archivo.py. En la práctica, Crawl4AI se ejecuta mejor como un comando shell. Ejecutar directamente desde VSCode u otros IDEs tiende a causar problemas con asyncio.
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(
url="https://www.example.com",
)
print(result.markdown[:300]) # Show the first 300 characters of extracted text
if __name__ == "__main__":
asyncio.run(main())Firecrawl
Para empezar con Firecrawl, basta con navegar hasta su zona de juegos e introducir la URL de destino. Esta interfaz es muy amigable para los no desarrolladores.
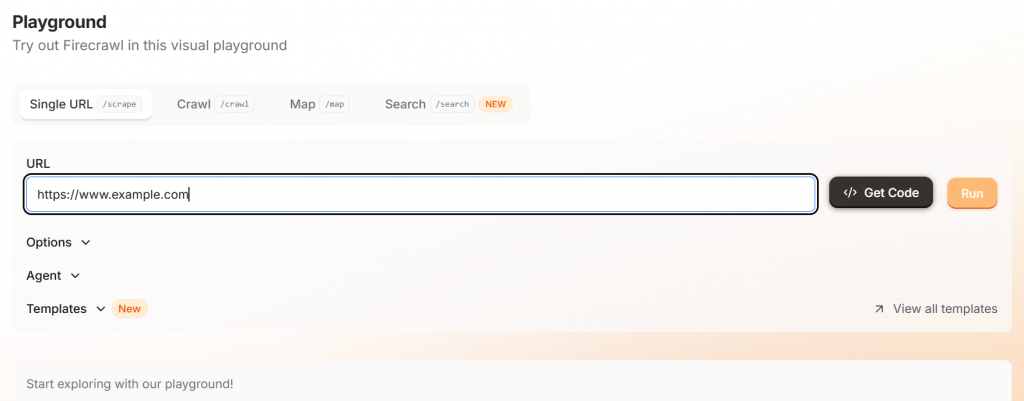
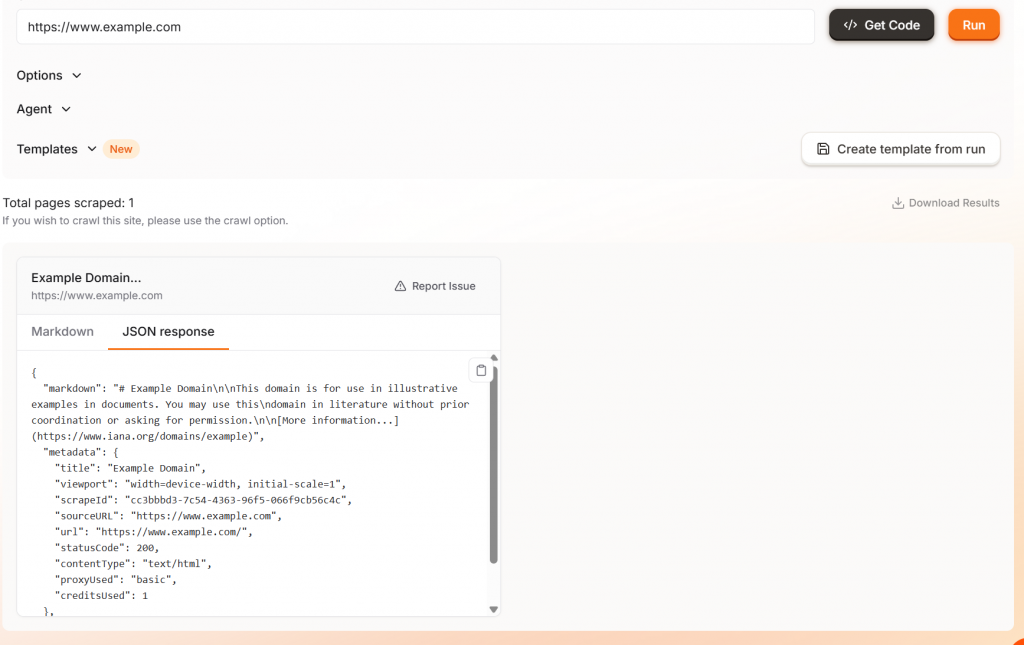
Si hace clic en el botón “Ejecutar”, verá un ejemplo de salida con su elección de markdown o JSON.
Rendimiento y escalabilidad
Crawl4AI
El siguiente fragmento procede del código de ejemplo que has visto antes. En total, tardó algo menos de dos segundos en rastrear el dominio de ejemplo. Sin un LLM, Crawl4AI es excepcionalmente rápido. Rivaliza con el scraping manual con Requests y BeautifulSoup en términos de rendimiento.

Sin embargo, el markdown scraping y el HTML crudo son lo más limpio que se puede hacer. Crawl4AI lista soporte para extracción JSON sin un LLM pero el soporte es limitado y con errores. Para extraer estructuras de datos completas, necesitas añadir un soporte LLM a tu código. Este es el coste oculto de Crawl4AI, necesitas alojar o pagar por un LLM externo para completar trabajos reales de análisis.
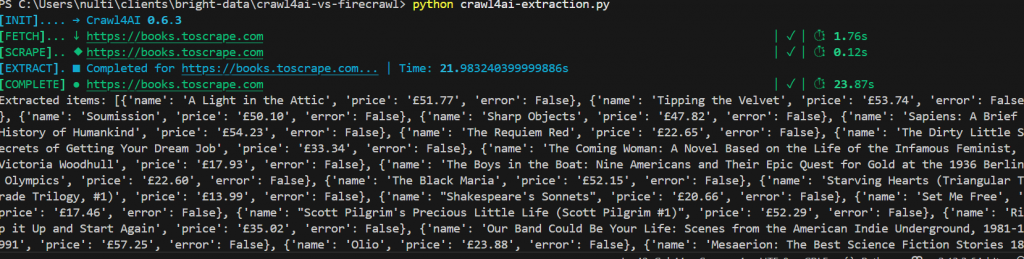
En el código siguiente, utilizamos un modelo OpenAI para analizar la página de Books to Scrape. Si decides ejecutarlo tú mismo, asegúrate de sustituir la clave API por la tuya.
import asyncio
import json
from pydantic import BaseModel
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode, LLMConfig
from crawl4ai.extraction_strategy import LLMExtractionStrategy
openai_api_key = "your-openai-api-key"
class Product(BaseModel):
name: str
price: str
async def main():
#tell the llm what to scrape and set config
llm_strategy = LLMExtractionStrategy(
llm_config = LLMConfig(provider="openai/gpt-4o-mini", api_token=openai_api_key),
schema=Product.model_json_schema(),
extraction_type="schema",
instruction="Extract all product objects with 'name' and 'price' from the content.",
chunk_token_threshold=1000,
overlap_rate=0.0,
apply_chunking=True,
input_format="markdown",
extra_args={"temperature": 0.0, "max_tokens": 800}
)
#build the crawler config
crawl_config = CrawlerRunConfig(
extraction_strategy=llm_strategy,
cache_mode=CacheMode.BYPASS
)
#create a browser config if needed
browser_cfg = BrowserConfig(headless=True)
async with AsyncWebCrawler(config=browser_cfg) as crawler:
#crawl a single page
result = await crawler.arun(
url="https://books.toscrape.com",
config=crawl_config
)
if result.success:
#assume the extracted content is json
data = json.loads(result.extracted_content)
print("Extracted items:", data)
#show usage stats
llm_strategy.show_usage()
else:
print("Error:", result.error_message)
if __name__ == "__main__":
asyncio.run(main())Este es nuestro resultado. En total, tardamos algo menos de 25 segundos. También puedes ver cada libro listado junto con su precio en un objeto JSON estructurado limpiamente.
Firecrawl
Firecrawl simplemente le permite introducir una URL y raspar la página. Cuando se utiliza la versión por defecto de Firecrawl, la página se muestra como un objeto JSON.
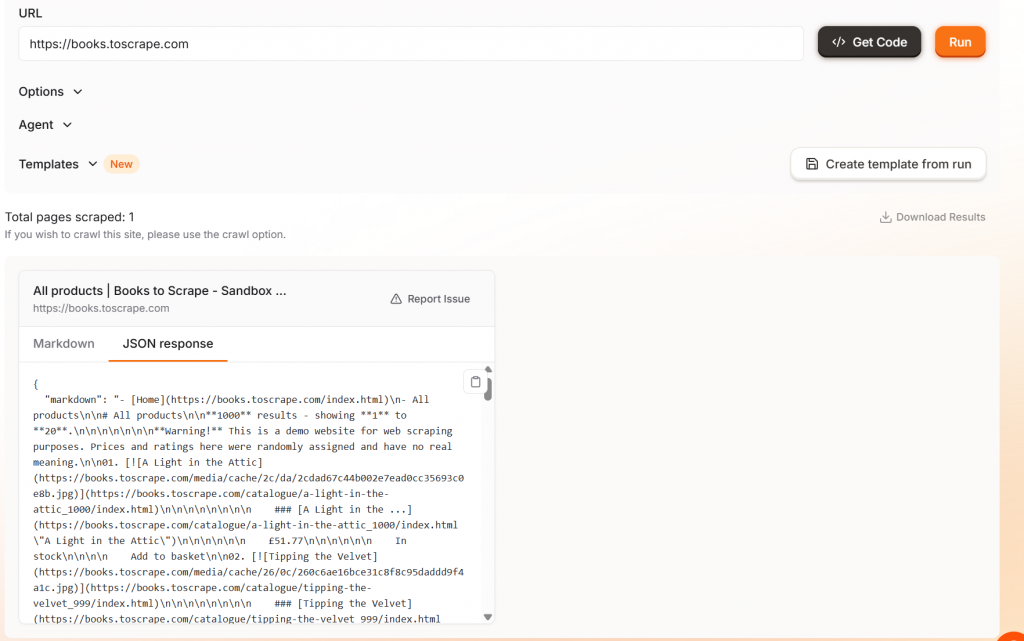
Firecrawl tiene una característica interesante cuando ejecutas tu código. Mientras tu scraper se ejecuta, puedes ver cómo el navegador renderiza la página.
Calidad y precisión de los datos
Crawl4AI
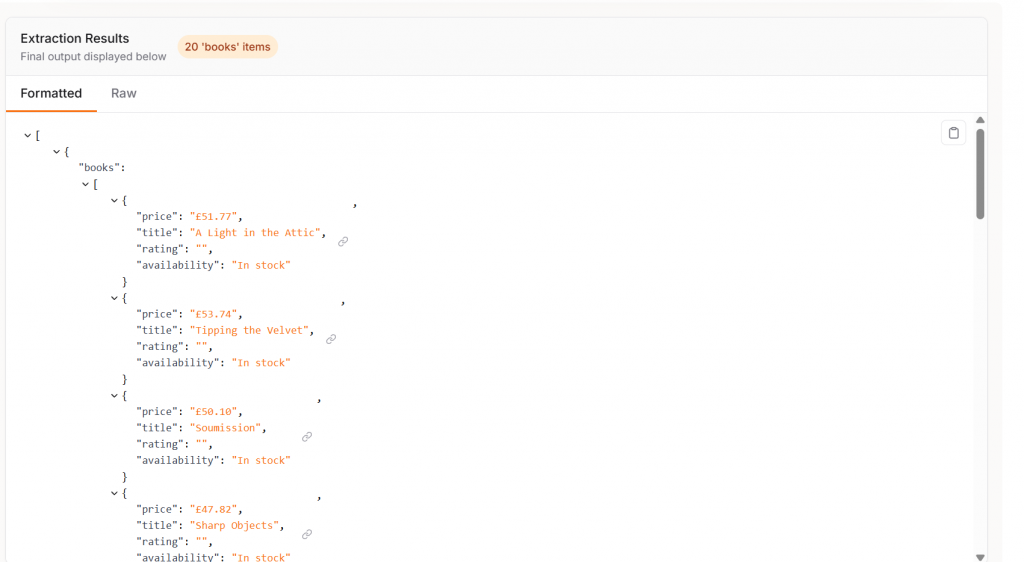
Cuando se conectó a GPT-4o, Crawl4AI funcionó con una precisión del 100%. Para comprobar nuestro recuento de elementos, añadimos la siguiente línea a nuestro código.
print("Total products scraped:", len(data))Como se puede ver en la salida de abajo, Crawl4AI y GPT-4o encontraron los 20 elementos de la página.

Cuando se combina con un LLM, Crawl4AI se convierte en una herramienta sorprendentemente potente con una precisión notable.
Firecrawl
Firecrawl en realidad ofrece dos productos diferentes cuando se trata de raspado. Puede utilizar el viejo Firecrawl para opciones de scraping simples y sucias. Firecrawl Extract le permite extraer objetos JSON estructurados.
Firecrawl regular
Este es el resultado de Books To Scrape usando Firecrawl normal. Como puede ver, es malo, realmente malo. Firecrawl convirtió la página a markdown. Luego, cortó el markdown crudo en campos aparentemente aleatorios de JSON. Estos datos necesitan ser limpiados usando código manualmente o pasados a un LLM.
{
"markdown": "All products \| Books to Scrape - Sandboxnn[Books to Scrape](index.html) We love being scraped!nn- [Home](index.html)n- All productsnn- [Books](catalogue/category/books_1/index.html) - [Travel](catalogue/category/books/travel_2/index.html)n - [Mystery](catalogue/category/books/mystery_3/index.html)n - [Historical Fiction](catalogue/category/books/historical-fiction_4/index.html)n - [Sequential Art](catalogue/category/books/sequential-art_5/index.html)n - [Classics](catalogue/category/books/classics_6/index.html)n - [Philosophy](catalogue/category/books/philosophy_7/index.html)n - [Romance](catalogue/category/books/romance_8/index.html)n - [Womens Fiction](catalogue/category/books/womens-fiction_9/index.html)n - [Fiction](catalogue/category/books/fiction_10/index.html)n - [Childrens](catalogue/category/books/childrens_11/index.html)n - [Religion](catalogue/category/books/religion_12/index.html)n - [Nonfiction](catalogue/category/books/nonfiction_13/index.html)n - [Music](catalogue/category/books/music_14/index.html)n - [Default](catalogue/category/books/default_15/index.html)n - [Science Fiction](catalogue/category/books/science-fiction_16/index.html)n - [Sports and Games](catalogue/category/books/sports-and-games_17/index.html)n - [Add a comment](catalogue/category/books/add-a-comment_18/index.html)n - [Fantasy](catalogue/category/books/fantasy_19/index.html)n - [New Adult](catalogue/category/books/new-adult_20/index.html)n - [Young Adult](catalogue/category/books/young-adult_21/index.html)n - [Science](catalogue/category/books/science_22/index.html)n - [Poetry](catalogue/category/books/poetry_23/index.html)n - [Paranormal](catalogue/category/books/paranormal_24/index.html)n - [Art](catalogue/category/books/art_25/index.html)n - [Psychology](catalogue/category/books/psychology_26/index.html)n - [Autobiography](catalogue/category/books/autobiography_27/index.html)n - [Parenting](catalogue/category/books/parenting_28/index.html)n - [Adult Fiction](catalogue/category/books/adult-fiction_29/index.html)n - [Humor](catalogue/category/books/humor_30/index.html)n - [Horror](catalogue/category/books/horror_31/index.html)n - [History](catalogue/category/books/history_32/index.html)n - [Food and Drink](catalogue/category/books/food-and-drink_33/index.html)n - [Christian Fiction](catalogue/category/books/christian-fiction_34/index.html)n - [Business](catalogue/category/books/business_35/index.html)n - [Biography](catalogue/category/books/biography_36/index.html)n - [Thriller](catalogue/category/books/thriller_37/index.html)n - [Contemporary](catalogue/category/books/contemporary_38/index.html)n - [Spirituality](catalogue/category/books/spirituality_39/index.html)n - [Academic](catalogue/category/books/academic_40/index.html)n - [Self Help](catalogue/category/books/self-help_41/index.html)n - [Historical](catalogue/category/books/historical_42/index.html)n - [Christian](catalogue/category/books/christian_43/index.html)n - [Suspense](catalogue/category/books/suspense_44/index.html)n - [Short Stories](catalogue/category/books/short-stories_45/index.html)n - [Novels](catalogue/category/books/novels_46/index.html)n - [Health](catalogue/category/books/health_47/index.html)n - [Politics](catalogue/category/books/politics_48/index.html)n - [Cultural](catalogue/category/books/cultural_49/index.html)n - [Erotica](catalogue/category/books/erotica_50/index.html)n - [Crime](catalogue/category/books/crime_51/index.html)nn# All productsnn**1000** results - showing **1** to **20**.nnnnnnn**Warning!** This is a demo website for web scraping purposes. Prices and ratings here were randomly assigned and have no real meaning.nn01. [](catalogue/a-light-in-the-attic_1000/index.html)nnnnnnnn ### [A Light in the ...](catalogue/a-light-in-the-attic_1000/index.html "A Light in the Attic")nnnnnn £51.77nnnnnn In stocknnnn Add to basketnn02. [](catalogue/tipping-the-velvet_999/index.html)nnnnnnnn ### [Tipping the Velvet](catalogue/tipping-the-velvet_999/index.html "Tipping the Velvet")nnnnnn £53.74nnnnnn In stocknnnn Add to basketnn03. [](catalogue/soumission_998/index.html)nnnnnnnn ### [Soumission](catalogue/soumission_998/index.html "Soumission")nnnnnn £50.10nnnnnn In stocknnnn Add to basketnn04. [](catalogue/sharp-objects_997/index.html)nnnnnnnn ### [Sharp Objects](catalogue/sharp-objects_997/index.html "Sharp Objects")nnnnnn £47.82nnnnnn In stocknnnn Add to basketnn05. [](catalogue/sapiens-a-brief-history-of-humankind_996/index.html)nnnnnnnn ### [Sapiens: A Brief History ...](catalogue/sapiens-a-brief-history-of-humankind_996/index.html "Sapiens: A Brief History of Humankind")nnnnnn £54.23nnnnnn In stocknnnn Add to basketnn06. [](catalogue/the-requiem-red_995/index.html)nnnnnnnn ### [The Requiem Red](catalogue/the-requiem-red_995/index.html "The Requiem Red")nnnnnn £22.65nnnnnn In stocknnnn Add to basketnn07. [](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html)nnnnnnnn ### [The Dirty Little Secrets ...](catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html "The Dirty Little Secrets of Getting Your Dream Job")nnnnnn £33.34nnnnnn In stocknnnn Add to basketnn08. [](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html)nnnnnnnn ### [The Coming Woman: A ...](catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html "The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull")nnnnnn £17.93nnnnnn In stocknnnn Add to basketnn09. [](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html)nnnnnnnn ### [The Boys in the ...](catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html "The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics")nnnnnn £22.60nnnnnn In stocknnnn Add to basketnn10. [](catalogue/the-black-maria_991/index.html)nnnnnnnn ### [The Black Maria](catalogue/the-black-maria_991/index.html "The Black Maria")nnnnnn £52.15nnnnnn In stocknnnn Add to basketnn11. [](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html)nnnnnnnn ### [Starving Hearts (Triangular Trade ...](catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html "Starving Hearts (Triangular Trade Trilogy, \#1)")nnnnnn £13.99nnnnnn In stocknnnn Add to basketnn12. [](catalogue/shakespeares-sonnets_989/index.html)nnnnnnnn ### [Shakespeare's Sonnets](catalogue/shakespeares-sonnets_989/index.html "Shakespeare's Sonnets")nnnnnn £20.66nnnnnn In stocknnnn Add to basketnn13. [](catalogue/set-me-free_988/index.html)nnnnnnnn ### [Set Me Free](catalogue/set-me-free_988/index.html "Set Me Free")nnnnnn £17.46nnnnnn In stocknnnn Add to basketnn14. [](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html)nnnnnnnn ### [Scott Pilgrim's Precious Little ...](catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html "Scott Pilgrim's Precious Little Life (Scott Pilgrim \#1)")nnnnnn £52.29nnnnnn In stocknnnn Add to basketnn15. [](catalogue/rip-it-up-and-start-again_986/index.html)nnnnnnnn ### [Rip it Up and ...](catalogue/rip-it-up-and-start-again_986/index.html "Rip it Up and Start Again")nnnnnn £35.02nnnnnn In stocknnnn Add to basketnn16. [](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html)nnnnnnnn ### [Our Band Could Be ...](catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html "Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991")nnnnnn £57.25nnnnnn In stocknnnn Add to basketnn17. [](catalogue/olio_984/index.html)nnnnnnnn ### [Olio](catalogue/olio_984/index.html "Olio")nnnnnn £23.88nnnnnn In stocknnnn Add to basketnn18. [](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html)nnnnnnnn ### [Mesaerion: The Best Science ...](catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html "Mesaerion: The Best Science Fiction Stories 1800-1849")nnnnnn £37.59nnnnnn In stocknnnn Add to basketnn19. [](catalogue/libertarianism-for-beginners_982/index.html)nnnnnnnn ### [Libertarianism for Beginners](catalogue/libertarianism-for-beginners_982/index.html "Libertarianism for Beginners")nnnnnn £51.33nnnnnn In stocknnnn Add to basketnn20. [](catalogue/its-only-the-himalayas_981/index.html)nnnnnnnn ### [It's Only the Himalayas](catalogue/its-only-the-himalayas_981/index.html "It's Only the Himalayas")nnnnnn £45.17nnnnnn In stocknnnn Add to basketnnn-nPage 1 of 50nnn- [next](catalogue/page-2.html)",
"metadata": {
"language": "en-us",
"description": "",
"created": "24th Jun 2016 09:29",
"viewport": "width=device-width",
"title": "n All products | Books to Scrape - Sandboxn",
"robots": "NOARCHIVE,NOCACHE",
"favicon": "https://books.toscrape.com/static/oscar/favicon.ico",
"scrapeId": "aa3667ec-647b-42ab-adb2-9c35e042896d",
"sourceURL": "https://books.toscrape.com",
"url": "https://books.toscrape.com/",
"statusCode": 200,
"contentType": "text/html",
"proxyUsed": "basic",
"creditsUsed": 80
},
"scrape_id": "aa3667ec-647b-42ab-adb2-9c35e042896d"
}El Firecrawl normal obtendrá la página, pero no hace mucho más que eso. Obtendrá una página markdown troceada y convertida en un gran objeto JSON. Usted puede obtener la página, pero requiere mucho trabajo para transformar su página web en datos utilizables.
Extracto de Firecrawl
Extract es el siguiente nivel. Con Extract, obtienes soporte completo para el scraping a través de NLP. Dígale al modelo qué datos debe obtener y los extraerá de la página. Como puede ver en la imagen siguiente, incluso obtenemos un esquema recomendado que contiene los campos de título, precio y disponibilidad. Si está satisfecho con su esquema, haga clic en el botón “Ejecutar”.
Tenga en cuenta que su sitio web viene acompañado de /*, que indica a Extract que rastree automáticamente todo el sitio. Para ahorrar créditos, elimine el /*.
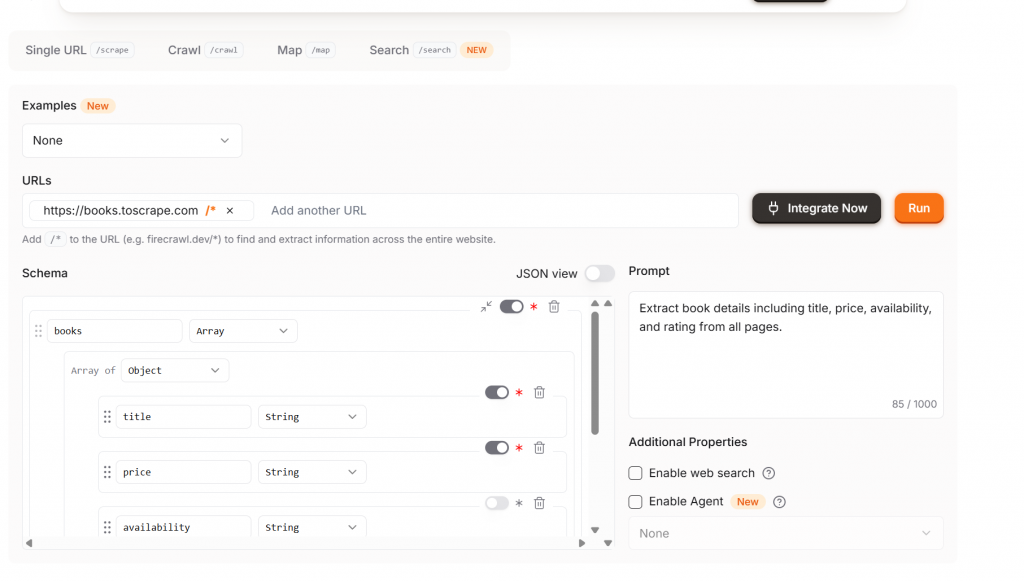
Si desea rastrear una sola página, asegúrese de cambiar Extract de la configuración predeterminada. La imagen de abajo muestra nuestra configuración para rastrear una sola página. El operador /* es muy fácil de pasar por alto, ahórrate dinero y utilízalo sólo cuando sea necesario.
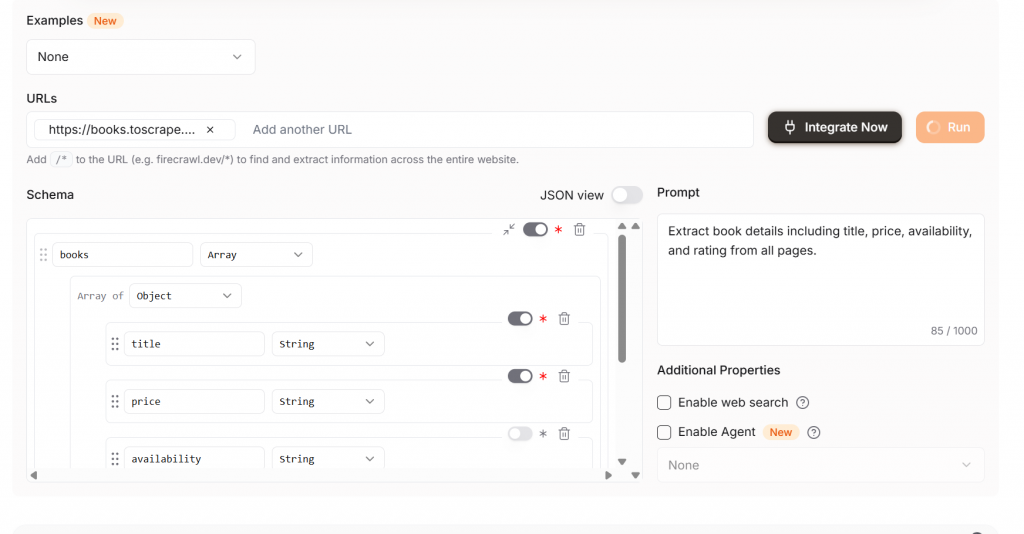
Con Firecrawl Extract, nuestra salida viene limpia y lista para usar. Como puede ver, obtenemos objetos JSON estructurados con los siguientes rasgos.
títulopreciovaloracióndisponibilidad
Seguridad y conformidad
Crawl4AI
Crawl4AI no viene con garantías de cumplimiento incorporadas en el software. Ofrecen algunas configuraciones que pueden ayudarle en el cumplimiento de aspectos como el archivo robots.txt.
Al utilizar Crawl4AI, usted es responsable de su propio cumplimiento de leyes como GDPR y CCPA. Crawl4AI no ofrece prácticamente ninguna ayuda con el cumplimiento legal y de seguridad. Esto significa que cuando se ejecuta un proyecto a escala, es probable que tenga que contratar ayuda adicional para asegurarse de que está siguiendo las prácticas adecuadas.
Firecrawl
Según su documentación, Firecrawl cede tus datos a Google para que los procese. Declaran explícitamente en sus términos que siguen el GDPR y la CCPA, pero que tú mismo estás obligado a respetar estas políticas. Cualquier incumplimiento de las mismas es responsabilidad tuya y que ellos no se hacen responsables del mal uso de sus herramientas.
Firecrawl ofrece más protección de responsabilidad que Crawl4AI. Sin embargo, todavía no es mucho. Sus productos no vienen con barandillas. Se espera que usted siga las reglas y si no lo hace, usted es responsable de cualquier mal uso. Para más información, eche un vistazo a los Términos de Servicio completos de Firecrawl.
Precios y licencias
Crawl4AI
Crawl4AI es de uso gratuito para cualquiera. Usamos el término “gratis” aquí de forma bastante laxa. Como probablemente hayas notado al seguirnos, cualquier trabajo real de extracción requiere la integración de LLM. Puedes alojar el LLM tú mismo o conectarte a un servicio como la API OpenAI. Cuando se utiliza Crawl4AI, usted todavía tiene que pagar por los servicios externos o los costes de infraestructura si auto-alojamiento. Estos costes se acumulan. Crawl4AI no reducirá sus costes operativos a cero.
Crawl4AI se distribuye bajo la Licencia Apache. Está permitido modificar, distribuir e incluso vender comercialmente derivados de Crawl4AI. Si cuentas con ayuda para el cumplimiento, la licencia permisiva de Crawl4AI lo convierte en una opción muy atractiva para desarrolladores y equipos de datos.
Firecrawl
Firecrawl regular
Vanilla Firecrawl tiene varios niveles de precios. Puede probar su plan gratuito. Sus planes de pago van desde $16/mes por 3,000 páginas hasta $333/mes por 500,000 páginas.

Extracto de Firecrawl
Al utilizar Extract, los planes de pago van desde 89 $/mes por 18.000.000 de tokens al año hasta 719 $/mes por 192.000.000 de tokens API al año.

Licencias Firecrawl
Firecrawl utiliza diferentes licencias para varios de sus productos. Puede ver todas sus licencias aquí. Tenga en cuenta que Firecrawl es un producto de nivel empresarial y que no podrá reempaquetar su código como propio. Incluso su código fuente abierto se distribuye bajo la licencia AGPL-3.0. Al igual que otros acuerdos de software GNU, este es muy restrictivo cuando se trata de uso empresarial.
Comunidad y apoyo
Crawl4AI
Como proyecto de código abierto, Crawl4AI ofrece el soporte limitado que puede con los recursos que tiene. No hay mesa de ayuda ni SLA. Sin embargo, puedes ponerte en contacto con sus desarrolladores a través de su canal de Discord. Los tiempos de espera pueden variar. No espere que un equipo dedicado rastree los problemas y resuelva sus necesidades a tiempo.
Firecrawl
Desde su panel de control, Firecrawl te ofrece opciones de soporte como documentación, páginas de preguntas frecuentes y actualizaciones de estado. Puedes ponerte en contacto con su equipo de soporte a través del botón “Contactar con soporte”, aunque tu prioridad varía en función del nivel de tu plan. También puedes unirte a su canal de Discord para recibir ayuda de la comunidad.

Casos de uso en el mundo real
Crawl4AI
Crawl4AI tiene una variedad de casos de uso en el mundo real para los desarrolladores modernos. Usted sólo está limitado por lo que puede construir.
- Soporte Backend: Si decidieras crear tus propios productos de datos, podrías integrar Crawl4AI con un LLM propio y vender tus productos.
- Agentes de IA: Como hicimos anteriormente en este artículo, puedes conectar LLMs externos directamente a Crawl4AI para potentes operaciones de extracción con salida de estructura de datos personalizada – CSV, JSON XML – cualquier formato que tu LLM haya visto es un formato viable.
- Proyectos de aficionados y startups: Las herramientas de código abierto como Crawl4AI ofrecen una rápida accesibilidad para experimentos, pruebas de concepto y prototipos de canalización.
Firecrawl
Firecrawl está diseñado para equipos que necesitan un gran volumen de scraping con muy poco desarrollo interno. Si quiere pasar de una idea a un producto tangible sin mucho trabajo, Firecrawl puede ayudarle.
- Rastreo a nivel de producción: Firecrawl está diseñado para rastrear a gran escala. Sus herramientas rastrean incluso sitios web completos por defecto.
- Supervisión de contenidos: Realice rastreos rutinarios de los competidores para supervisar sus precios y contenidos.
- Datos limpios y listos: Con Extract, puede pasar sus datos directamente al equipo de datos sin apenas necesidad de limpiarlos.
Ventajas e inconvenientes
| Crawl4AI | Firecrawl | |
|---|---|---|
| Pros | – Totalmente transparente y de código abierto. – Licencia Apache permisiva: cree, modifique, revenda. – Flexible: Opciones con o sin LLM. – Librería Python plug-and-play para pipelines personalizados. |
– Muy sencillo para los no desarrolladores: GUI, playground, NLP prompt. – Funciona en varios lenguajes (Python, JS, Go, Rust). – Rápido de desplegar para el scraping puntual o rutinario. – Precios para empresas y niveles de soporte disponibles. |
| Contras | – Requiere un LLM independiente para la extracción estructurada real, lo que añade costes ocultos. – Compatibilidad limitada con el cumplimiento: el usuario debe gestionar GDPR/CCPA. – Async peculiaridades – shell se ejecuta mejor, IDEs pueden romperlo. |
– Los resultados de base suelen ser confusos sin Extract. – No hay barreras reales para el cumplimiento – el usuario sigue siendo responsable. – El núcleo de código cerrado y las restricciones de la licencia AGPL limitan las versiones personalizadas. – Los costes de uso pueden crecer rápidamente con la escala o el rastreo comodín. |
Por qué debería considerar Bright Data
Tanto Crawl4AI como Firecrawl tienen ventajas y desventajas. Crawl4AI conlleva necesidades de desarrollo y costes LLM ocultos. Con Firecrawl, estás atrapado en niveles de uso y en el ecosistema de Firecrawl.
Bright Data ofrece una variedad de productos que pueden ayudar a llenar los mismos nichos de estas dos herramientas antes mencionadas.
Las mejores herramientas de Bright Data
- API de raspado: ejecute raspadores preconstruidos con datos limpios y listos para usar, siempre que lo desee.
- API de Web Unlocker: Evita los bloqueos de sitios y resuelve CAPTCHAs, scrapea como markdown e incluso controla tu geolocalización.
- API de navegador: Controle un navegador remoto con proxies integrados y resolución de CAPTCHA desde su entorno de programación.
- Conjuntos de datos: Accede a una amplia biblioteca de conjuntos de datos históricos de más de 100 dominios que se remontan años atrás.
Nuestro servidor MCP le proporciona acceso a los mejores productos de Bright Data en un paquete fácil de usar para LLM. Conéctelo a su LLM, escriba sus avisos y deje que el sistema haga su trabajo.
Opciones de integración de Bright Data
Incluso ofrecemos integración con algunas de las mejores herramientas de las industrias de IA y desarrollo de hoy en día. Estamos añadiendo nuevas integraciones todo el tiempo. Consulta nuestra documentación para ver la lista más actualizada.
Conclusión
En Bright Data, no solo resolvemos un problema de raspado, sino que ofrecemos un ecosistema completo para su pila de IA. Desde la recopilación de datos en tiempo real hasta la explotación de archivos históricos para la formación, nos aseguramos de que dedique su tiempo a la información, no a la infraestructura.
Inicie hoy mismo su prueba gratuita y compruebe la diferencia.





