

En esta guía aprenderás:
- Por qué GPT Vision es una gran elección para tareas de extracción de datos que van más allá de las técnicas tradicionales de análisis sintáctico.
- Cómo realizar un scraping visual de la web utilizando GPT Vision en Python.
- La principal limitación de este enfoque y cómo solventarla.
Sumerjámonos.
¿Por qué utilizar GPT Vision para el raspado de datos?
GPT Vision es un modelo de IA multimodal que entiende tanto texto como imágenes. Estas capacidades están disponibles en los últimos modelos de OpenAI. Al pasar una imagen a GPT Vision, se puede realizar la extracción de datos visuales, ideal para escenarios en los que el análisis tradicional de datos no funciona.
El análisis normal de datos implica escribir reglas personalizadas para recuperar datos de documentos (por ejemplo, selectores CSS o expresiones XPath para obtener datos de páginas HTML). Ahora bien, el problema es que la información puede estar incrustada visualmente en imágenes, banners o elementos complejos de la interfaz de usuario a los que no se puede acceder con las técnicas de análisis estándar.
GPT Vision le ayuda a extraer datos de estas fuentes de difícil acceso. Los dos casos de uso más comunes son:
- Web scraping visual: Extraiga contenido web directamente de capturas de pantalla de páginas, sin preocuparse por los cambios de página o los elementos visuales de la página.
- Extracción de documentos basada en imágenes: Recupere datos estructurados de capturas de pantalla o escaneados de archivos locales como currículos, facturas, menús y recibos.
Para un enfoque no visual, consulte nuestra guía sobre web scraping con ChatGPT.
Cómo extraer datos de capturas de pantalla con GPT Vision en Python
En esta sección paso a paso, aprenderá a construir un script de raspado web de GPT Vision. En detalle, el scraper automatizará estas tareas:
- Utilice Playwright para conectarse a la página web de destino.
- Haga una captura de pantalla de la sección específica de la que desea extraer datos.
- Pase la captura de pantalla a GPT Vision y pídale que extraiga los datos estructurados.
- Exporte los datos extraídos a un archivo JSON.
El objetivo es una página de producto específica de “Books to Scrape”:
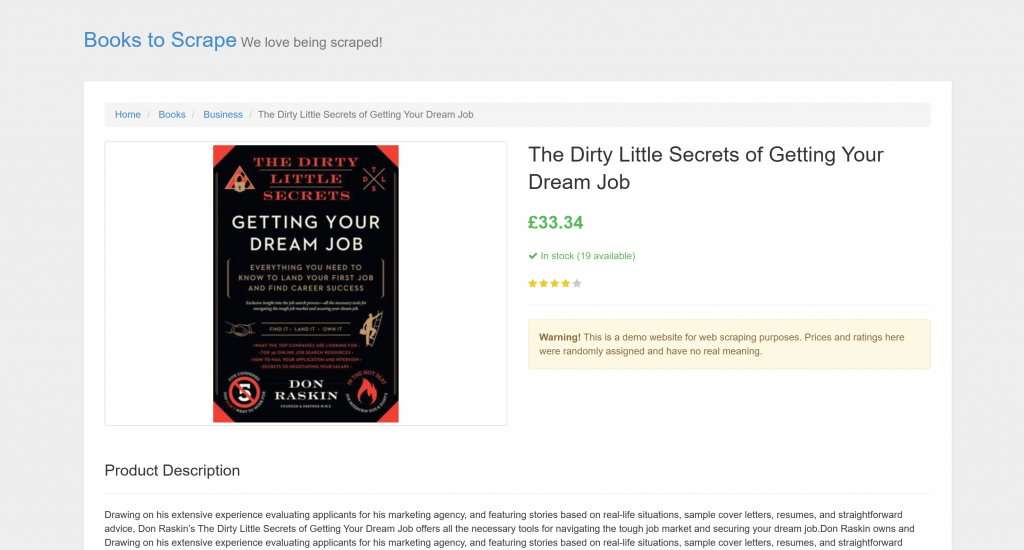
Esta página es perfecta para las pruebas, ya que da la bienvenida explícitamente a los robots de scraping automatizados. Además, incluye elementos visuales como el widget de puntuación con estrellas, que son difíciles de tratar con los métodos de análisis convencionales.
Nota: El fragmento de ejemplo se escribirá en Python por simplicidad y porque el OpenAI Python SDK está ampliamente adoptado. Sin embargo, puedes conseguir los mismos resultados utilizando el SDK de OpenAI JavaScript o cualquier otro lenguaje compatible.
Siga los pasos que se indican a continuación para aprender a raspar datos web con GPT Vision.
Requisitos previos
Antes de empezar, asegúrate de que tienes:
- Python 3.8 o superior instalado en su máquina.
- Una clave de API OpenAI para acceder a la API GPT Vision.
Para recuperar tu clave API de OpenAI, sigue la guía oficial.
Los siguientes conocimientos previos también le ayudarán a sacar el máximo partido de este artículo:
- Conocimientos básicos de automatización de navegadores, en particular mediante Playwright.
- Familiaridad con el funcionamiento de GPT Vision.
Nota: Para este método se necesita una herramienta de automatización del navegador como Playwright. La razón es que necesita renderizar la página de destino dentro de un navegador. Después, una vez cargada la página, puede hacer una captura de pantalla de la sección específica que le interese. Esto se puede hacer utilizando la API de capturas de pantalla de Playwright.
Paso 1: Cree su proyecto Python
Ejecute el siguiente comando en su terminal para crear una nueva carpeta para su proyecto de scraping:
mkdir gpt-vision-scrapergpt-vision-scraper/ servirá como carpeta principal del proyecto para construir su raspador web utilizando GPT Vision.
Navega hasta la carpeta y crea un entorno virtual Python dentro de ella:
cd gpt-vision-scraper
python -m venv venvAbre la carpeta del proyecto en tu IDE de Python preferido. Visual Studio Code con la extensión Python o PyCharm Community Edition serán suficientes.
Dentro de la carpeta del proyecto, crea un archivo scraper.py:
gpt-vision-scraper
├─── venv/
└─── scraper.py # <------------En este momento, scraper.py es sólo un archivo vacío. Pronto, contendrá la lógica para el raspado visual de la web LLM a través de GPT Vision.
A continuación, activa el entorno virtual en tu terminal. En Linux o macOS, ejecute:
source venv/bin/activateEquivalentemente, en Windows, ejecute:
venv/Scripts/activate¡Qué bien! Su entorno Python ya está listo para el scraping visual con GPT Vision.
Nota: En los pasos siguientes, se le mostrará cómo instalar las dependencias necesarias. Si prefieres instalarlas todas a la vez, ejecuta este comando:
pip install playwright openaiEntonces:
python -m playwright install¡Genial! Tu entorno Python ya está listo.
Paso 2: Conectarse al sitio de destino
En primer lugar, debe indicar a Playwright que visite el sitio de destino mediante un navegador controlado. En su entorno virtual activado, instale Playwright con:
pip install playwright A continuación, complete la instalación descargando los binarios necesarios del navegador:
python -m playwright installA continuación, importe Playwright en su script y utilice la función goto() para navegar a la página de destino:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Screenshotting logic...
# Close the browser and release its resources
browser.close()Si no está familiarizado con esta API, lea nuestro artículo sobre web scraping con Playwright.
¡Impresionante! Ahora tiene un script Playwright que se conecta con éxito a la página de destino. Es hora de hacer una captura de pantalla.
Paso 3: Haga una captura de pantalla de la página
Antes de escribir la lógica para hacer una captura de pantalla, ten en cuenta que OpenAI cobra en función del uso de tokens. En otras palabras, cuanto más grande sea tu captura de pantalla de entrada, más gastarás.
Para reducir costes, es mejor limitar la captura de pantalla a los elementos HTML que contienen los datos que le interesan. Esto es posible, ya que Playwright admite capturas de pantalla basadas en nodos. Tener una captura de pantalla reducida también ayudará a GPT Vision a centrarse en el contenido relevante, lo que reduce el riesgo de alucinaciones.
Para empezar, abra la página de destino en el navegador y familiarícese con su estructura. A continuación, haz clic con el botón derecho en el contenido y selecciona “Inspeccionar” para abrir las DevTools del navegador:
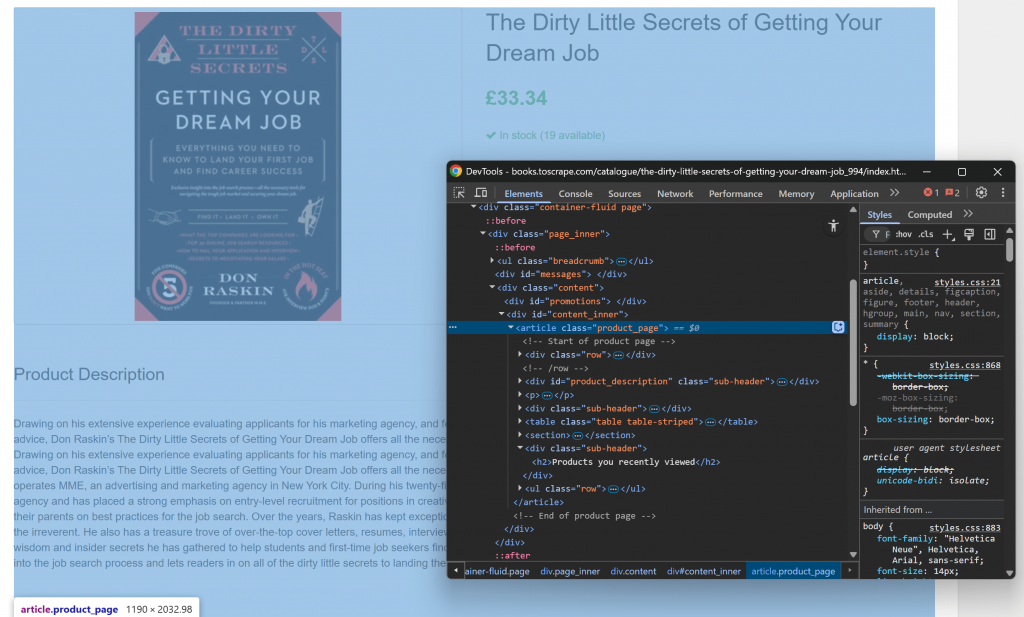
Observará que la mayor parte del contenido relevante se encuentra en el elemento HTML .product_page.
Dado que este elemento puede cargarse dinámicamente o revelarse con JavaScript, debe esperar a que se cargue antes de capturar:
product_page_element = page.locator(".product_page")
product_page_element.wait_for()Por defecto, wait_for() esperará hasta 30 segundos a que el elemento aparezca en el DOM. Este micro-paso es fundamental, ya que no querrás hacer una captura de pantalla de una sección vacía o invisible.
Ahora, utilice el método screenshot() en el localizador seleccionado para tomar una captura de pantalla sólo de ese elemento:
product_page_element.screenshot(path=SCREENSHOT_PATH)Aquí, SCREENSHOT_PATH es una variable que contiene el nombre del archivo de salida, como:
SCREENSHOT_PATH = "product_page.png"Almacenar esa información en una variable es una buena idea, ya que pronto la volverás a necesitar.
Si ejecutas el script, generará un archivo llamado product_page.png que contiene:
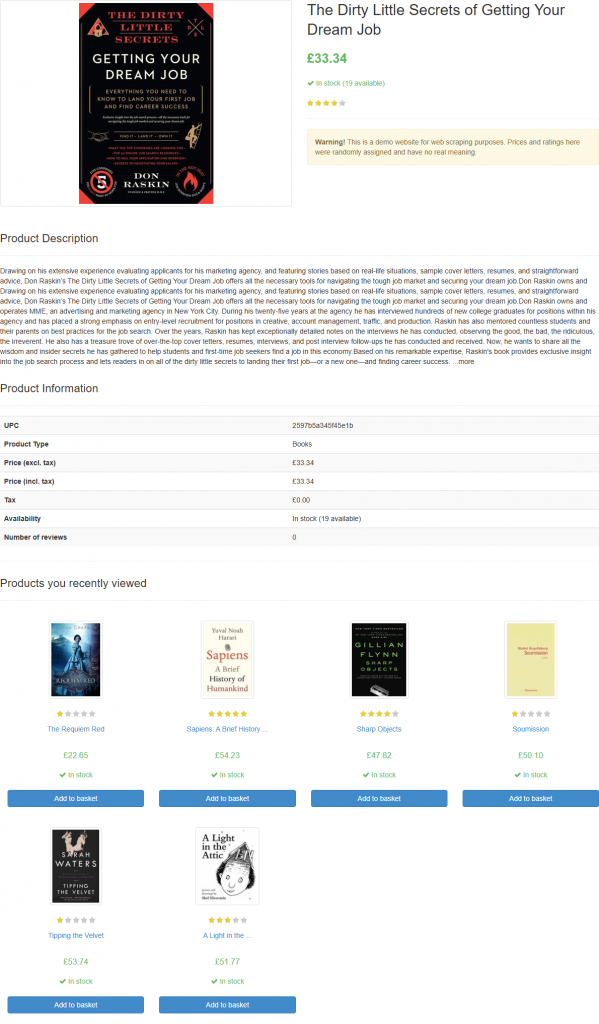
Nota: Guardar la captura de pantalla en un archivo es la mejor práctica, ya que es posible que desee volver a analizarla más adelante utilizando técnicas o modelos diferentes.
¡Fantástico! Se acabó lo de hacer capturas de pantalla.
Paso 4: Configurar OpenAI en Python
Para emplear GPT Vision para el web scraping, puedes utilizar el SDK OpenAI Python. Con su entorno virtual activado, instale el paquete openai:
pip install openaiA continuación, importa el cliente OpenAI en scraper.py:
from openai import OpenAIContinúa inicializando una instancia de cliente OpenAI:
client = OpenAI()Esto le permite conectarse más fácilmente a la API OpenAI, incluyendo Vision APIs. Por defecto, el constructor OpenAI( ) busca su clave API en la variable de entorno OPENAI_API_KEY. Establecer esa env es la forma recomendada de configurar la autenticación de forma segura.
Para fines de desarrollo o pruebas, también puede añadir la clave directamente en el código:
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>"
client = OpenAI(api_key=OPENAI_API_KEY)Reemplaza el con tu clave de API de OpenAI real.
¡Maravilloso! Su configuración de OpenAI está ahora completa, y está listo para usar GPT Vision para el web scraping.
Paso nº 5: Enviar la solicitud de raspado de GPT Vision
GPT Vision acepta imágenes de entrada en varios formatos, incluyendo URLs de imágenes públicas. Dado que trabaja con un archivo local, debe enviar la imagen al servidor OpenAI convirtiéndola en una cadena codificada en Base64.
Para convertir su archivo de captura de pantalla a Base64, escriba el siguiente código:
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8") Esto requiere esta importación de la biblioteca estándar de Python:
import base64Ahora, pase la imagen codificada a GPT Vision para el raspado visual de la web:
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)Nota: El ejemplo anterior establece el modelo gpt-4.1, pero puede utilizar cualquier modelo de OpenAI que admita capacidades visuales.
Observe cómo GPT Vision se integra directamente en la API Responses. Esto significa que no necesita configurar nada especial. Simplemente incluya su imagen Base64 usando "type": "input_image", y ya está listo.
La instrucción de raspado utilizada es:
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.Es posible que no conozca la estructura exacta de la página de destino, por lo que debe mantener la instrucción bastante genérica (pero centrada en el objetivo). En este caso, ordenamos explícitamente al modelo que ignore las secciones que no nos interesan. Además, pedimos que devuelva un objeto JSON con nombres de clave limpios y bien estructurados.
Ten en cuenta que la solicitud de la API OpenAI Responses está configurada para trabajar en modo JSON. Así es como puede asegurarse de que el modelo producirá una salida en formato JSON. Para que esta característica funcione, su solicitud debe incluir una instrucción para devolver datos en JSON como:
Return the data in JSON format using lowercase snake_case attribute names.De lo contrario, la solicitud fallará con:
openai.BadRequestError: Error code: 400 - {
'error': {
'message': "Response input messages must contain the word 'json' in some form to use 'text.format' of type 'json_object'.",
'type': 'invalid_request_error',
'param': 'input',
'code': None
}
}Una vez que la solicitud se haya completado correctamente, podrá acceder a los datos estructurados analizados mediante:
json_product_data = response.output_textOpcionalmente, analizar la cadena resultante para convertirla en un diccionario Python:
import json
product_data = json.loads(json_product_data)Lógica de análisis de datos de GPT Vision completada. Sólo queda exportar los datos raspados a un archivo JSON local.
Paso 6: Exportar los datos obtenidos
Escriba la cadena JSON de salida producida por la llamada a la API de GPT Vision con:
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)Esto creará un archivo product.json que almacenará los datos extraídos visualmente.
¡Bien hecho! Su GPT Vision-powered web scraper ya está listo.
Paso 7: Póngalo todo junto
A continuación se muestra el código final de scraper.py:
from playwright.sync_api import sync_playwright
from openai import OpenAI
import base64
# Where to store the page screenshot
SCREENSHOT_PATH = "product_page.png"
with sync_playwright() as p:
# Launch a new Playwright instance
browser = p.chromium.launch()
page = browser.new_page()
# Visit the target page
url = "https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html"
page.goto(url)
# Wait for the product page element to be on the DOM
product_page_element = page.locator(".product_page")
product_page_element.wait_for()
# Take a full screenshot of the element
product_page_element.screenshot(path=SCREENSHOT_PATH)
# Close the browser and release its resources
browser.close()
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot from the filesystem
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the data extraction request via GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Extract structured data (e.g., title, description, rating in the format "x/5", etc.) from the following product page.
Ignore the "Products you recently viewed" section.
Return the data in JSON format using lowercase snake_case attribute names.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
text={"format": {"type": "json_object"}} # Enable JSON Mode to get output data in JSON format
)
# Extract the output data and export it to a JSON file
json_product_data = response.output_text
with open("product.json", "w", encoding="utf-8") as f:
f.write(json_product_data)¡Vaya! En menos de 65 líneas de código, acabas de realizar un web scraping visual con GPT Vision.
Ejecute el rascador GPT Vision con:
python scraper.pyEl script tardará un rato y luego escribirá un archivo product.json en la carpeta de tu proyecto. Ábrelo y deberías ver:
{
"title": "The Dirty Little Secrets of Getting Your Dream Job",
"price_gbp": "£33.34",
"availability": "In stock (19 available)",
"rating": "4/5",
"description": "Drawing on his extensive experience evaluating applicants for his marketing agency, and featuring stories based on real-life situations, sample cover letters, resumes, and straightforward advice, Don Raskin’s The Dirty Little Secrets of Getting Your Dream Job offers all the necessary tools for navigating the tough job market and securing your dream job... [omitted for brevity]",
"product_information": {
"upc": "2597b5a345f45e1b",
"product_type": "Books",
"price_excl_tax": "£33.34",
"price_incl_tax": "£33.34",
"tax": "£0.00",
"availability": "In stock (19 available)"
}
}Observe cómo extrajo con éxito toda la información del producto en la página, incluida la valoración de la reseña del elemento puramente visual:
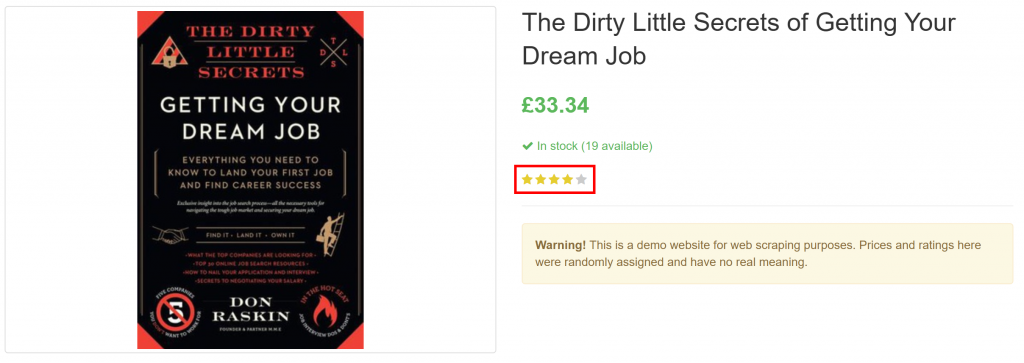
¡Et voilà! GPT Vision fue capaz de transformar una captura de pantalla en un archivo JSON perfectamente estructurado.
Próximos pasos
Para mejorar su rascador GPT Vision, considere los siguientes ajustes:
- Hazlo reutilizable: Refactoriza el script para que acepte la URL de destino, el selector CSS del elemento a esperar y el prompt LLM de la CLI. De esta forma, puedes hacer scraping de diferentes páginas sin modificar el código.
- Proteja su clave de API: En lugar de codificar su clave de API de OpenAI, guárdela en un archivo
.envy cárguelo utilizando el paquetepython-dotenv. Otra opción es establecerla como una variable de entorno global denominadaOPENAI_API_KEY. Ambos métodos ayudan a proteger tus credenciales y a mantener tu código seguro.
Superar la mayor limitación del Web Scraping visual
El principal problema de este método de raspado web reside en el paso de captura de pantalla. Aunque funcionó a la perfección en un sitio sandbox como “Books to Scrape”, los sitios web del mundo real presentan una realidad diferente.
Muchos sitios web modernos despliegan medidas anti-scraping que pueden bloquear su script antes de que pueda acceder a la página. Incluso si su scraper accede con éxito a la página, es posible que se le muestre un error o un desafío de verificación humana. Por ejemplo, esto ocurre cuando se utiliza vanilla Playwright contra sitios como G2.com:

Estos problemas pueden deberse a la huella digital del navegador, la reputación IP, la limitación de velocidad, los desafíos CAPTCHA, etc.
La forma más sólida de evitar estos bloqueos es recurrir a una API de desbloqueo web específica.
Web Unlocker de Bright Data es un potente punto final de raspado que está respaldado por una red proxy de más de 150 millones de IP. En concreto, ofrece suplantación de huellas dactilares, renderización de JavaScript, capacidades de resolución de CAPTCHA y muchas otras funciones. Incluso admite la captura de pantalla, lo que significa que puede omitir por completo la lógica de captura de pantalla manual de Playwright.
Supongamos que desea extraer la valoración media por estrellas de la página de vendedores G2 de Bright Data:
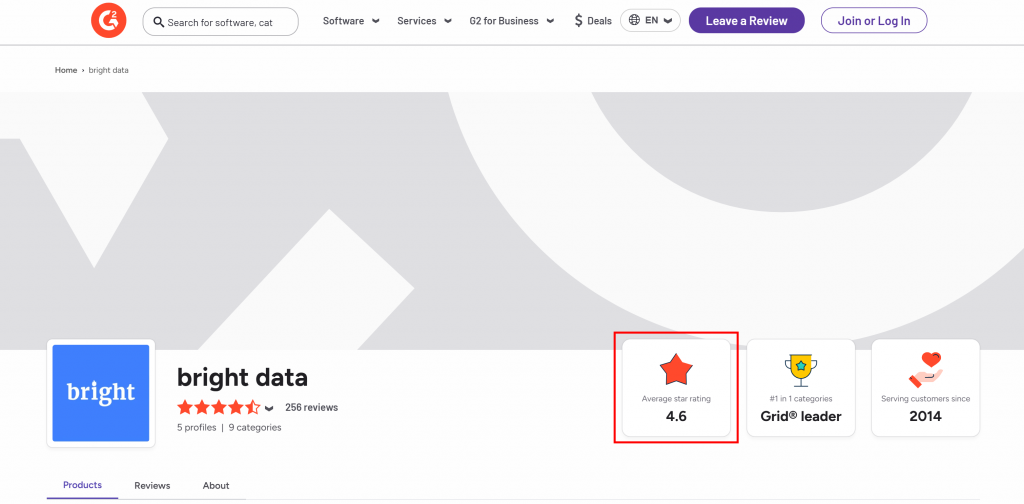
Para empezar, configure Web Unlocker como se explica en la documentación y obtenga su clave API de Bright Data. Utilice GPT Vision junto con Web Unlocker del siguiente modo:
# pip install requests
import requests
from openai import OpenAI
import base64
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace with your Bright Data API key
# Get a screenshot of the target page using Bright Data Web Unlocker
url = "https://api.brightdata.com/request"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {BRIGHT_DATA_API_KEY}"
}
payload = {
"zone": "web_unlocker", # Replace with your Web Unlocker zone name
"url": "https://www.g2.com/sellers/bright-data", # Your target page
"format": "raw",
"data_format": "screenshot" # Enable the screenshotting mode
}
response = requests.post(url, headers=headers, json=payload)
# Where to store the scraped screenshot
SCREENSHOT_PATH = "screenshot.png"
# Save the screenshot to a file (e.g., for further analysis in the future)
with open(SCREENSHOT_PATH, "wb") as f:
f.write(response.content)
# Initialize the OpenAI client
OPENAI_API_KEY = "<YOUR_OPENAI_API_KEY>" # Replace with your OpenAI API key
client = OpenAI(api_key=OPENAI_API_KEY)
# Read the screenshot file and convert its contents to Base64
with open(SCREENSHOT_PATH, "rb") as image_file:
base64_image = base64.b64encode(image_file.read()).decode("utf-8")
# Perform the scraping request using GPT Vision
response = client.responses.create(
model="gpt-4.1-mini",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": """
Return the average star rating from the following image.
"""
},
{
"type": "input_image",
"image_url": f"data:image/png;base64,{base64_image}"
}
]
}
],
)
print(response.output_text)Ejecute el script anterior, y producirá una salida como:
The average star rating from the image is 4.6.Esa información es correcta, como puede confirmar visualmente en el archivo generado screenshot.png devuelto por Web Unlocker:
Tenga en cuenta que puede utilizar Web Unlocker para recuperar el HTML completamente desbloqueado de la página, o incluso obtener su contenido en un formato Markdown optimizado para AI.
Y así de fácil: no más bloqueos, no más dolores de cabeza. Ahora tiene un raspador web GPT Vision de nivel de producción que funciona incluso en sitios web protegidos.
Vea el SDK de OpenAI y Web Unlocker trabajando juntos en un escenario de scraping más complejo.
Conclusión
En este tutorial, aprendiste cómo combinar GPT Vision con las capacidades de captura de pantalla de Playwright para construir un raspador web potenciado por IA. El mayor desafío (es decir, bloquearse al realizar capturas de pantalla) se abordó con la API Bright Data Web Unlocker.
Como ya se ha comentado, la combinación de GPT Vision con la funcionalidad de captura de pantalla proporcionada por la API de Web Unlocker permite extraer visualmente datos de cualquier sitio web. Todo ello, sin escribir código de análisis personalizado. Este es solo uno de los muchos escenarios cubiertos por los productos y servicios de IA de Bright Data.
Cree una cuenta gratuita en Bright Data y experimente con nuestras soluciones de datos.




