

El scraping web tradicional a menudo implica escribir código complejo y laborioso adaptado a diseños web específicos, que puede romperse fácilmente cuando los sitios cambian. ScrapeGraphAI utiliza modelos de lenguaje grandes (LLM) para extraer información e interpretarla como lo haría un humano, lo que le permite centrarse en los datos en lugar del diseño. La integración de LLM con ScrapeGraphAI mejora la extracción de datos, automatiza la agregación de contenido y permite el análisis en tiempo real.
En este artículo, aprenderá a utilizar ScrapeGraphAI para el Scraping web. Pero antes de eso, permítanos presentarle las soluciones de Bright Data que le permitirán ahorrar tiempo y dinero.
Soluciones de Scraping web de Bright Data
Bright Data ofrece un conjunto completo de soluciones de Scraping web, optimizadas para una extracción de datos eficiente, escalable y conforme a la normativa:
- API de web scraping
- Conjuntos de datos listos para usar
- Conjuntos de datos personalizados
Estas soluciones permiten una recopilación de datos rápida, precisa y escalable, perfecta para proyectos de cualquier alcance, desde aplicaciones a pequeña escala hasta necesidades a nivel empresarial.
Implementación del Scraping web LLM con ScrapeGraphAI
Antes de comenzar este tutorial, necesita los siguientes requisitos previos:
- Python 3.x instalado.
- Una cuenta de OpenAI. Este tutorial utiliza LLM de OpenAI para extraer datos con ScrapeGraphAI. Aunque es posible utilizar otros modelos, como Anthropic, Google o modelos de código abierto, como Llama y Mistral AI, este tutorial utiliza GPT-4 debido a su popularidad y facilidad de configuración.
Si no está familiarizado con el Scraping web en Python, consulte este tutorial de Scraping web para empezar.
Configura tu entorno
Lo primero que debe hacer es crear un entorno virtual. Abra su terminal y navegue hasta el directorio de su proyecto:
python -m venv venv
A continuación, activa el entorno virtual. En macOS y Linux, puedes hacerlo con el siguiente comando:
source venv/bin/activate
En Windows, puedes utilizar este comando:
venvScriptsactivate
Una vez que hayas activado el entorno virtual, debes instalar ScrapeGraphAI y sus dependencias:
pip install scrapegraphai
playwright install
El comando playwright install configura los navegadores necesarios para Chromium, Firefox y WebKit.
Para gestionar las variables de entorno de forma segura, instala python-dotenv:
pip install python-dotenv
Es importante proteger la información confidencial, como las claves API. Se recomienda almacenar las variables de entorno en un archivo .env para mantenerlas separadas de los archivos de código.
Cree un nuevo archivo llamado .env en el directorio del proyecto y añada la siguiente línea especificando su clave OpenAI:
OPENAI_API_KEY="su-clave-openai-api"
Este archivo no debe enviarse a sistemas de control de versiones como Git. Para evitarlo, añada .env a su archivo .gitignore.
Extraiga datos con ScrapeGraphAI
En este tutorial, comenzará por extraer datos de productos de Books to Scrape, un sitio web de demostración específico para practicar técnicas de Scraping web. Este sitio web imita una librería en línea y ofrece una variedad de libros de diferentes géneros, con precios, valoraciones y estado de disponibilidad:
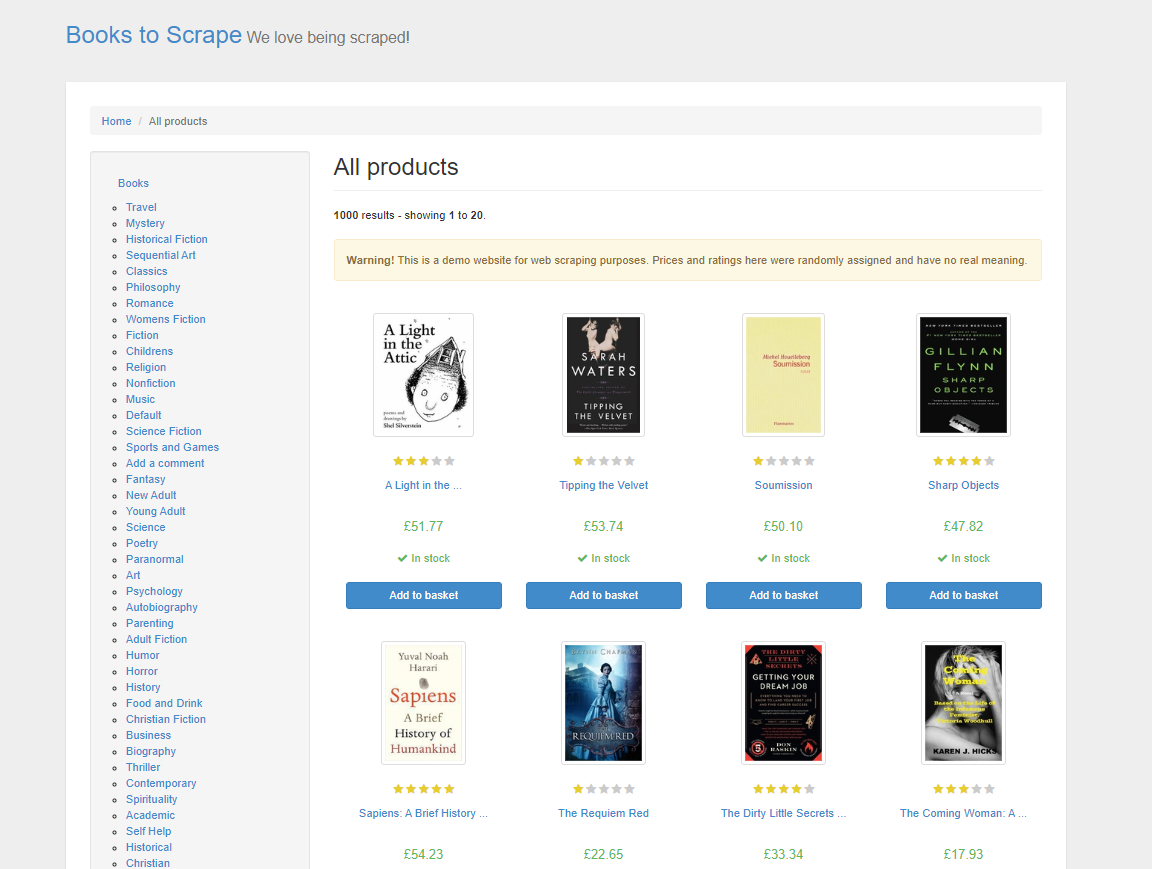
En el Scraping web HTML tradicional, sería necesario analizar el HTML de la página, inspeccionando manualmente los elementos y las etiquetas para localizar los datos que se desean. Este proceso lleva mucho tiempo y requiere un conocimiento sólido de las estructuras web. Con ScrapeGraphAI, solo hay que especificar los datos que se desean mediante un comando, y el LLM es lo suficientemente inteligente como para extraerlos.
ScrapeGraphAI ofrece diferentes tipos de gráficos para diferentes necesidades de scraping. Estos gráficos definen cómo se estructura el proceso de scraping y qué se pretende conseguir con él. A continuación se ofrece una breve descripción de algunos de los diferentes gráficos:
- SmartScraperGraph es un Scraper de una sola página en el que se proporciona un mensaje y una URL o un archivo local. Utiliza un LLM para extraer la información que se especifica.
- SearchGraph es un Scraper de varias páginas que extrae información de los resultados de los motores de búsqueda basándose en su indicación.
- SpeechGraph amplía SmartScraperGraph añadiendo una función de conversión de texto a voz, generando un archivo de audio con el contenido extraído.
- ScriptCreatorGraph toma una indicación y una URL y, en lugar de generar resultados, produce un script de Python capaz de extraer la URL dada.
Si estos gráficos no se ajustan exactamente a sus necesidades, ScrapeGraphAI también le permite crear gráficos personalizados combinando diferentes nodos y adaptando el proceso de rastreo a sus requisitos específicos.
Además de elegir el tipo de gráfico adecuado, también debe configurar correctamente su Scraper, especialmente en lo que respecta a la selección de la indicación y el modelo. La indicación guía al LLM para que comprenda exactamente qué datos extraer, así que asegúrese de que sea clara y explícita. Además, la elección del modelo LLM adecuado determina la eficacia con la que el Scraper procesa e interpreta el contenido del sitio web. También puede configurar otras opciones, como Proxies, para garantizar un rastreo más fluido del contenido con restricciones geográficas, y el modo sin interfaz para mantener la eficiencia y la rapidez del proceso. En última instancia, una configuración adecuada determina la precisión y la relevancia de los datos rastreados.
Escribir el código del Scraper
Para escribir el código del Scraper, cree un nuevo archivo llamado app.py y añádale las siguientes líneas de código:
from dotenv import load_dotenv
import os
from scrapegraphai.graphs import SmartScraperGraph
# Cargar variables de entorno desde el archivo .env
load_dotenv()
# Acceder a la clave API de OpenAI
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Configuración para ScrapeGraphAI
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
}
}
# Definir el mensaje y la fuente
prompt = "Extraer el título, el precio y la disponibilidad de todos los libros de esta página."
source = "http://books.toscrape.com/"
# Crear el gráfico del Scraper
smart_scraper_graph = SmartScraperGraph(
prompt=prompt,
source=source,
config=graph_config)
# Ejecutar el Scraper
result = smart_scraper_graph.run()
# Mostrar los resultados
print(result)
Este código importa módulos esenciales como os y dotenv para manejar variables de entorno y la clase SmartScraperGraph de ScrapeGraphAI, que se utiliza para el rastreo. A continuación, carga las variables de entorno a través de dotenv para mantener seguros los datos confidenciales, como las claves API. A continuación, el código crea una configuración LLM para el rastreo, especificando qué modelo utilizar y la clave API. Esta configuración, junto con la URL del sitio y el mensaje de rastreo, se utiliza para definir su SmartScraperGraph, que se ejecuta utilizando el método run(), lo que activa el proceso para recopilar los datos especificados.
Para ejecutar este código, abra su terminal y ejecute python app.py. El resultado debería ser similar a este:
{
"books": [
{
"title": "A Light in the Attic",
"price": "£51.77",
"availability": "In stock"
},
{
"title": "Tipping the Velvet",
"price": "£53.74",
"availability": "In stock"
}, ...
]
}
Nota: Si tienes problemas al ejecutar el código, es posible que tengas que instalar manualmente el paquete
grpcio, que es una dependencia subyacente de ScrapeGraphAI. Puedes hacerlo con el siguiente comando:
pip install grpcio
Aunque ScrapeGraphAI facilita la extracción de datos del Scraping web, sigue habiendo algunos retos comunes, como los CAPTCHA y los bloqueos de IP, que debes saber cómo manejar.
Para imitar el comportamiento de navegación, puede implementar retrasos temporizados en su código. También puede utilizar Proxy rotativo para evitar la detección. Además, los servicios de Resolución de CAPTCHA, como el solucionador de CAPTCHA de Bright Data o Anti Captcha, se pueden integrar en su Scraper para resolver automáticamente los CAPTCHA por usted.
Nota: asegúrate siempre de cumplir con los términos de servicio de un sitio web. El scraping para uso personal suele ser aceptable, pero la redistribución de datos puede tener implicaciones legales.
Uso de Proxies con ScrapeGraphAI
ScrapeGraphAI le permite configurar un servicio de Proxy para evitar el bloqueo de IP y acceder a contenido con restricciones geográficas. Puede utilizar un servicio de Proxy gratuito o configurar su propio servidor Proxy personalizado.
Para utilizar un servicio de Proxy gratuito, añada lo siguiente a su graph_config:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"Proxy": {
"server": "broker",
"criteria": {
"anonymous": True,
"secure": True,
"countryset": {"US"},
"timeout": 10.0,
"max_tries": 3
},
},
}
}
Esta configuración indica a ScrapeGraphAI que utilice un servicio Proxy gratuito que cumpla con tus criterios.
Para utilizar un servidor Proxy personalizado de un proveedor como Bright Data, modifique su graph_config de la siguiente manera, insertando la URL de su servidor, nombre de usuario y contraseña:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"Proxy": {
"server": "http://your_proxy_server:port",
"username": "your_username",
"password": "your_password",
},
}
}
El uso de un Proxy personalizado ofrece varias ventajas, especialmente para el Scraping web a gran escala. Te permite controlar la ubicación del Proxy, lo que te permite rastrear contenido con restricciones geográficas. Además, los Proxies personalizados son más fiables y seguros en comparación con los Proxies gratuitos, lo que reduce las posibilidades de que tu IP sea bloqueada o se te limite la velocidad.
Limpiar y preparar los datos
Después de extraer los datos, es necesario limpiarlos y preprocesarlos, especialmente si se planea introducirlos en un modelo de IA. La limpieza de los datos garantiza que los modelos aprendan a partir de información precisa y coherente, lo que repercute directamente en su rendimiento y fiabilidad. La limpieza de datos suele implicar el tratamiento de valores perdidos, la corrección de tipos de datos, la normalización de texto y la eliminación de duplicados.
A continuación se muestra un ejemplo de cómo se pueden limpiar los datos recopilados anteriormente utilizando pandas:
import pandas as pd
# Convertir el resultado a un DataFrame
df = pd.DataFrame(result["books"])
# Eliminar los símbolos de moneda y convertir los precios a flotantes
df['price'] = df['price'].str.replace('£', '').astype(float)
# Estandarizar el texto de disponibilidad
df['availability'] = df['availability'].str.strip().str.lower()
# Gestionar los valores que faltan, si los hay
df.dropna(inplace=True)
# Vista previa de los datos limpios
print(df.head())
Este código limpia los datos eliminando el símbolo de moneda de los precios de los libros, estandariza el estado de disponibilidad convirtiéndolo a minúsculas y gestiona los valores que faltan.
Antes de ejecutar el código, es necesario instalar la biblioteca pandas para la manipulación de datos:
pip install pandas
Para ejecutar el código, abra su terminal y ejecute python app.py. El resultado debería ser similar a este:
título precio disponibilidad
0 A Light in the Attic 51,77 en stock
1 Tipping the Velvet 53,74 en stock
2 Soumission 50,10 en stock
3 Sharp Objects 47,82 en stock
4 Sapiens: A Brief History of Humankind 54,23 en stock
Esto es solo un ejemplo de cómo se pueden limpiar los datos recopilados; el proceso de limpieza varía en función de los datos y del caso de uso del LLM que se esté entrenando. Al limpiar los datos, se garantiza que los modelos de lenguaje reciban entradas bien estructuradas y significativas. Si desea obtener más información sobre cómo utilizar los datos para proyectos de IA, considere los datos para IA.
Todo el código de este tutorial está disponible en este repositorio de GitHub.
Conclusión
ScrapeGraphAI utiliza LLM para proporcionar un enfoque adaptativo al Scraping web, ajustándose a los cambios en las estructuras de los sitios web y extrayendo datos de forma inteligente. Sin embargo, el Scraping web a gran escala conlleva retos, como el bloqueo de IP, la resolución de CAPTCHA y el cumplimiento de la normativa legal.
Para ayudar a superar estos retos, Bright Data ofrece un conjunto completo de soluciones de Scraping web adaptadas a proyectos de IA y aprendizaje automático. Esto incluye las API de Bright Data Web Scraper, los servicios de Proxy y el scraping sin servidor. Además, Bright Data también ofrece conjuntos de datos listos para usar con datos para IA y aprendizaje automático de más de un centenar de sitios web populares.
¡Comience hoy mismo su prueba gratuita!





