

En este artículo aprenderás:
- Qué es la validación de datos, cuándo utilizarla, las comprobaciones que implica y qué bibliotecas debe utilizar para implementarla.
- Cómo realizar la validación de datos con un ejemplo real en Python.
- Qué es la verificación de datos, cómo funciona, ejemplos de comprobaciones de verificación y los mejores enfoques.
- Cómo implementar la verificación de datos utilizando un agente de IA dedicado.
- Una tabla resumen que compara la validación de datos con la verificación de datos.
¡Empecemos!
Validación de datos: todo lo que necesita saber
Comience este recorrido por la validación y la verificación de datos explorando el primer enfoque: la validación de datos.
¿Qué es la validación de datos y por qué es importante?
La validación de datos es el proceso de comprobar la precisión, la calidad y la integridad de los datos. Normalmente se lleva a cabo antes de almacenar, utilizar o procesar los datos. Su objetivo final es garantizar un nivel constante de calidad y confianza.
En concreto, esta técnica verifica que los datos sigan las normas y estándares definidos. Evita que la información incorrecta o incompleta entre en un sistema, aplicación o flujo de trabajo, o que continúe a través de un canal de datos.
La validación de datos es fundamental para mantener una alta calidad de los datos. La validación de datos también desempeña un papel importante en el cumplimiento de requisitos normativos como el RGPD y la CCPA, así como en el seguimiento de las mejores prácticas de seguridad.
Al aplicar la validación de datos, se pueden detectar errores y problemas en los datos de forma temprana. Esto ayuda a identificar problemas en el ciclo de vida de los datos antes de que se agraven, lo que evita errores costosos y complicaciones graves.
Ejemplos de comprobaciones de validación de datos
Las comprobaciones de validación de datos que puede aplicar son innumerables y dependen de sus necesidades específicas, del tipo de campos de datos y de escenarios concretos. Algunas de las comprobaciones más importantes son:
- Comprobación del tipo de datos: confirma que los datos introducidos en un campo son del tipo correcto (por ejemplo, garantiza que un campo
de edadsolo acepte números). - Comprobación del formato: verifica que los datos se ajustan a un patrón específico, como el formato de un número de teléfono
(XXX) XXX-XXXX, el formato de una fechaAAAA-MM-DDo el formato de un correo electrónico[email protected]. - Comprobación de rango: garantiza que un valor numérico se encuentre dentro de un rango mínimo y máximo predefinido (por ejemplo, un campo
de puntuacióndebe estar entre0y100). - Comprobación de presencia: confirma que un campo obligatorio no se ha dejado en blanco o nulo, asegurándose de que no falte ninguna información crítica.
- Comprobación de código: valida que una entrada se seleccione de una lista predefinida de valores aceptables (por ejemplo, un código de país de la lista ISO 3166).
- Comprobación de coherencia: verifica que los datos de varios campos dentro de la misma entrada o de diferentes entradas sean lógicos y coherentes (por ejemplo, la fecha de un pedido debe ser anterior a la fecha de entrega).
- Comprobación de unicidad: evita entradas duplicadas en campos que requieren valores únicos, como el ID de empleado o la dirección de correo electrónico.
Cuándo realizarla
Como regla general, la validación de datos debe realizarse de forma continua a lo largo del ciclo de vida de los datos. Al mismo tiempo, cuanto antes se realice, más eficazmente se evitará que los errores se propaguen. Esto se conoce como enfoque «shift-left» (desplazamiento hacia la izquierda) de la calidad de los datos.
Por lo tanto, el momento más proactivo y eficiente para validar los datos es en el momento de su introducción. Detectar los errores en ese momento garantiza que los datos erróneos nunca entren en sus sistemas, lo que ahorra tiempo y recursos en la limpieza posterior. Esto se aplica a los datos introducidos por los usuarios (por ejemplo, a través de formularios o cargas de archivos), los datos recuperados mediante Scraping web o los datos de repositorios públicos o abiertos en los que no se confía plenamente.
En el caso de los datos enviados por los usuarios, por ejemplo, a través de una API en un sistema backend, la validación en tiempo real puede proporcionar información inmediata (por ejemplo, señalando una dirección de correo electrónico con formato incorrecto o un número de teléfono incompleto directamente en la respuesta de la API con errores400 Bad Request).
Sin embargo, no siempre es posible validar los datos de forma inmediata. Por ejemplo, en los procesos ETL o ELT, la validación se aplica generalmente en etapas específicas:
- Después de la extracción: para comprobar que los datos extraídos de un sistema de origen no se han dañado o perdido durante el tránsito.
- Después de la transformación: para verificar que el resultado de cada paso de la transformación (por ejemplo, las agregaciones) cumple con las reglas y normas esperadas.
Incluso después de almacenar los datos, debe volver a verificarlos periódicamente. Esto se debe a que los datos no son estáticos, ya que pueden actualizarse, enriquecerse o reutilizarse. Por lo tanto, es necesario realizar una validación continua.
Cómo validar los datos
El proceso de validación de datos implica los siguientes pasos:
- Definir los requisitos: establecer reglas de validación claras basadas en las necesidades empresariales, las normas reglamentarias y las expectativas (por ejemplo, definir un esquema con reglas para los datos).
- Recopilar datos: recopile datos de diversas fuentes, como el Scraping web, las API o las bases de datos.
- Aplicar la validación: implemente las reglas definidas para comprobar la exactitud, coherencia e integridad de los datos.
- Gestionar los errores: registrar, poner en cuarentena o corregir los registros no válidos de acuerdo con las políticas de la organización. Proporcionar a los usuarios información clara cuando introduzcan datos incorrectos.
- Cargar datos: una vez que los datos estén validados y limpios, cárguelos en el sistema de destino, como un almacén de datos.
Nota: En el siguiente capítulo verá cómo aplicar estos pasos mediante un ejemplo guiado en Python.
Bibliotecas para la validación de datos
A continuación se muestra una tabla con algunas de las mejores bibliotecas de código abierto para la validación de datos:
| Biblioteca | Lenguaje de programación | Estrellas de GitHub | Descripción |
|---|---|---|---|
| Pydantic | Python | Más de 25,3 mil | Validación de datos mediante sugerencias de tipos de Python |
| Marshmallow | Python | 7,2k+ | Una biblioteca ligera para convertir objetos complejos a y desde tipos de datos Python simples. |
| Cerberus | Python | 3,2k+ | Biblioteca ligera y extensible para la validación de datos en Python. |
| jsonschema | Python | 4,8k+ | Una implementación de la especificación JSON Schema para Python |
| Validator.js | JavaScript | 23,6k+ | Una biblioteca de validadores y limpiadores de cadenas. |
| Joi | JavaScript | 21,2k+ | La biblioteca de validación de datos más potente para JS |
| Yup | JavaScript | 23,6k+ | Validación de esquemas de objetos muy sencilla |
| Ajv | JavaScript | 14,4k+ | El validador de esquemas JSON más rápido. Compatible con JSON Schema draft-04/06/07/2019-09/2020-12 y JSON Type Definition (RFC8927) |
| FluentValidation | C# (.NET) | 9,5k | Una popular biblioteca de validación .NET para crear reglas de validación fuertemente tipadas. |
| validator | Go | 19,1k+ | Validación de estructuras y campos Go, incluyendo campos cruzados, estructuras cruzadas, mapas, segmentos y matrices. |
Cómo aplicar la validación de datos en Python: ejemplo paso a paso
En este tutorial guiado, aprenderás a aplicar la validación de datos a los datos de entrada en JSON utilizando Pydantic. Este tutorial cubrirá los aspectos principales de la creación de un proceso para validar datos.
Descripción del escenario
Supongamos que estás recuperando datos de un sitio de comercio electrónico. En concreto, céntrate en esta página web de productos:
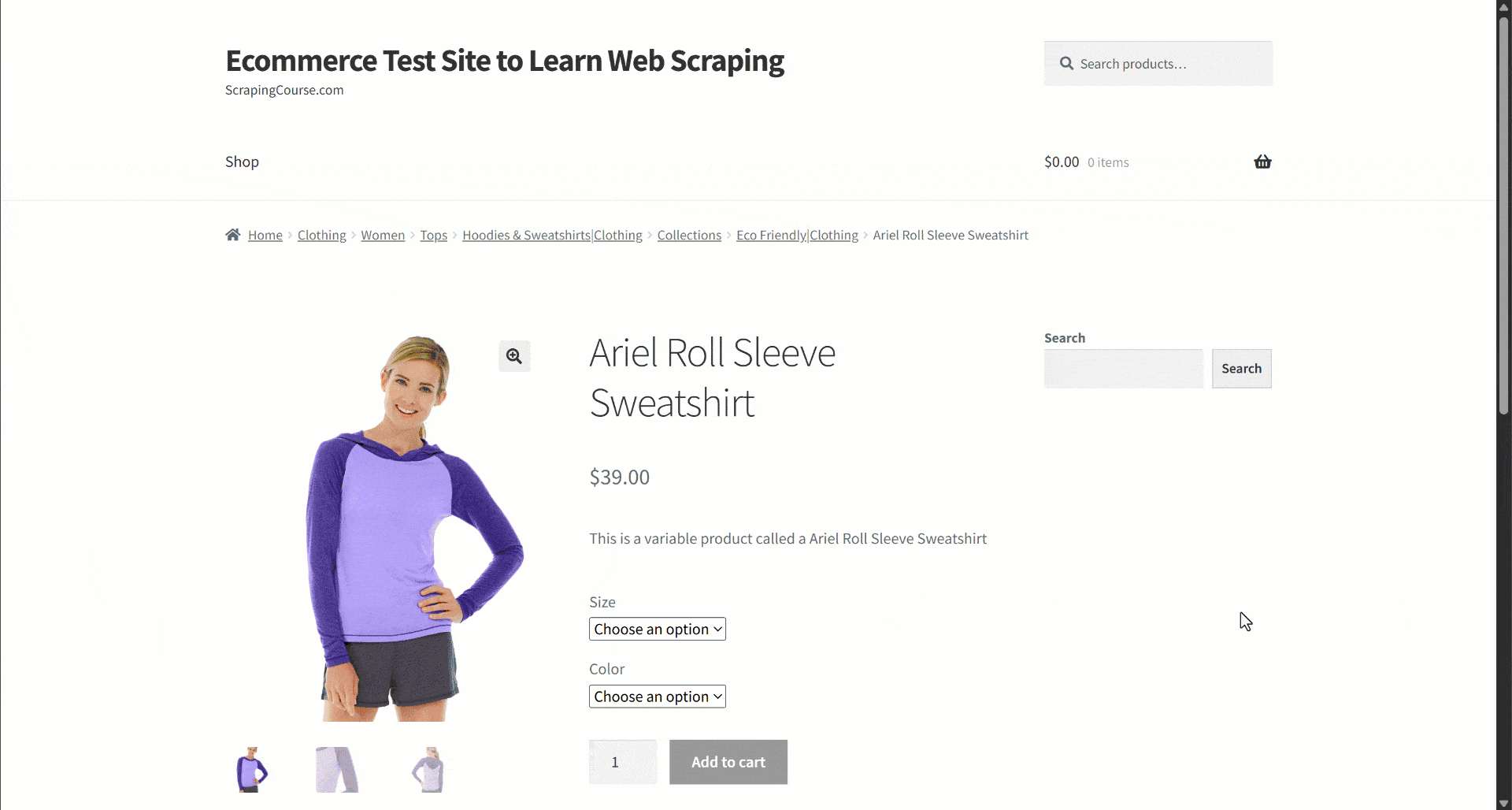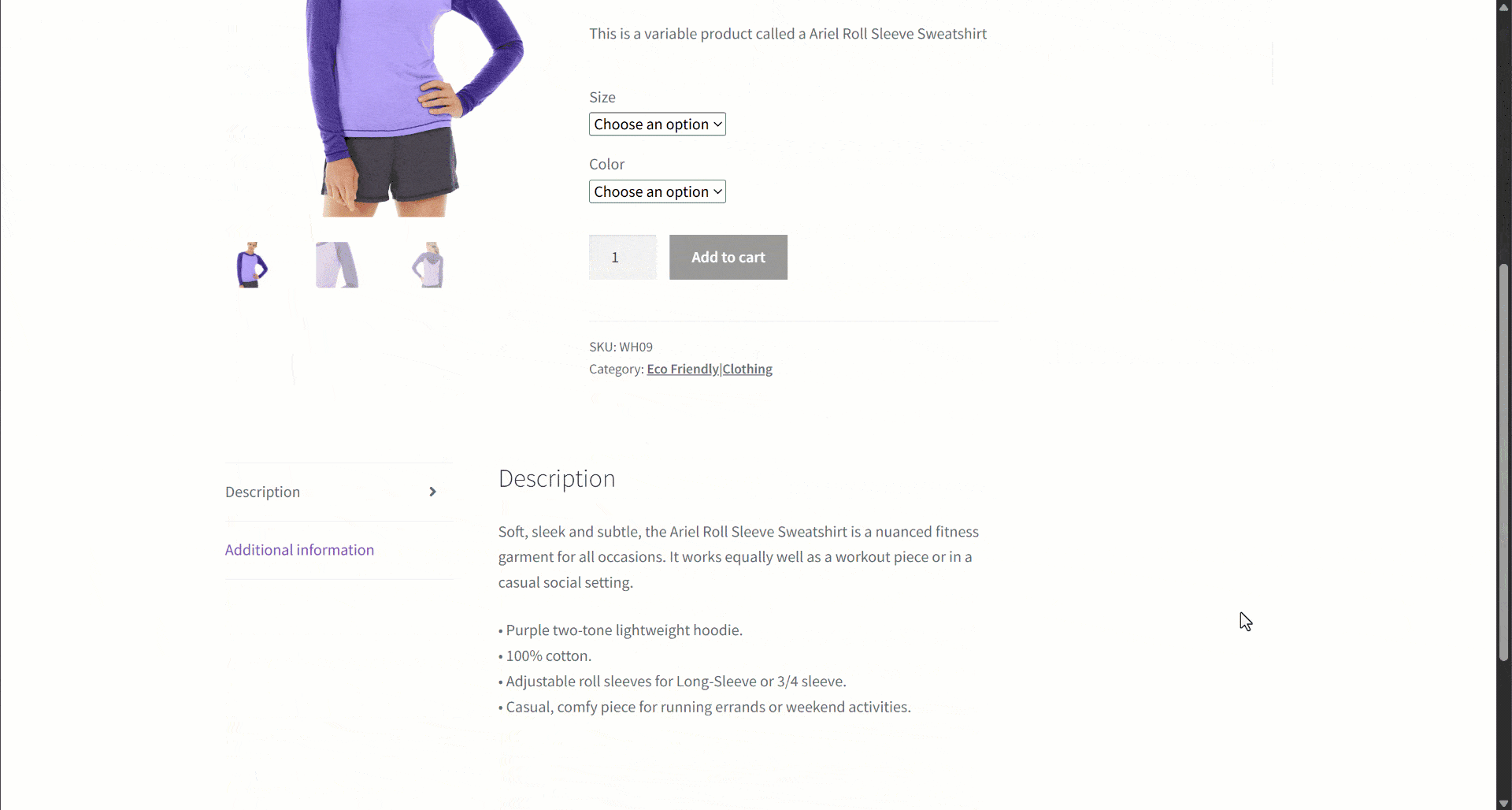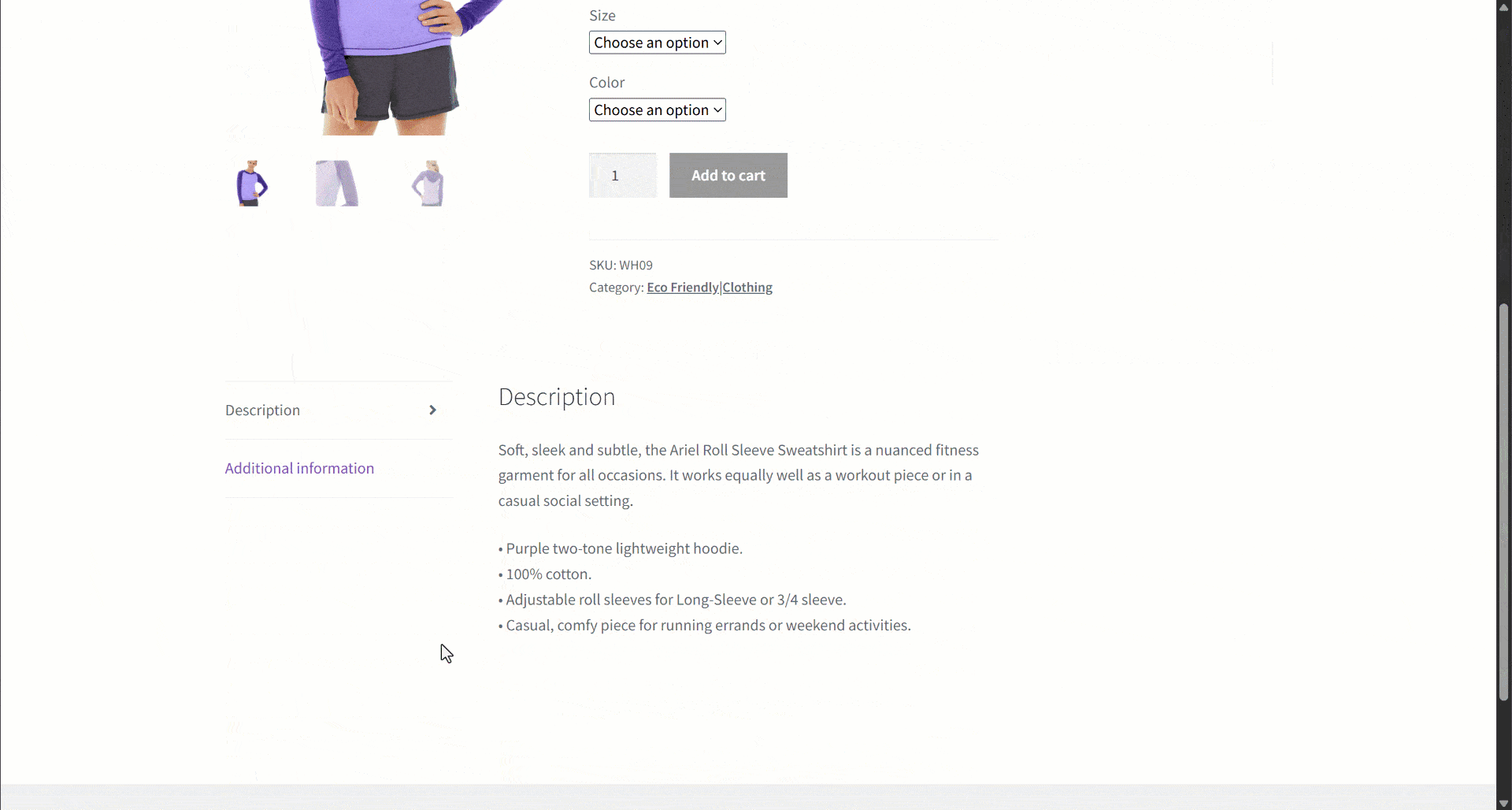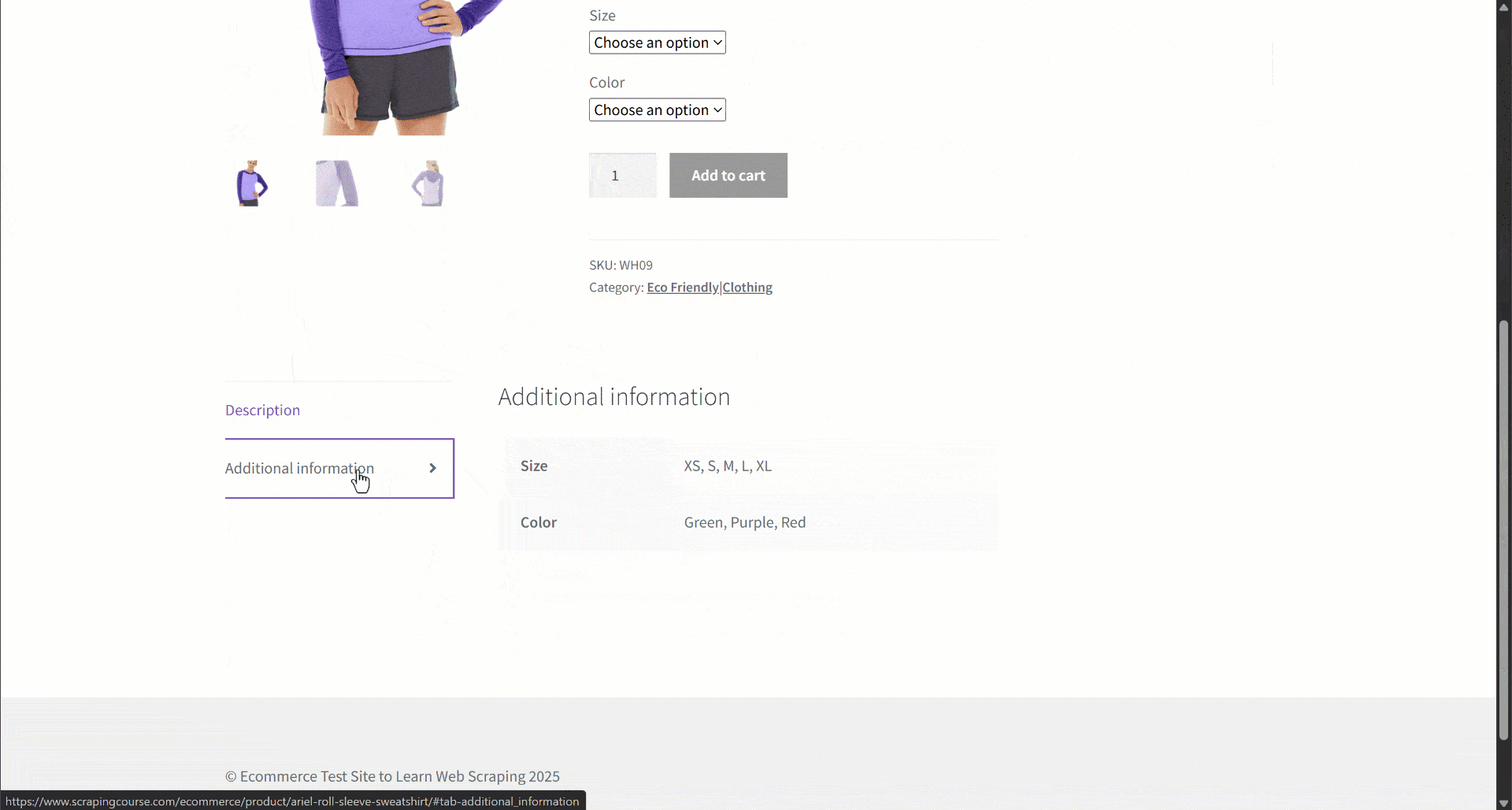
Durante la extracción de datos, usted proporciona el contenido de la página a un LLM para simplificar el parseo de datos. Ahora bien, los LLM pueden ser imprecisos y pueden producir datos inventados, poco fiables o incompletos. Por eso es tan importante aplicar la validación de datos.
Para simplificar, supondremos que ya tiene un proyecto Python con un entorno de desarrollo configurado.
Paso n.º 1: definir el esquema y las reglas de destino
Comience por inspeccionar la página de destino y observe que la página del producto contiene los siguientes campos:
- URL del producto: la URL de la página del producto.
- Nombre del producto: una cadena que contiene el nombre del producto.
- Imágenes: una lista de URL de imágenes.
- Precio: el precio como número flotante.
- Moneda: un solo carácter que representa la moneda.
- SKU: Una cadena que contiene el ID del producto.
- Categoría: una matriz que contiene una o más categorías.
- Descripción: un campo de texto con la descripción del producto.
- Descripción larga: campo de texto que contiene la descripción completa del producto con todos los detalles.
- Información adicional: un objeto que contiene:
- Opciones de tamaño: una matriz de cadenas con los tamaños disponibles.
- Opciones de color: una matriz de cadenas con los colores disponibles.
A continuación, represéntelo en un modelo Pydantic como se muestra a continuación:
# pip install pip install pydantic
from typing import List, Optional, Annotated
from pydantic import BaseModel, ConfigDict, HttpUrl, PositiveFloat, StringConstraints, model_validator
class AdditionalInformation(BaseModel):
size_options: Optional[List[str]] = None # nullable
color_options: Optional[List[str]] = None # nullable
class Product(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
product_url: HttpUrl # obligatorio, debe ser una URL válida
product_name: str # obligatorio
images: Optional[List[HttpUrl]] = None # lista de URL válidas, nulo
price: Optional[PositiveFloat] = None # nulo, debe ser >= 0
currency: Optional[Annotated[str, StringConstraints(min_length=1, max_length=1)]] = None # nulo, un solo carácter
sku: str # obligatorio
category: Optional[List[str]] = None # anulable
description: Optional[str] = None # anulable
long_description: Optional[str] = None # anulable
additional_information: Optional[AdditionalInformation] = None # anulable
@model_validator(mode="after")
# Regla de validación personalizada para garantizar que el precio siempre esté asociado a una moneda
def check_currency_if_price(cls, values):
price = values.price
currency = values.currency
if price is not None and not currency:
raise ValueError("currency must be provided if price is set")
return valuesTenga en cuenta que el modelo Product no solo define los campos y sus tipos (por ejemplo, str, HttpUrl, etc.), sino que también incluye restricciones de validación (por ejemplo, la moneda debe ser un solo carácter). Además, incluye reglas de validación estrictas para garantizar que el precio siempre esté asociado a una moneda, y se prohíben los campos adicionales que no coincidan directamente con el modelo.
Paso n.º 2: Recopilar los datos
Supongamos que recupera datos mediante el Scraping web con IA, como se muestra en uno de los tutoriales siguientes:
- Scraping web con ChatGPT: tutorial paso a paso
- Scraping web con Gemini: tutorial completo
- Scraping web con Perplexity: guía paso a paso
- Scraping web con Claude: Parseo basado en IA en Python
Obtendrá un archivo product.json que contiene los datos extraídos. Aquí, supondremos que el LLM lo ha rellenado así:
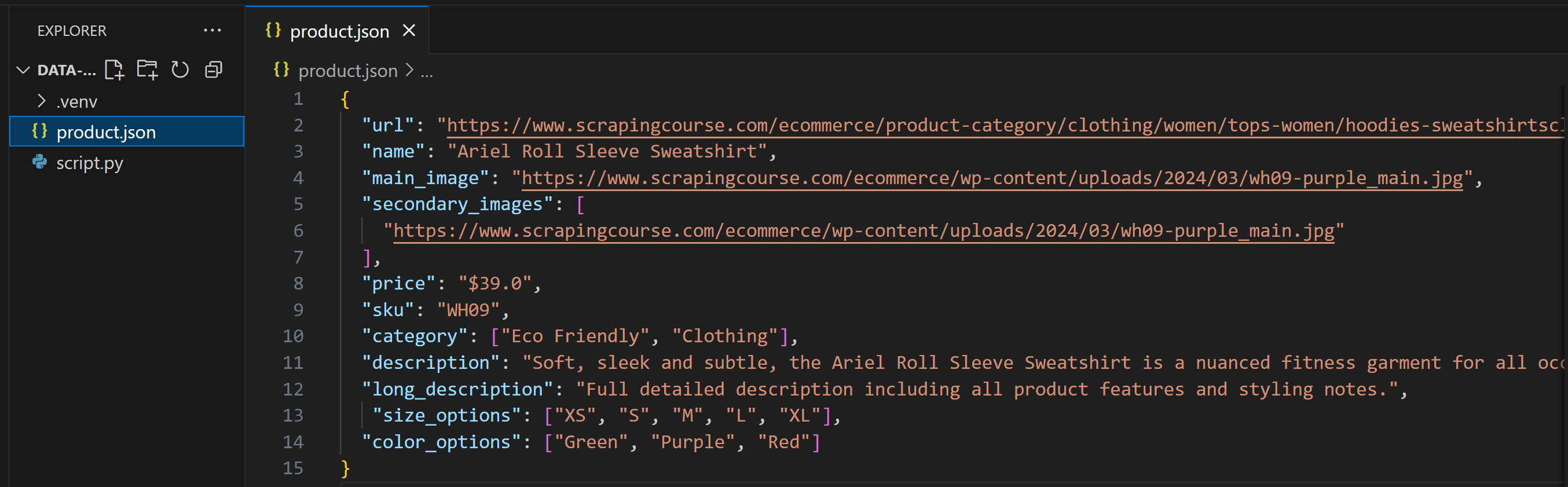
Como puede ver, este resultado no coincide exactamente con el modelo Pydantic. Esto es habitual si no se especifica explícitamente una estructura de salida en la solicitud o si la IA está configurada con una temperatura demasiado alta.
Paso n.º 3: Aplicar las reglas de validación
Cargue los datos del archivo product.json:
import json
input_data_file_name = "product.json"
with open(input_data_file_name, "r", encoding="utf-8") as f:
product_data = json.load(f)A continuación, valídelos con Pydantic de la siguiente manera:
try:
# Valida los datos a través del modelo Pydantic.
product = Product(**product_data)
print("¡Validación correcta!")
except ValidationError as e:
print("Validación fallida:")
print(e)Ejecute su script y obtendrá un resultado de error como este:
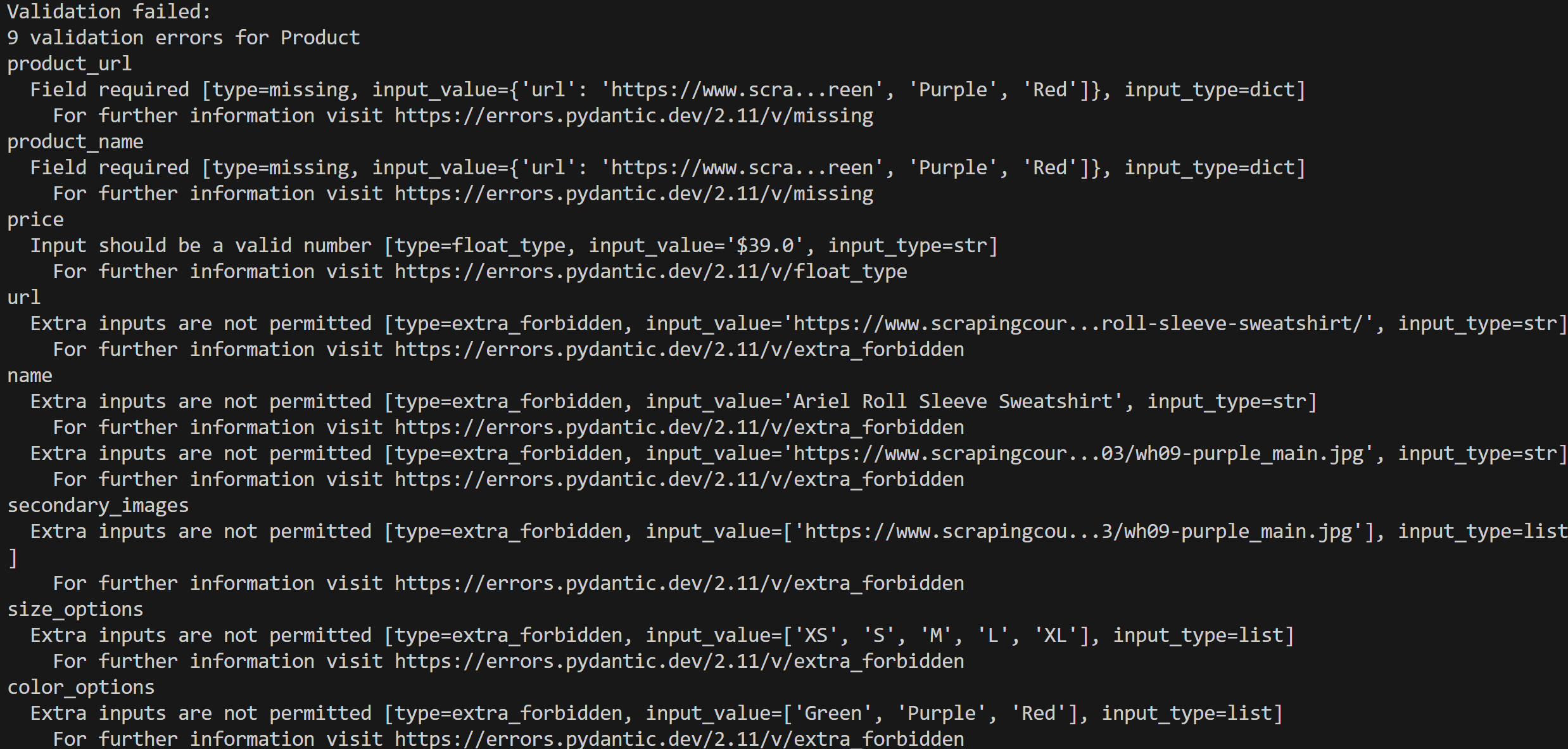
En este caso, se detectaron 9 errores de validación porque los datos de entrada no se ajustan al modelo Product.
Paso n.º 4: Corregir los errores
Ahora bien, no existe un proceso universal para corregir automáticamente los datos de modo que superen la etapa de validación. Cada canal de datos o flujo de trabajo es diferente, y es posible que tengas que intervenir en diferentes aspectos del mismo.
En este caso, la solución es tan sencilla como especificar claramente el formato de salida esperado en la indicación del LLM, una función compatible con la mayoría de los LLM, como OpenAI.
Consejo: Puede ver esa función en acción en nuestra guía sobre el Scraping web visual con GPT Vision.
De lo contrario, si la función de salida estructurada no está disponible, siempre puede pedir al LLM que coincida con el modelo Pydantic esperado en el prompt volcándolo como una cadena JSON:
prompt = f"""
Extraiga los datos del contenido de la página dada y devuélvalos con la siguiente estructura:
{Product.model_json_schema()}
CONTENIDO:
<contenido de la página>
"""En ambos casos, la salida del LLM debe coincidir con el formato esperado.
Después de realizar este cambio, product.json contendrá:
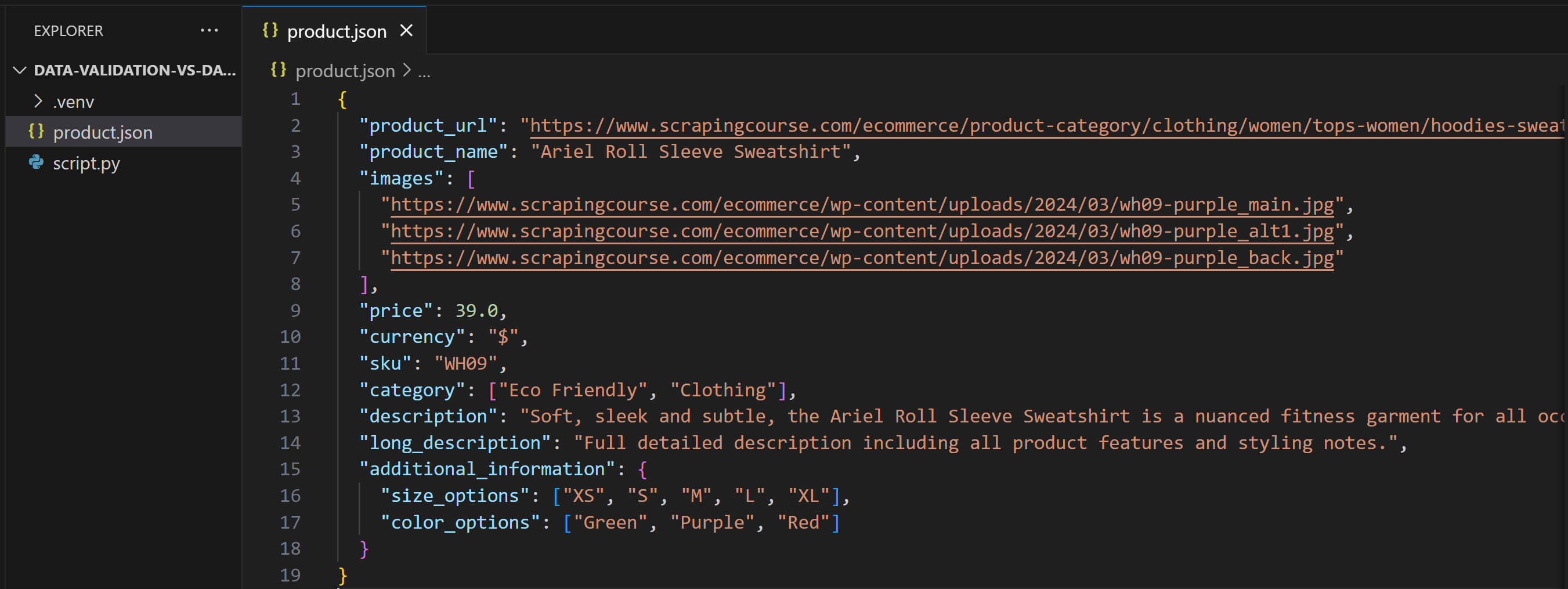
Esta vez, cuando ejecute el script, producirá:

¡Genial! La validación de datos se ha realizado correctamente. Una vez validados los datos, puede proceder a procesarlos, almacenarlos en una base de datos o realizar otras operaciones.
Verificación de datos: explicación de los conceptos básicos
Continuemos con esta guía sobre la validación y la verificación de datos centrándonos en la segunda técnica: la verificación de datos.
¿Qué es la verificación de datos y por qué es importante?
La verificación de datos es el proceso de comprobar que los datos son precisos y reflejan hechos del mundo real. Esto se hace comparando la información con fuentes fidedignas.
A diferencia de la validación de datos, que solo comprueba si los datos cumplen con reglas predefinidas (por ejemplo, si una dirección de correo electrónico tiene el formato correcto), la verificación confirma que los datos son veraces y se corresponden con la realidad (por ejemplo, que el correo electrónico existe realmente y pertenece a la persona deseada).
La verificación de datos es fundamental para garantizar la calidad de los mismos, especialmente en lo que respecta al significado de la información. Al fin y al cabo, incluso los datos bien estructurados y aparentemente limpios pueden contener información errónea. Confiar en datos inexactos puede dar lugar a errores costosos, decisiones erróneas, malas experiencias de los clientes e ineficiencias operativas.
Ejemplos de comprobaciones de verificación de datos
La verificación de datos puede ser complicada, y el enfoque adecuado depende en gran medida de los datos de entrada y del ámbito en el que se opera. No obstante, algunos métodos de verificación comunes son:
- Verificación automatizada: uso de software especializado, servicios de terceros o sistemas de IA agentica para cotejar los datos con fuentes fiables.
- Revisión: revisión manual de documentos, datos o campos de datos para asegurarse de que contienen información precisa. Esto puede hacerse manualmente por personas que utilizan sus conocimientos sobre un tema, o automáticamente mediante IA.
- Doble entrada: dos sistemas independientes (o agentes de IA autónomos) introducen de forma independiente datos sobre el mismo tema. A continuación, se comparan los registros y se señalan las discrepancias para su revisión o corrección.
- Verificación de los datos de origen: comparar los datos almacenados en una base de datos con los documentos originales (por ejemplo, los historiales médicos de los pacientes) para confirmar que coinciden.
Cuándo hacerlo
La verificación de datos debe realizarse siempre que no se confíe plenamente en la fuente de los datos. Un ejemplo común es cuando se utiliza la IA para generar o enriquecer datos, lo que puede producir información aparentemente plausible pero inexacta.
Otro caso en el que la verificación de datos es importante es cuando los datos se han transferido o almacenado, por ejemplo, durante migraciones o consolidaciones. Después de estas tareas, es necesario asegurarse de que los datos resultantes siguen siendo precisos. La verificación de datos también es relevante como parte del mantenimiento continuo de la calidad de los datos.
Tenga en cuenta que la verificación de datos suele seguir a la validación de datos. Si la estructura de los datos no coincide con el formato esperado, la verificación no tiene sentido, ya que es posible que los datos no sean utilizables en su totalidad. Solo después de que los datos superen la validación tiene sentido proceder a la verificación.
La verificación de datos es sin duda más compleja que la validación, ya que no se pueden obtener resultados deterministas (como se ha demostrado anteriormente con un sencillo script de Python). Esto se debe a que es muy difícil determinar con absoluta certeza si la información es verdadera.
Principales enfoques para la verificación de datos
Cuando se trata de contenido enviado por los usuarios, la mejor forma de verificarlo es mediante la verificación humana. Algunos ejemplos son:
- Verificación del correo electrónico: después de que un usuario introduce una dirección de correo electrónico durante el registro, se envía un correo electrónico automático con un enlace o código de confirmación para garantizar que la dirección es válida y accesible.
- Verificación del número de teléfono: se envía una contraseña de un solo uso (OTP) mediante un mensaje de texto o una llamada telefónica para confirmar que el número es válido, está activo y pertenece al usuario.
Del mismo modo, se puede pedir a los usuarios que envíen documentos o facturas para verificar su identidad o dirección. Estos documentos se pueden procesar con sistemas OCR para verificar que los datos introducidos por el usuario coinciden con la información de los documentos cargados. Aunque este método sigue siendo vulnerable al fraude, es muy útil para aumentar la fiabilidad de los datos.
El verdadero reto surge cuando se recuperan datos públicos de la web, la fuente de información más grande y menos estructurada. En este caso, es difícil determinar si la información es correcta. El enfoque general consiste en dar prioridad a las fuentes fiables (por ejemplo, documentación, declaraciones oficiales) y, dada cierta información, rastrear su origen, cotejarla en línea con fuentes fiables y comparar los resultados.
Hacerlo manualmente lleva mucho tiempo, por lo que muchas de estas tareas se automatizan ahora mediante agentes de IA equipados con herramientas para la búsqueda y el Scraping web.
Cómo verificar datos: ejemplo en Python
En esta sección, encontrará un ejemplo paso a paso de cómo crear un agente de IA para la verificación de datos. El agente hará lo siguiente:
- Tomará un texto de muestra como entrada.
- Pasará la información a un LLM ampliado con herramientas de búsqueda y Scraping web.
- Pedirá a la IA que identifique los temas principales del texto de origen y busque en Google páginas relevantes y fiables para verificar la exactitud.
- Extraerá información de esas páginas y la comparará con el texto de origen.
- Devolverá un informe indicando si los datos son precisos y, en caso contrario, sugerirá cómo solucionarlo.
Este tipo de flujo de trabajo no sería posible sin una infraestructura preparada para la IA que admita la recuperación de datos web, la búsqueda, la interacción y mucho más, como la que proporciona la infraestructura de IA de Bright Data.
Para facilitar la integración, utilizaremos Bright Data Web MCP, que ofrece más de 60 herramientas. En concreto, su nivel gratuito incluye estas dos herramientas:
search_engine: recupera los resultados de búsqueda de Google, Bing o Yandex en JSON o Markdown.scrape_as_markdown: extrae cualquier página web en formato Markdown limpio, evitando la detección de bots y CAPTCHA.
¡Estas dos herramientas son suficientes para impulsar el agente de verificación de datos y lograr el objetivo!
Descripción del escenario
Supongamos que tienes algunos datos de entrada en un archivo summary.txt que deseas verificar para comprobar su corrección. Por ejemplo, este contiene un breve resumen de la Super Bowl LIX:

Creará un agente de verificación de datos utilizando LangChain integrado con Web MCP. Para seguir los pasos, necesitará:
- Python instalado localmente.
- Un proyecto LangChain configurado.
- Una clave API de Bright Data para autenticar su conexión a Web MCP.
- Una clave API de OpenAI.
Antes de empezar, revisa nuestro tutorial sobre el uso del adaptador LangChain MCP para la integración con Web MCP de Bright Data. Si prefieres utilizar otros marcos o herramientas, consulta estas guías:
- Creación de agentes de Scraping web con CrewAI y el protocolo de contexto de modelo (MCP) de Bright Data
- Creación de un chatbot CLI con LlamaIndex y MCP de Bright Data
- Integración de Claude Code con Web MCP de Bright Data
- Cómo crear un chatbot RAG con GPT-4o utilizando datos SERP
Creación de un agente de IA para la verificación de datos
Así es como se puede crear el agente de verificación de datos utilizando LangChain y el MCP web de Bright Data:
# pip install langchain["openai"] langchain-mcp-adapters langgraph
import asyncio
import os
os.environ["OPENAI_API_KEY"] = "<TU clave API de OpenAI>" # Reemplaza con tu clave API de OpenAI
from langchain_openai import ChatOpenAI
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from langchain_mcp_adapters.tools import load_mcp_tools
from langgraph.prebuilt import create_react_agent
async def main():
# Cargar los datos de entrada para verificar
input_file_name = "summary.txt"
with open(input_file_name, "r", encoding="utf-8") as f:
summary_data_to_verify = f.read()
# Inicializar el motor LLM
llm = ChatOpenAI(
model="gpt-5-nano",
)
# Configuración para conectarse a una instancia local del servidor Bright Data Web MCP
server_params = StdioServerParameters(
command="npx",
args=["-y", "@brightdata/mcp"],
env={
"API_TOKEN": "<YOUR_BRIGHT_DATA_API_KEY>", # Reemplazar con su clave API de Bright Data
}
)
# Conectarse al servidor MCP
async with stdio_client(server_params) as (read, write):
async with ClientSession(read, write) as session:
# Inicializar la sesión del cliente MCP
await session.initialize()
# Obtener las herramientas MCP
tools = await load_mcp_tools(session)
# Crear el agente ReAct
agent = create_react_agent(llm, tools)
# Descripción de la tarea del agente
input_prompt = f"""
Dado el contenido de entrada que se muestra a continuación, realice los siguientes pasos:
1. Identifique el tema principal como una consulta de búsqueda similar a la de Google y utilícelo para realizar una búsqueda en la web y recopilar información al respecto.
2. De los resultados de la búsqueda, seleccione las 2/3 fuentes más fiables (por ejemplo, sitios de noticias de confianza, revistas, publicaciones oficiales).
3. Extraiga el contenido de las páginas seleccionadas.
4. Compare la información extraída con el contenido de entrada para determinar si es precisa.
5. Si no es precisa, elabore un informe en el que se enumeran todos los errores encontrados en el contenido de entrada, junto con la información corregida y los enlaces a las fuentes de apoyo.
Contenido de entrada:
{summary_data_to_verify}
"""
# Transmitir la respuesta del agente
async for step in agent.astream({"messages": [input_prompt]}, stream_mode="values"):
step["messages"][-1].pretty_print()
if __name__ == "__main__":
asyncio.run(main())Céntrate en la indicación en sí, ya que es la parte más importante del script anterior.
Ejecuta el agente
Inicie su agente y verá que identifica correctamente el tema principal como «Super Bowl LIX». A continuación, ejecutará una búsqueda en Google utilizando la herramientasearch_engine de Web MCP:

A partir de los resultados de la SERP, identifica los artículos de ESPN y CBS Sports como fuentes principales y los extrae utilizando la herramienta scrape_as_markdown:
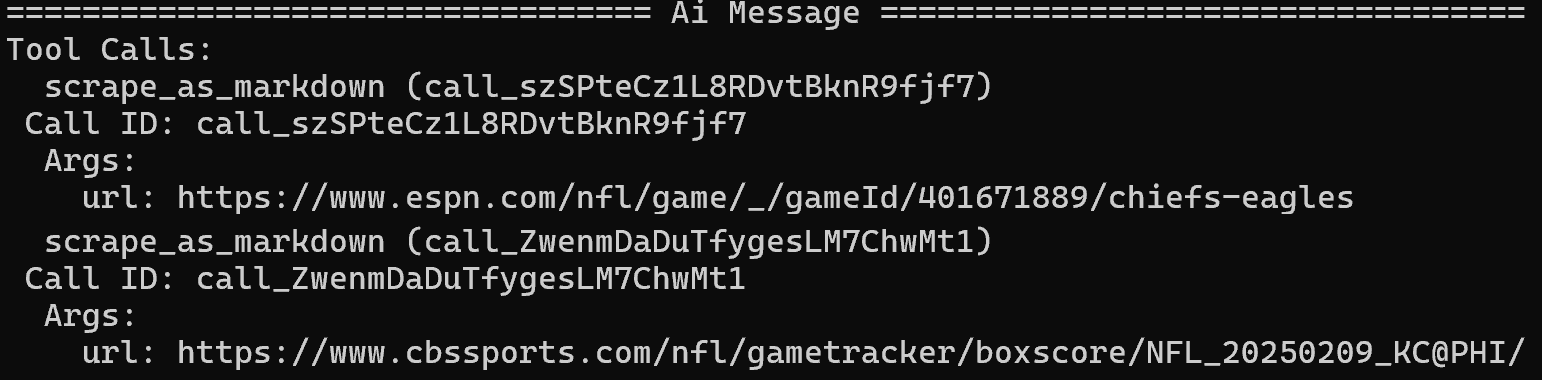
Después de extraer el contenido de las tres fuentes de noticias, produce el siguiente informe Markdown:
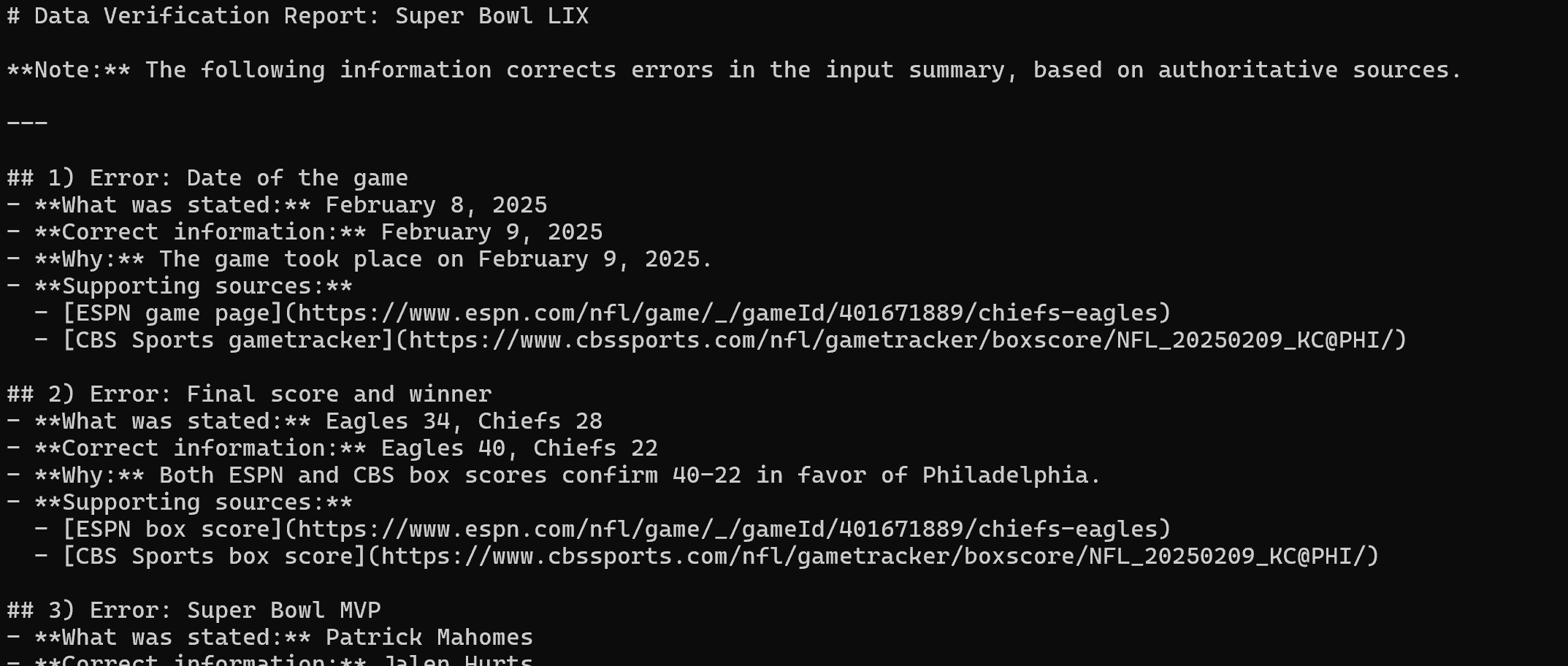
Renderícelo en Visual Studio Code y verá el informe final.
Como puede ver, gracias a las capacidades de búsqueda web y Scraping web de Web MCP, el agente LangChain pudo identificar todos los errores del texto original incorrecto. ¡Misión cumplida!
Validación de datos frente a verificación de datos: tabla resumen
Compare las dos técnicas en la tabla resumen de validación de datos frente a verificación de datos que se muestra a continuación:
| Aspecto | Validación de datos | Verificación de datos |
|---|---|---|
| Definición | Comprueba la exactitud, calidad e integridad de los datos con respecto a reglas y normas predefinidas antes de su uso o almacenamiento. | Confirma que los datos reflejan con precisión los hechos del mundo real comparándolos con fuentes fidedignas. |
| Objetivo | Garantiza que los datos se ajustan a los formatos, tipos, rangos y normas esperados; evita que los datos erróneos entren en los sistemas. | Garantiza que los datos sean veraces, precisos y fiables para la toma de decisiones. |
| Momento | Se realiza en el momento de la entrada, después de la extracción, después de la transformación o periódicamente. | Se realiza después de la validación o cuando la fiabilidad de la fuente de datos es incierta; normalmente después de la recopilación o transferencia de datos. |
| Complejidad | Relativamente sencillo; comprobaciones deterministas basadas en reglas definidas. | Más compleja; puede implicar incertidumbre, fuentes externas y revisión manual; resultados no deterministas posibles. |
| Ejemplo | el precio debe ser ≥ 0 |
Verificar que el precio coincide con el listado oficial de la tienda |
Comentario final
Como ha aprendido en esta entrada del blog sobre validación de datos frente a verificación de datos, la validación y la verificación de datos abordan dos tareas diferentes pero complementarias. En particular, ambas contribuyen a lograr una alta calidad de los datos. Otro punto similar es que pasar por alto cualquiera de ellas puede causar problemas importantes en los procesos basados en datos, que sustentan la mayoría de las operaciones empresariales.
Por eso es realmente indispensable elegir un proveedor de datos fiable y de confianza que ofrezca múltiples soluciones para garantizar una validación adecuada de los datos y proporcione las herramientas necesarias para crear un sistema eficaz de verificación de datos.
Bright Data es un excelente ejemplo. Ofrece una amplia gama de productos, que incluyen Conjuntos de datos validados y listos para usar, y una selección completa de soluciones de Scraping web preparadas para la IA con el fin de recopilar información precisa de la web, lo que respalda los flujos de trabajo de validación y verificación.
¡Regístrese hoy mismo para obtener una cuenta gratuita de Bright Data y explore nuestros servicios de datos!




