

FlareSolverr es una herramienta de código abierto para eludir los desafíos de Cloudflare y la protección DDoS-Guard. Configura un servidor proxy para sus solicitudes, imita el navegador Chrome para pasar los controles de seguridad y muestra el contenido del sitio.
En este artículo, aprenderá a instalar FlareSolverr y a configurar la herramienta para el raspado web. También explorará algunas opciones para evitar los problemas de seguridad de los sitios web.
Implementación de FlareSolverr
FlareSolverr ofrece varios métodos de instalación. Sin embargo, se recomienda utilizar Docker para implementaciones coherentes, ya que empaqueta todas las dependencias y configuraciones dentro de su contenedor Docker.
Configuración de FlareSolverr con Docker
Con Docker instalado en su dispositivo, descargue la última versión de FlareSolverr, disponible en DockerHub, el Registro de GitHub y los repositorios actualizados de la Comunidad. El siguiente comando de shell extrae la última imagen de Docker de FlareSolverr:
docker pull 21hsmw/flaresolverr:nodriverPuede ejecutar el comando docker image ls para confirmar que la imagen está disponible en su sistema:

FlareSolverr se ejecuta como un servidor proxy en su dispositivo, por lo que es necesario definir los puertos en los que se puede servir y a los que se puede acceder. El siguiente comando establece 8191 como puerto de FlareSolverr y crea un contenedor para el servicio:
docker run -d --name flaresolverr -p 8191:8191 21hsmw/flaresolverr:nodriverTambién puede configurar variables de entorno para su ejecución Docker. FlareSolverr ofrece opciones para el registro y la supervisión dentro del servidor, la zona horaria y el idioma que se utilizará, y cualquier mecanismo CAPTCHA solver que desea utilizar con su servidor. Para el propósito de este tutorial, la configuración predeterminada de Docker es suficiente.
Compruebe que FlareSolverr se está ejecutando accediendo a http://localhost:8191 en su navegador:

Obtención de requisitos previos
Este tutorial fue hecho para un entorno Python. Además de instalar FlareSolverr y Docker, puede que necesites instalar ciertos paquetes de Python, como Beautiful Soup.
Más información sobre web scraping con BeautifulSoup aquí.
Extracción de datos con FlareSolverr
Nota: Respeta siempre las condiciones de servicio de cualquier sitio web del que hagas scraping. El uso responsable de datos públicos puede ser castigado con prohibiciones de IP y otras consecuencias legales.
El scraping con FlareSolverr es muy similar al proceso de scraping habitual, pero el sitio web de destino y los parámetros de solicitud se envían al servidor de FlareSolverr. El servidor pone en marcha una instancia del navegador con los parámetros de su sitio web y espera hasta que se supere el desafío de Cloudflare antes de enviarle el contenido del sitio. Puede enviar solicitudes a su servidor FlareSolverr a través de sus ejecuciones curl, scripts Python y programas de terceros.
Puede comprobar que un sitio web está protegido por Cloudflare realizando búsquedas en su código HTML, cabeceras o registros DNS, que harían referencia a Cloudflare. También puede utilizar herramientas de terceros, como Check for Cloudflare:

Vamos a probar el proceso FlareSolverr con Python. Cree un archivo Python en su entorno y copie el siguiente script. Este script de ejemplo recupera el contenido HTML de un sitio web protegido por Cloudflare:
# import Requests python library
import requests
# define the payload for your request execution
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
# structure the payload and make the request call
response = requests.post(url, headers=headers, json=data)
# print the request codes
print("Status:", response.json().get('status', {}))
print("Status Code:", response.status_code)
print("FlareSolverr message:", response.json().get('message', {}))
Este script envía una solicitud a su servidor FlareSolverr para raspar el sitio web Temu. FlareSolverr detecta un desafío de Cloudflare en el sitio web de destino, resuelve el desafío y, a continuación, devuelve el contenido HTML y la información de sesión.
Para ejecutar su script Python, puede utilizar el comando CLI python3 .py:
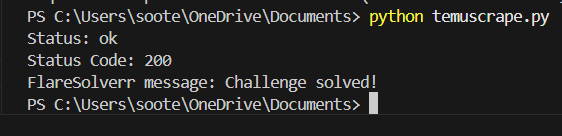
Obtener una impugnación de Cloudflare puede depender de tu IP y de las medidas que haya tomado el sitio web al que accedes.
Una vez superado el desafío de Cloudflare, puede analizar el contenido HTML normalmente con Beautiful Soup u otras bibliotecas de Python.
Asegúrese de que el paquete Python está instalado en su entorno. Puede utilizar el gestor de paquetes pip para instalar, con el comando pip install bs4.
Repasemos el proceso de scraping. Empieza por obtener las etiquetas HTML correctas para la información que necesitas. Aquí está el título del artículo y el nombre del autor:

Con esa información, puedes escribir un script para analizar los datos utilizando las etiquetas:
# import python libraries
import requests
from bs4 import BeautifulSoup
# define the payload for your request execution
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
# structure the payload and make the request call
response = requests.post(url, headers=headers, json=data)
# print the request codes
print("Status:", response.json().get('status', {}))
print("Status Code:", response.status_code)
print("FlareSolverr message:", response.json().get('message', {}))
# parse logic
page_content = response.json().get('solution', {}).get('response', '')
soup = BeautifulSoup(page_content, 'html.parser')
# find the div with class 'space-y-3'
target_div = soup.find('div', class_='space-y-3')
# article author
spans = target_div.find_all('span')
span_element = spans[-1]
span_text = span_element.get_text(strip=True)
# article title
h2_element = target_div.find('h2', class_=['font-semibold', 'font-poppins'])
h2_text = h2_element.get_text(strip=True)
print(f"article author: ",span_text, " article title: ", h2_text)
Este script evita inicialmente el desafío Cloudflare del sitio, devuelve el contenido HTML y lo analiza con Beautiful Soup para obtener la información que desea.
Ejecute el archivo Python actualizado con el comando CLI python .py:

FlareSolverr es una herramienta flexible que puede integrarse en su proceso de scraping y escalarse para adaptarse a casos de uso más complejos. Para los sitios web con prohibiciones y restricciones geográficas, también puede utilizar FlareSolverr con funciones de soporte de proxy. Explorará cómo funciona en la siguiente sección.
Uso de proxies con FlareSolverr
Utilizar proxies en su estrategia de web scraping mejora la eficacia y permite un scraping sostenible. Los proxies le permiten evitar las restricciones geográficas y las prohibiciones de IP y enmascarar su identidad web para mejorar el anonimato. Los proxies también pueden ayudar directamente a escalar sus operaciones de scraping con solicitudes concurrentes que le permiten mantenerse dentro de los límites de velocidad. Dependiendo de la calidad de sus proxies, sus solicitudes pueden imitar mejor el comportamiento real del usuario y parecer legítimas a los monitores del sitio web.
Según el uso y la funcionalidad, puede tener proxies móviles, residenciales y de centro de datos. Un proxy móvil utiliza direcciones IP reales asignadas por empresas de telecomunicaciones para enrutar el tráfico a través de redes de operadores móviles (3G, 4G, 5G). Con miles de usuarios compartiendo la misma IP en diferentes momentos, este tipo de proxy es difícil de vincular a un usuario específico, y es poco probable que activen CAPTCHA, Cloudflare u otros problemas de seguridad. Sin embargo, puede ser caro y más lento que otras categorías de proxy.
El proxy residencial es otra categoría de proxy que utiliza IPs de usuarios reales, lo que permite enmascarar mejor el comportamiento de scraping. También es caro, pero no tiene el anonimato de usuario específico del proxy móvil; es decir, el uso excesivo y otros comportamientos sospechosos pueden provocar el bloqueo de la IP residencial. Se utiliza mejor para eludir las restricciones geográficas y la vigilancia. Los proxies de centros de datos son proxies en la nube o servidores de datos no asociados a un ISP. Proporcionan conexiones de alta velocidad y baja latencia a un bajo coste, por lo que son los mejores para las necesidades de scraping masivo. Son menos capaces de simular el comportamiento de un usuario real, lo que aumenta la probabilidad de ser bloqueados por retos de sitios web y funciones de limitación de velocidad.
Puede añadir proxies a sus solicitudes de FlareSolverr especificándolos en la carga útil de la solicitud. Los proxies públicos gratuitos están disponibles en línea, pero para casos de uso de producción que requieren fiabilidad, los servicios de proxy gestionados son una mejor opción.
El siguiente script de ejemplo adjunta proxies rotatorios de BrightData, para sus solicitudes de FlareSolverr:
import requests
import random
proxy_list = [
'185.150.85.170',
'45.154.194.148',
'104.244.83.140',
'58.97.241.46',
'103.250.82.245',
'83.229.13.167',
]
proxy_ip = random.choice(proxy_list)
proxies = {
'http': f'http://{proxy_ip}',
'https': f'https://{proxy_ip}',
}
payload = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000
}
response = requests.post(url, headers=headers, json=data, proxies=proxies)
print("Status Code:", response.status_code)
Para la producción, puede mantener una lista de proxy más amplia y recorrerla antes de cada solicitud para garantizar la rotación de las selecciones de proxy para el web scraping.
Gestión de sesiones y manejo de cookies
Cloudflare genera y adjunta cookies al tráfico de usuarios dentro de los sitios web. Esto ayuda a gestionar el tráfico y a proteger contra solicitudes maliciosas repetidas sin monopolizar los recursos de red para cada solicitud individual. FlareSolverr recopila y pasa los datos de la cookie dentro de la respuesta JSON, que puede validar sus solicitudes posteriores en lugar de resolver desafíos individuales de Cloudflare en cada solicitud:

FlareSolverr ofrece gestión de sesiones para mejorar la coherencia entre varias solicitudes. Una vez que se crea una sesión, conservará todas las cookies en la instancia del navegador hasta que se destruya la sesión. Esto permite una mejor escala y velocidad de respuesta sobre sus solicitudes de raspado.
El siguiente código demuestra cómo crear sesiones dentro de sus scripts de código:
import requests
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "sessions.create",
}
response = requests.post(url, headers=headers, json=data)
print(response.text)
El comando en la carga útil de la solicitud se cambia a sessions.create (en lugar de requests.get). El valor url no es necesario para este comando, pero puede establecer un proxy para la sesión. Consulte la estructura de comandos de FlareSolverr para explorar otros comandos, como destruir sesión, lista de sesiones y enviar solicitudes:

Su valor de ID de sesión puede utilizarse en posteriores solicitudes añadiéndolo a la carga útil:
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
data = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000,
"session":"<SESSION_ID>"
}
response = requests.post(url, headers=headers, json=data)
print(response.text)
El valor de tiempo de espera es el tiempo máximo en segundos que se ejecutará tu petición. Si no se da una respuesta dentro de ese tiempo, obtendrá una respuesta de error. Veamos el script combinado de tomar la creación de sesión y usar el ID de sesión:
import requests
import time
# creating the session
url = "http://localhost:8191/v1"
headers = {"Content-Type": "application/json"}
first_request = {
"cmd": "sessions.create",
}
first_response = requests.post(url, headers=headers, json=first_request)
session_id = first_response.json().get('session', {})
# using the session id
second_request = {
"cmd": "request.get",
"url": "https://www.datanearme.co/",
"maxTimeout": 60000,
"session":f"{session_id}"
}
second_response = requests.post(url, headers=headers, json=second_request)
print("Status:", second_response.json().get('status', {}))
Puedes encontrar todos los scripts de Python en este repositorio de GitHub.
Ya ha explorado cómo realizar solicitudes con FlareSolverr e interpretar las respuestas, pero es igualmente importante comprender cómo gestionar los fallos.
Resolución de problemas en sus solicitudes de FlareSolverr
Cloudflare actualiza con frecuencia sus protocolos, y las diferencias en los sitios web y los casos de uso pueden dar lugar a comportamientos inesperados. En esta sección se describen los errores más comunes, cómo los gestiona FlareSolverr y qué puede hacer para resolverlos.
Para solucionar los problemas de sus solicitudes de raspado, siempre debe empezar por lo siguiente:
- Registros de FlareSolverr
He aquí algunos errores más específicos y cómo puede abordarlos:
- Fallos repetidos de desafío/CAPTCHA: Esto puede significar que el sitio ha marcado tus solicitudes como sospechosas. Ajusta tus peticiones y cambia de proxy para emular mejor el comportamiento real del usuario. Las cookies también pueden caducar, así que asegúrate de actualizarlas regularmente mientras mantienes tus sesiones de solicitud.
- Error de
desafío no detectado: Esto puede deberse a que no hay ningún desafío disponible, a la presencia de medidas de seguridad no reconocidas que son incompatibles con FlareSolverr, al uso de una versión obsoleta de FlareSolverr o a que el desafío está oculto deliberadamente. Es posible que siga obteniendo el contenido deseado si no se detecta un desafío, pero si no funciona, intente actualizar su versión de FlareSolverr y vuelva a realizar la prueba para localizar el problema. - Error
Las cookies proporcionadas por FlareSolverr no son válidas: Este error se produce cuando las cookies devueltas por FlareSolverr no funcionan correctamente. A menudo se produce debido a desajustes de IP o de red entre Docker y FlareSolverr, especialmente cuando se utilizan VPN.
Siempre puede encontrar más información en Internet si se encuentra con otros problemas no mencionados aquí. Hay una gran comunidad de código abierto detrás de FlareSolverr, por lo que es muy posible que ya exista una solución para cualquier problema que tenga.
FlareSolverr Alternativas
FlareSolverr es una herramienta de código abierto diseñada para usuarios con los conocimientos técnicos necesarios para construir sobre sus cimientos. Sin embargo, es posible que no siempre esté actualizada con los últimos cambios de Cloudflare, lo que puede afectar a las operaciones sensibles al tiempo. Desde enero de 2026, sus solucionadores de CAPTCHA no funcionan, y algunos sitios presentan retos a Cloudflare que no puede sortear.
Si necesita una solución para el scraping a gran escala o un bypass de Cloudflare más robusto, las siguientes alternativas ofrecen características y fiabilidad adicionales:
- Navegador de raspado: Un navegador de raspado es un navegador GUI diseñado específicamente para el raspado web con funciones como la rotación automática de proxy y la resolución CAPTCHA incorporada. Bright Data Scraping Brows er ofrece una integración sencilla con marcos web como Playwright, Puppeteer y Selenium, lo que permite flujos de trabajo programáticos directamente vinculados con un entorno de navegador interactivo a escala.
- APIs de Web Scraper: Las API de Web Scraper son marcos ya integrados en los dominios de destino, que permiten recopilar datos bajo demanda sin el proceso de scraping manual. Son fáciles de usar, con estructuras de datos ya creadas y una arquitectura que permite gestionar llamadas masivas de datos. Las API de Bright Data Web Scraper se conectan a una serie de dominios populares, como LinkedIn, Zillow, Yelp e Instagram, y ofrecen una recopilación de datos 100 por cien compatible.
- Conjuntos de datos a la carta: Con los conjuntos de datos a petición, obtendrá un servicio gestionado de conjuntos de datos listos para usar. Esto ofrece una vía libre de trabajo para obtener los datos que necesita, ya estructurados y formateados para sus operaciones de datos. Bright Data ofrece un amplio mercado para varios conjuntos de datos populares, como perfiles de LinkedIn e Instagram, productos de Walmart y Shein, y listados de Booking.com. Estos conjuntos de datos se mantienen y actualizan periódicamente, con planes de suscripción para el acceso a los datos.
- Solución de scraping gestionada: Por último, las soluciones totalmente gestionadas pueden agilizar el proceso de scraping con funciones que se encargan de la mayoría de las características de seguridad de los sitios web, como la representación de javascript, las huellas dactilares del navegador, los captcha y la geolocalización. Por ejemplo, Web Unlocker de BrightData puede desbloquear cualquier dominio.
Conclusión
En este artículo, ha explorado FlareSolverr y cómo puede evitar los retos de Cloudflare. Ha configurado FlareSolverr para el scraping multiproxy y para mantener el acceso a los datos a lo largo de varias solicitudes. Por último, ha aprendido a solucionar los problemas de las solicitudes de FlareSolverr y los errores comunes a los que puede enfrentarse.
Si busca una herramienta de recopilación de datos coherente y que cumpla las normativas, nuestro navegador de raspado y nuestros raspadores web ofrecen herramientas optimizadas para sus procesos de raspado. Obtendrá servicios gestionados con proxies fiables, una interfaz de usuario intuitiva y tasas de éxito de raspado web cercanas al 100 %.
Regístrese ahora y comience su prueba gratuita.





