

Al realizar scraping web, a menudo te encontrarás con paginación, donde el contenido se distribuye en varias páginas. Manejar esta paginación puede ser un reto, ya que diferentes sitios web utilizan diferentes técnicas de paginación.
En este artículo, explicaré las técnicas de paginación más comunes y mostraré cómo manejarlas con un ejemplo práctico de código.
¿Qué es la paginación?
Los sitios web como las plataformas de comercio electrónico, las bolsas de trabajo y las redes sociales utilizan la paginación para gestionar grandes cantidades de datos. Mostrar todo en una sola página aumentaría significativamente los tiempos de carga y consumiría demasiada memoria. La paginación divide el contenido en varias páginas y ofrece opciones de navegación como «Siguiente», números de página o carga automática al desplazarse. Esto hace que la navegación sea más rápida y organizada.
Tipos de paginación
La complejidad de la paginación puede variar, desde la simple paginación numerada hasta técnicas más avanzadas como el desplazamiento infinito o la carga dinámica de contenido. En mi experiencia, me he encontrado con tres tipos principales de paginación, que creo que son los más utilizados en los sitios web:
- Paginación numerada: los usuarios navegan por páginas discretas utilizando enlaces numerados.
- Paginación de carga por clic: los usuarios hacen clic en un botón (por ejemplo, «Cargar más») para cargar contenido adicional.
- Desplazamiento infinito: el contenido se carga automáticamente a medida que los usuarios se desplazan hacia abajo en la página.
¡Veamos cada uno de ellos con más detalle!
Paginación numerada
Esta es la técnica de paginación más común, a menudo denominada «paginación siguiente y anterior», «paginación con flechas» o «paginación basada en URL». A pesar de los diferentes nombres, la idea central es la misma: las páginas se enlazan mediante enlaces numerados. Se puede navegar cambiando el número de página en la URL. Para saber cuándo detener la paginación, se puede comprobar si el botón «Siguiente» está desactivado o si no hay nuevos datos disponibles.
Normalmente tiene este aspecto:

`¡Veamos un ejemplo! Navegaremos por todas las páginas del sitio web Scrapethesite. La barra de paginación de este sitio tiene un total de 24 páginas.

Verás que cuando haces clic en el botón «>>», la URL cambia de la siguiente manera:
- 1.ª página: https://www.scrapethissite.com/pages/forms/
- 2.ª página: https://www.scrapethissite.com/pages/forms/?page_num=2
- 3.ª página: https://www.scrapethissite.com/pages/forms/?page_num=3
Ahora, eche un vistazo al HTML de este botón «Siguiente». Es una etiqueta de anclaje (<a>) con un atributo href que enlaza con la página siguiente. El atributo aria-label muestra que el botón «Siguiente» sigue activo.
Cuando no hay más páginas, el atributo aria-label desaparece, lo que indica el final de la paginación.
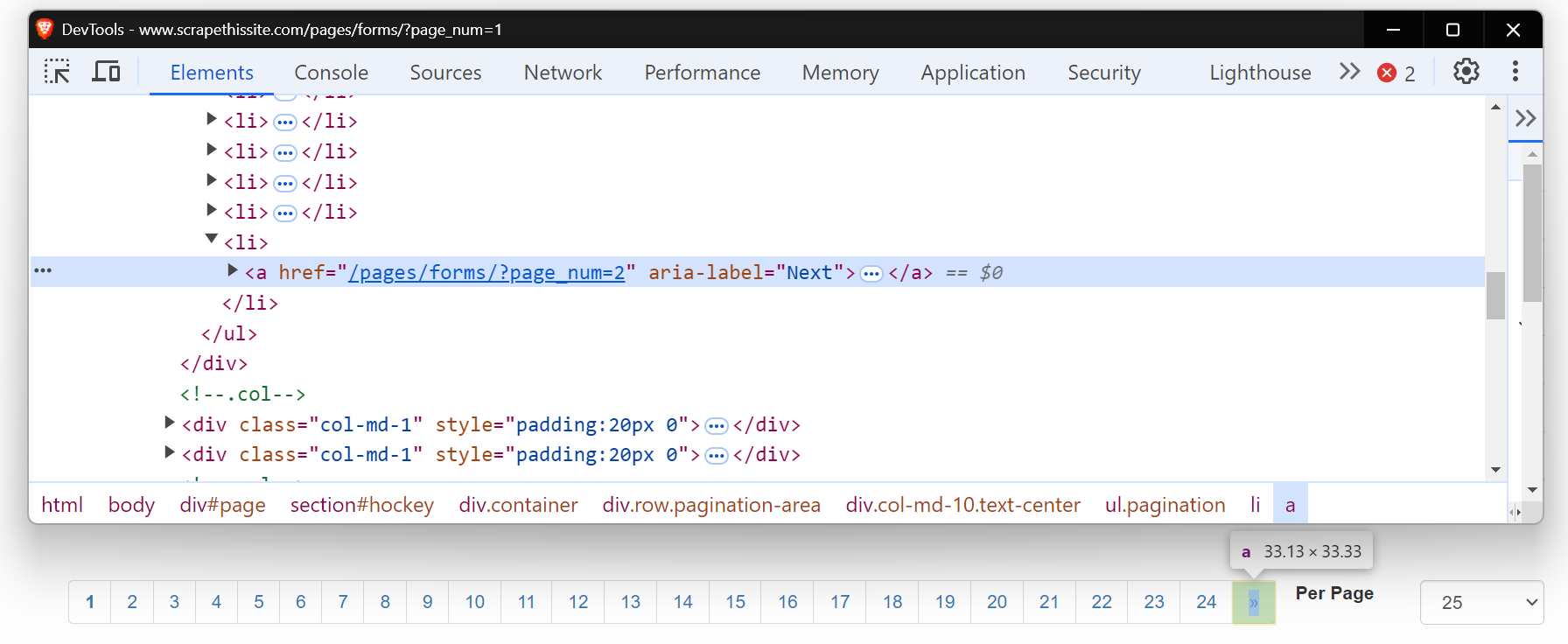
Comencemos escribiendo un Scraper web básico para navegar por estas páginas. En primer lugar, configura tu entorno instalando los paquetes necesarios. Para obtener una guía detallada sobre el Scraping web con Python, puedes consultar la entrada del blog aquí.
pip install requests beautifulsoup4 lxmlEste es el código para paginar cada página:
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# Comenzar con la página 1
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"Actualmente en la página: {page_num}")
# Comprueba si existe el botón «Siguiente»
botón_siguiente = soup.find("a", {"aria-label": "Siguiente"})
si botón_siguiente:
# Pasa a la página siguiente
número_de_página += 1
else:
# No hay más páginas, sale del bucle
imprimir("Se ha llegado a la última página.")
breakEste código navega por las páginas comprobando si existe el botón «Siguiente» (con aria-label="Siguiente"). Si el botón está presente, incrementa el número de página y realiza una nueva solicitud con la URL actualizada. El bucle continúa hasta que ya no se encuentra el botón «Siguiente», lo que indica que se ha llegado a la última página.
Ejecute el código y verá que hemos navegado con éxito por todas las páginas.

Algunos sitios web tienen un botón «Siguiente» que no cambia la URL, pero que carga contenido nuevo en la misma página. En estos casos, es posible que los métodos tradicionales de Scraping web no funcionen bien. Herramientas como Selenium o Playwright son más adecuadas, ya que pueden interactuar con la página y simular acciones como hacer clic en botones para recuperar el contenido cargado dinámicamente. Para obtener más información sobre el uso de Selenium para estas tareas, puede leer una guía detallada aquí.
Te encontrarás con una situación similar al intentar extraer la página del blog de NGINX.
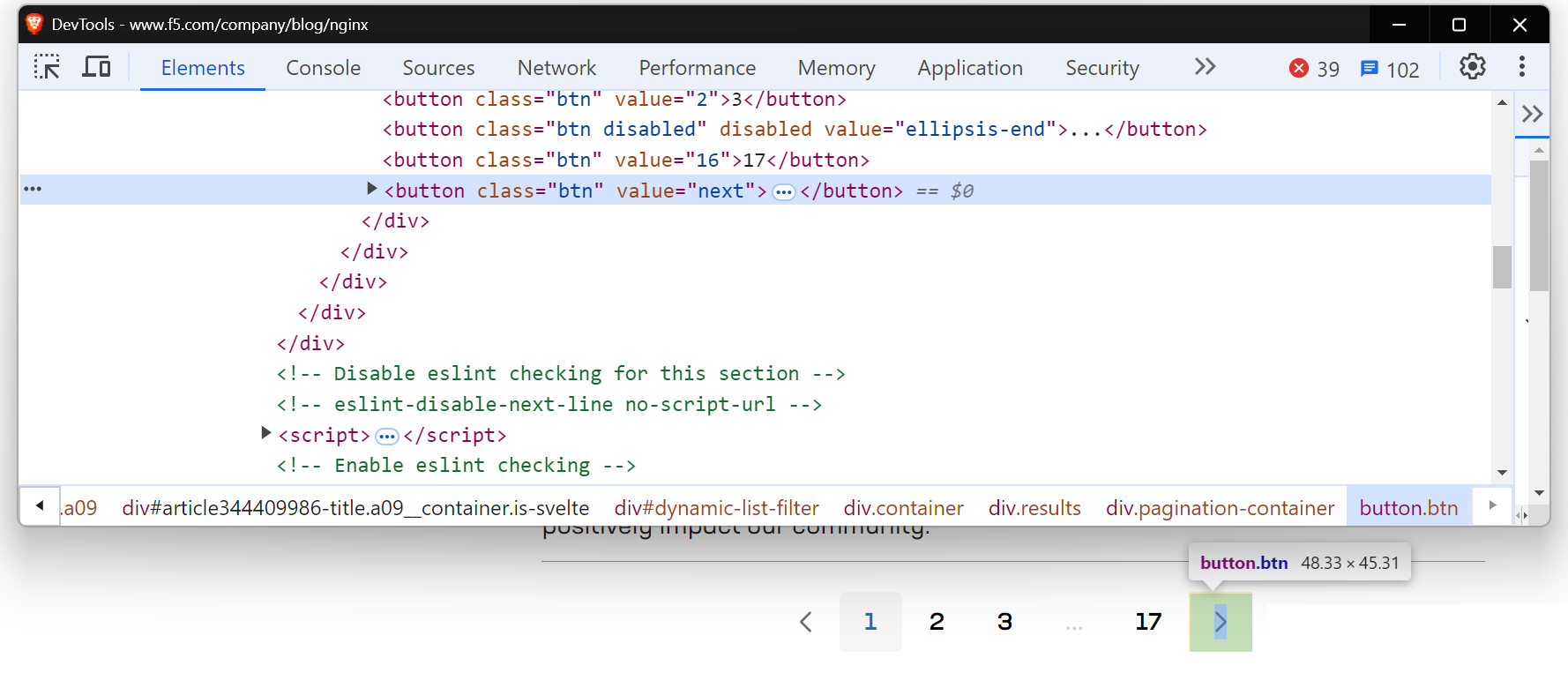
Usemos Playwright para manejar el contenido cargado dinámicamente. Si eres nuevo en Playwright, consulta esta útil guía de introducción.
Ahora, antes de escribir el código, ejecuta el siguiente comando para configurar Playwright en tu máquina:
pip install playwright
playwright installEste es el código:
import asyncio
from playwright.async_api import async_playwright
# Define una función asíncrona
async def scrape_nginx_blog():
async with async_playwright() as p:
# Inicia una instancia del navegador Chromium en modo sin interfaz gráfica
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navegar a la página del blog de NGINX
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
while True:
print(f"Actualmente en la página {page_num}")
# Localizar el botón «Siguiente» utilizando un localizador de botones con el valor «next»
next_button = page.locator('button[value="next"]')
# Comprueba si el botón «Siguiente» está habilitado.
if await next_button.is_enabled():
await next_button.click() # Haz clic en el botón «Siguiente» para ir a la página siguiente.
await page.wait_for_timeout(
2000
) # Espera 2 segundos para permitir que se cargue el nuevo contenido.
page_num += 1
else:
print("No hay más páginas. Rastreo finalizado.")
break # Salir del bucle si no hay más páginas disponibles
await browser.close() # Cerrar el navegador
# Ejecutar la función de rastreo asíncrono
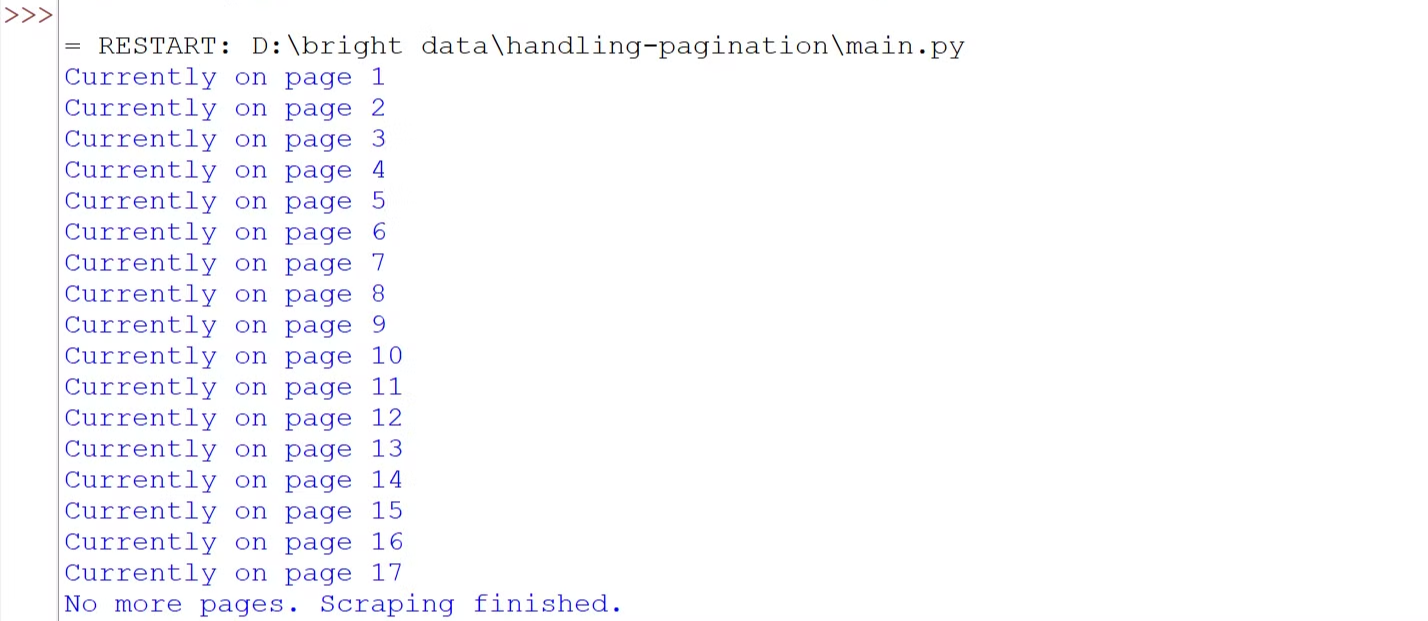
asyncio.run(scrape_nginx_blog())El código utiliza Playwright asíncrono para navegar por todas las páginas. Entra en un bucle que comprueba el botón «Siguiente». Si el botón está habilitado, hace clic para ir a la página siguiente y espera a que se cargue el contenido. Este proceso se repite hasta que no hay más páginas disponibles. Finalmente, el navegador se cierra una vez completado el rastreo.
Ejecute el código y verá que hemos navegado con éxito por todas las páginas.
Paginación de carga por clic
En muchos sitios web, probablemente haya visto botones como «Cargar más», «Mostrar más» o «Ver más». Estos son ejemplos de paginación con clic para cargar, que se utiliza habitualmente en los sitios web modernos. Estos botones cargan contenido de forma dinámica a través de JavaScript. El principal reto aquí es simular la interacción del usuario, automatizando el proceso de hacer clic en el botón para cargar más contenido.
Tomemos como ejemplo la sección del blog de Bright Data. Cuando lo visites y te desplaces hacia abajo, verás un botón «Ver más» que carga las entradas del blog al hacer clic en él.
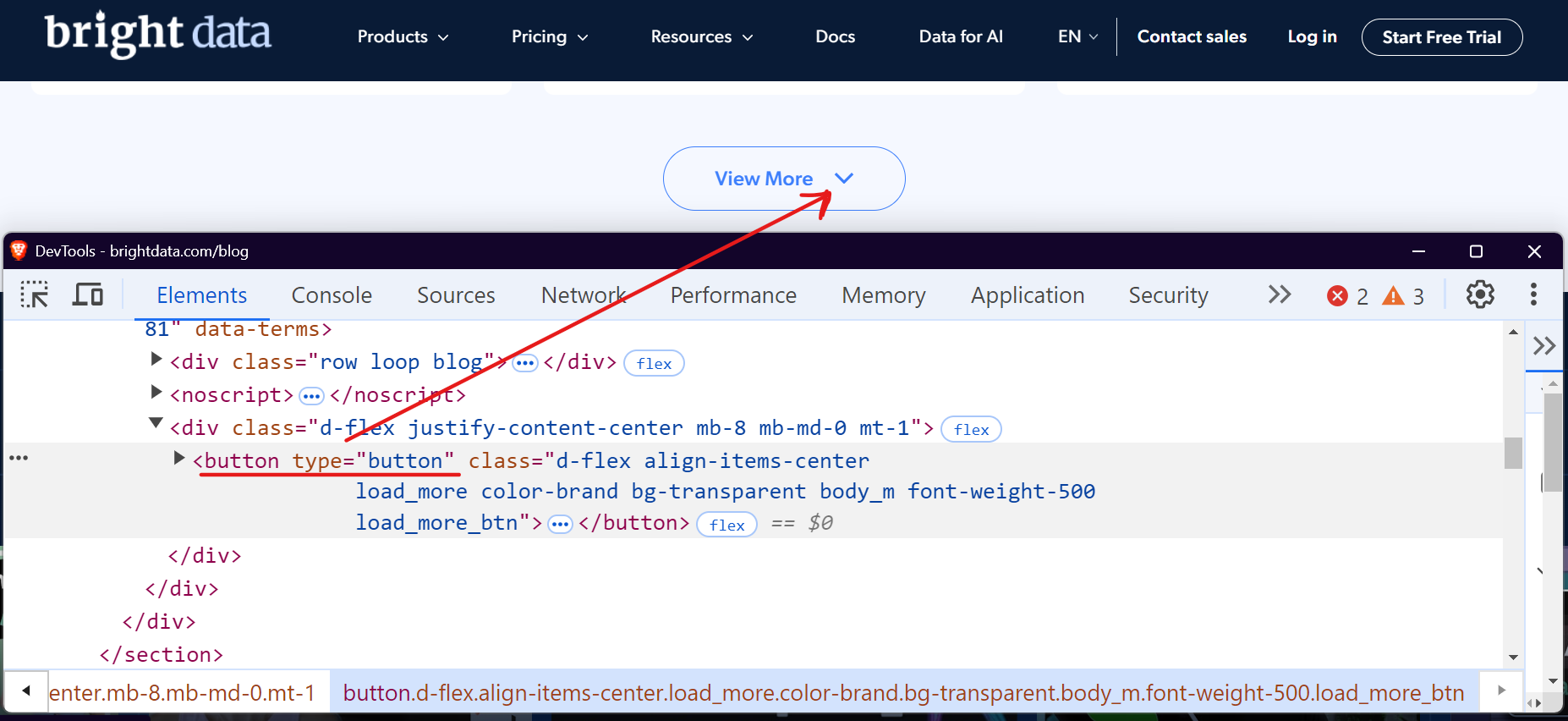
Puedes utilizar herramientas como Selenium o Playwright para automatizar este proceso haciendo clic repetidamente en el botón «Cargar más» hasta que no haya más contenido disponible. Veamos cómo podemos manejar esto fácilmente con Playwright.
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# Iniciar un navegador sin interfaz gráfica
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navegar al blog de Bright Data
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"Actualmente en la página {page_num}")
# Localizar el botón «Ver más»
view_more_button = page.locator("button.load_more_btn")
# Comprueba si el botón está visible y habilitado
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
print("No hay más páginas que cargar. Raspado finalizado.")
break
# Cerrar el navegador
await browser.close()
# Ejecutar la función de raspado
asyncio.run(scrape_brightdata_blog())El código localiza el botón «Ver más» utilizando el selector CSS button.load_more_btn. A continuación, comprueba si el botón existe y es visible utilizando count() > 0 e is_visible(). Si el botón es visible, interactúa con él utilizando el método click() y espera 2 segundos para permitir que se cargue el nuevo contenido. Este proceso se repite en un bucle hasta que el botón deja de ser visible.
Ejecute el código y verá que hemos navegado con éxito por todas las páginas.

Hemos extraído con éxito las 52 páginas de la sección del blog de Bright Data. Esto demuestra que el sitio tiene un total de 52 páginas, lo que solo descubrimos después del proceso de extracción. Sin embargo, es posible conocer el número total de páginas antes de la extracción.
Para ello, abre las Herramientas de desarrollador, ve a la pestaña «Red» y filtra las solicitudes seleccionando «Fetch/XHR». A continuación, haz clic de nuevo en el botón «Ver más» y verás que se activa una solicitud AJAX.
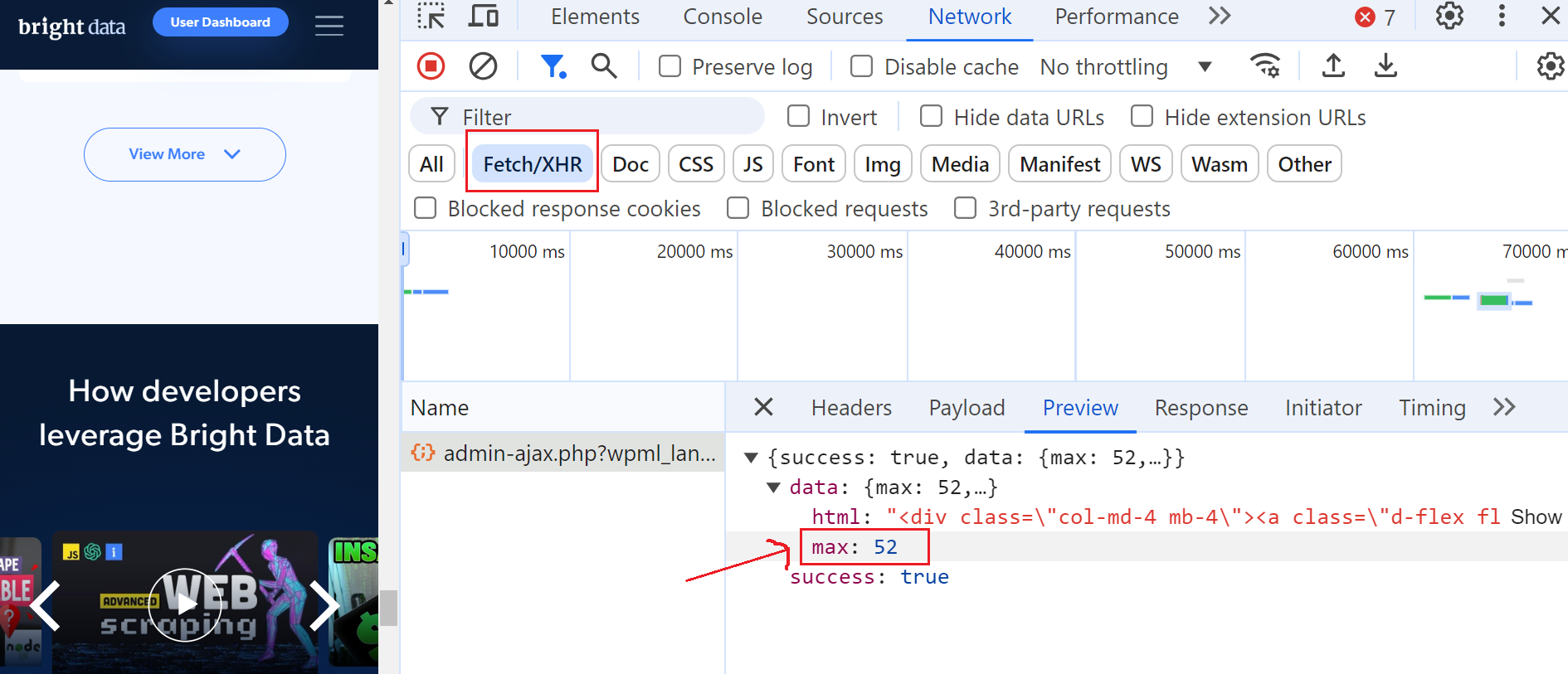
Haz clic en esta solicitud y ve a la sección «Vista previa», donde verás que el número máximo de páginas es 52. A continuación, ve a la sección «Carga útil» y verás que hay 6 entradas de blog por página y que actualmente estamos en la página 3.
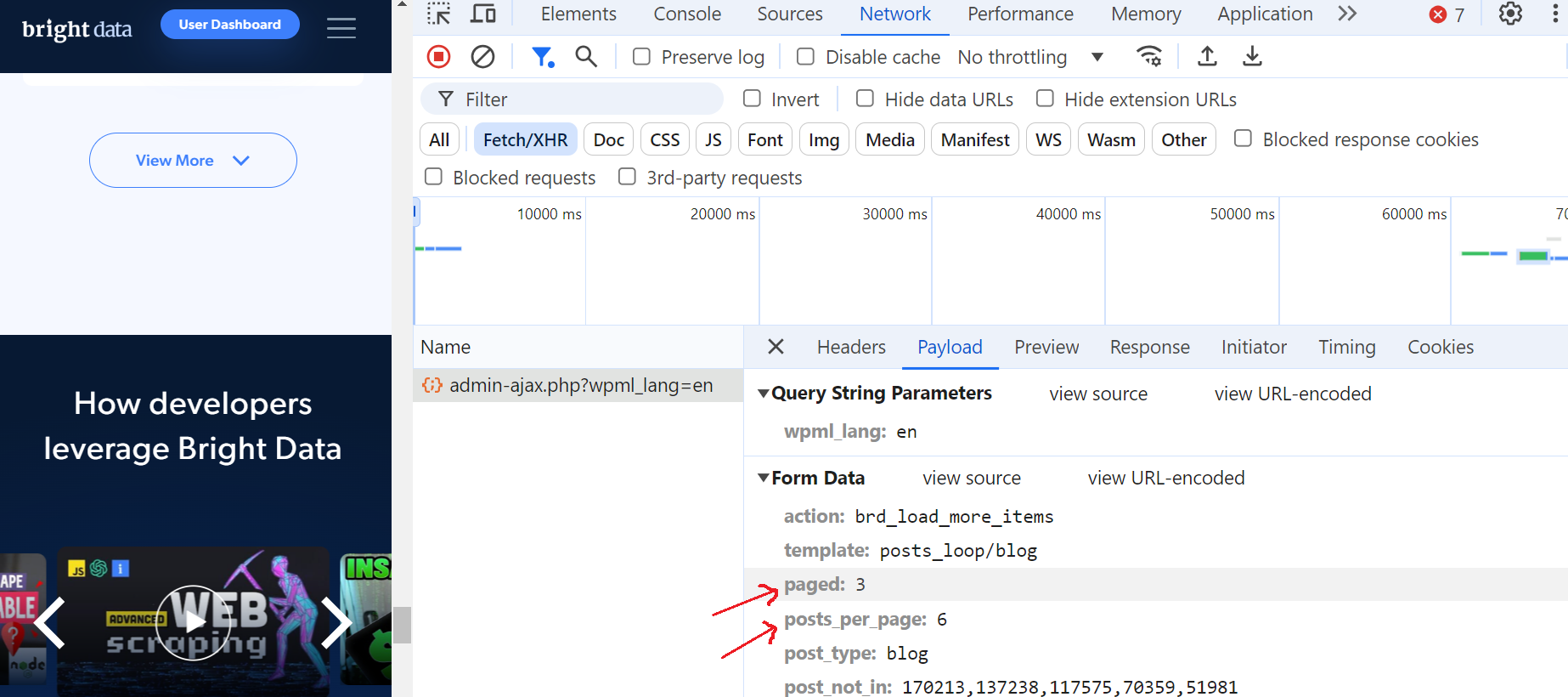
¡Esto es fantástico!
Paginación con desplazamiento infinito
En lugar de los botones «anterior/siguiente», muchos sitios web utilizan ahora el desplazamiento infinito, lo que mejora la experiencia del usuario al eliminar la necesidad de hacer clic en varias páginas. Esta técnica carga automáticamente nuevo contenido a medida que el usuario se desplaza hacia abajo. Sin embargo, presenta retos únicos para los Scrapers, ya que requiere supervisar los cambios en el DOM y gestionar las solicitudes AJAX.
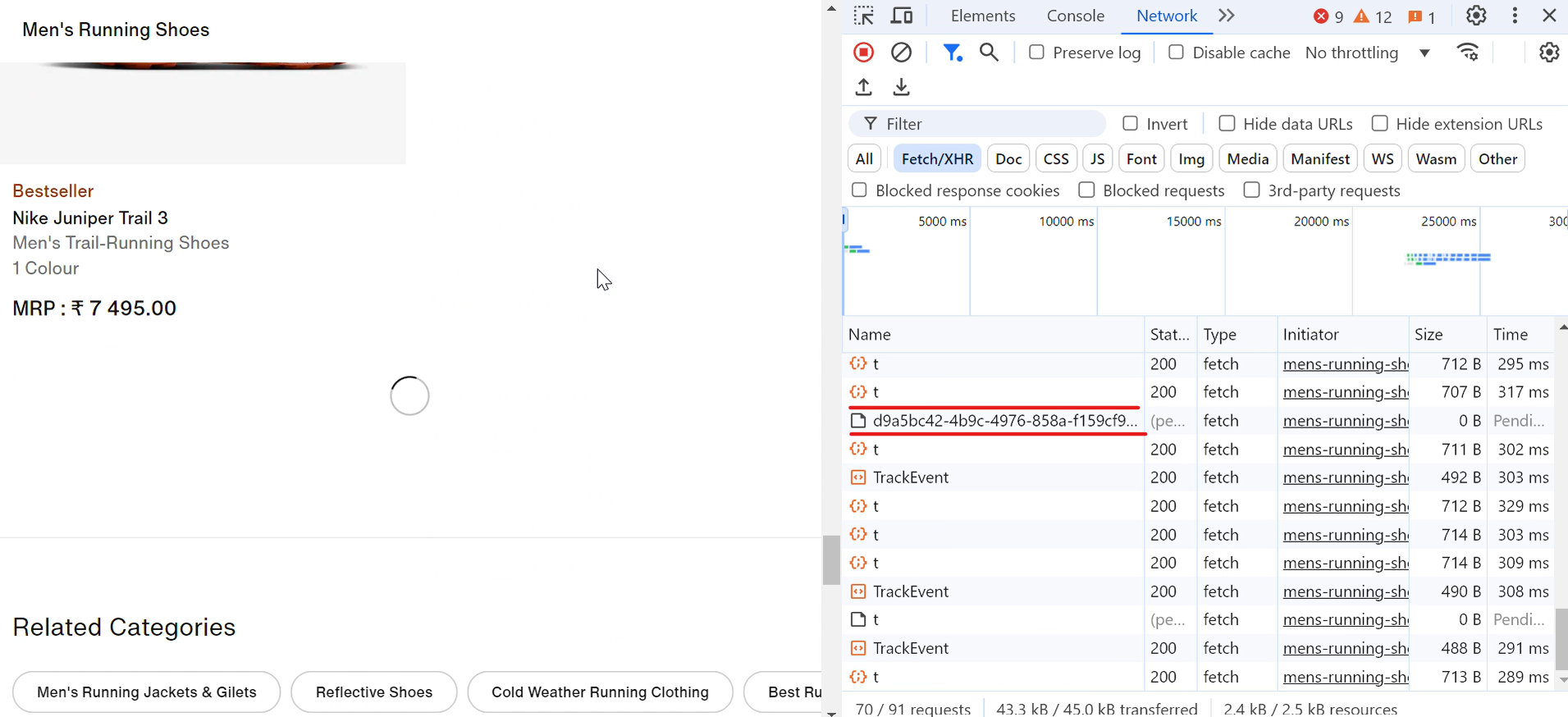
Veamos un ejemplo real. Cuando visitas el sitio web de Nike, verás que los zapatos se cargan automáticamente a medida que te desplazas hacia abajo. Con cada desplazamiento, aparece brevemente un icono de carga y, en un abrir y cerrar de ojos, se muestran más zapatos, como se muestra en la imagen siguiente:
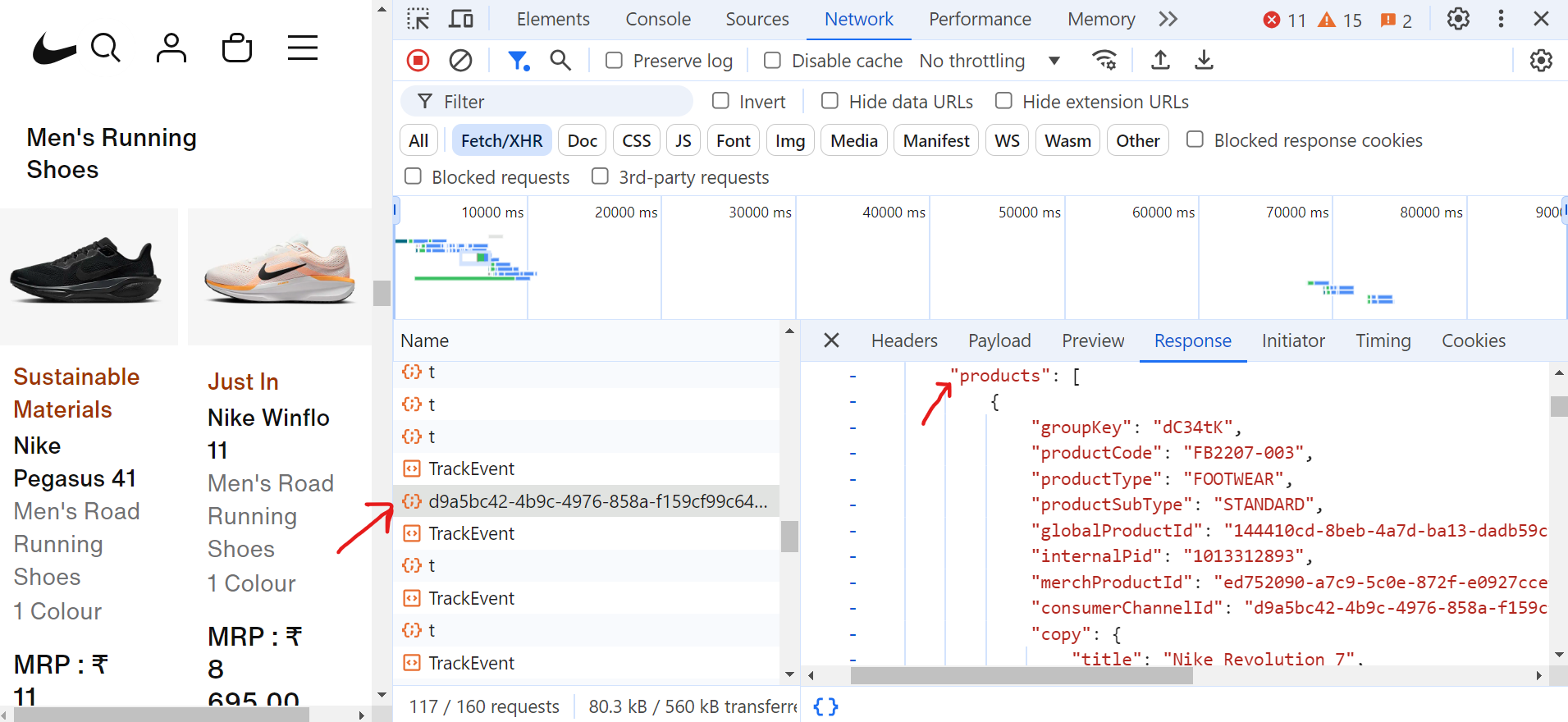
Al hacer clic en la solicitud (d9a5bc), puedes encontrar todos los datos de la página actual en la pestaña «Respuesta».
Ahora, para gestionar la paginación, debes seguir desplazándote hacia abajo por la página hasta llegar al final. A medida que te desplazas, el navegador realizará muchas solicitudes, pero solo algunas de estas solicitudes Fetch/XHR contendrán los datos reales que necesitas.
Este es el código que gestiona la paginación y extrae los títulos de los zapatos:
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""Desplázate hasta la parte inferior de la página hasta que no se cargue más contenido."""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# Desplazarse hacia abajo
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # Esperar a que se cargue el nuevo contenido
scroll_count += 1
print(f"Iteración de desplazamiento: {scroll_count}")
# Comprueba si ha cambiado la altura de desplazamiento
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("Se ha llegado al final de la página.")
break # Salir si no se carga contenido nuevo
last_height = new_height
async def extract_product_data(response, extracted_products) -> None:
"""Extraer datos del producto de la respuesta."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
extracted_products = []
# Configurar el listener para las respuestas de datos de productos.
page.on(
"response",
lambda response: extract_product_data(
response, extracted_products),
)
# Navegar a la página y desplazarse hasta la parte inferior
print("Navegando a la página...")
await page.goto(target_url, wait_until="domcontentloaded")
await asyncio.sleep(2)
await scroll_to_bottom(page)
# Guardar los títulos de los productos en un archivo de texto
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"¡Rastreo completado!")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)En el código, la función scroll_to_bottom se desplaza continuamente hasta la parte inferior de la página para cargar más contenido. Comienza registrando la altura de desplazamiento actual y luego se desplaza hacia abajo repetidamente. Después de cada desplazamiento, comprueba si la nueva altura de desplazamiento difiere de la última altura registrada. Si la altura permanece sin cambios, concluye que no se está cargando más contenido y sale del bucle. Este enfoque garantiza que todos los productos disponibles se carguen completamente antes de que continúe el proceso de scraping.
Esto es lo que ocurre cuando se ejecuta el código:

Una vez ejecutado correctamente el código, se creará un nuevo archivo de texto que contendrá todos los títulos de las zapatillas Nike.
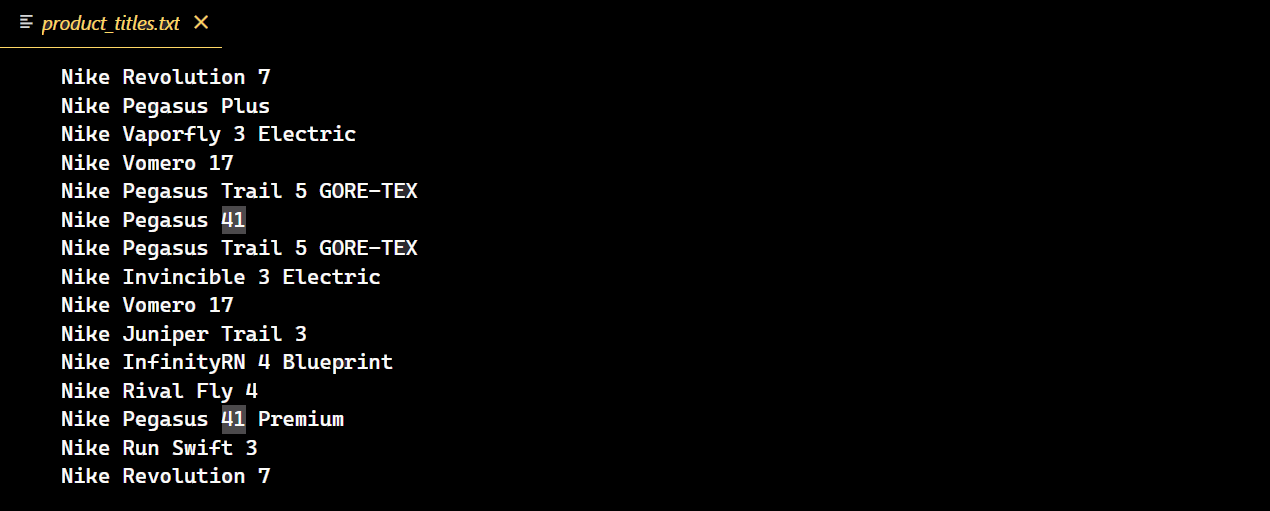
Retos de la paginación
El riesgo de ser bloqueado aumenta cuando se trata de contenido paginado, y algunos sitios web pueden bloquearte después de solo una página. Por ejemplo, si intentas extraer datos de Glassdoor, puedes encontrarte con varios retos de Scraping web, uno de los cuales es el reto CAPTCHA de Cloudflare, como yo mismo he experimentado.
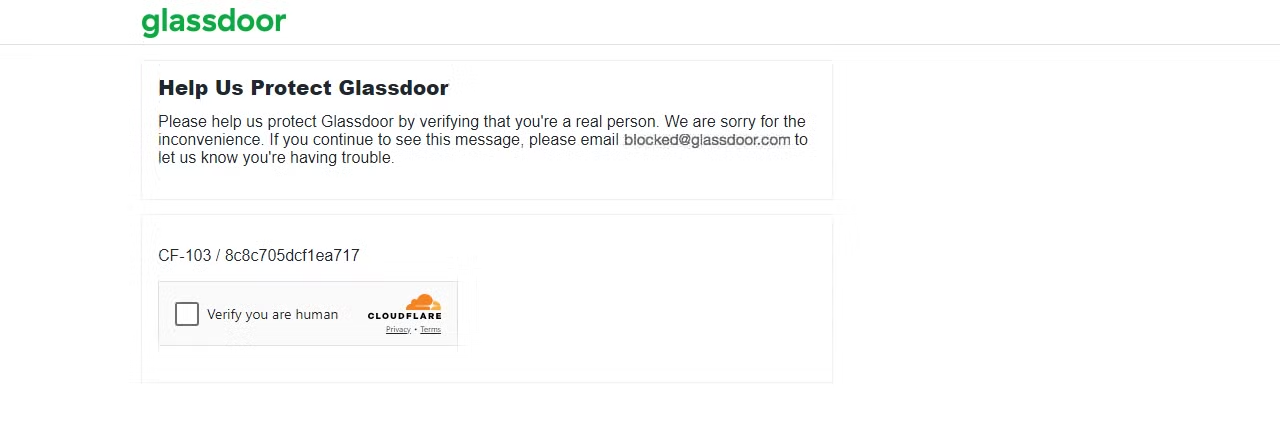
Hagamos una solicitud a la página de Glassdoor y veamos qué sucede.
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Código de estado: {response.status_code}")El resultado es un código de estado 403.
Esto indica que Glassdoor ha detectado que tu solicitud proviene de un bot o un Scraper, lo que ha dado lugar a un desafío CAPTCHA. Si continúas enviando múltiples solicitudes, tu IP podría bloquearse inmediatamente.
Para evitar estos bloqueos y extraer eficazmente los datos que necesitas, puedes utilizar proxies en Python Requests para evitar las prohibiciones de IP o imitar un navegador real rotando el agente de usuario. Sin embargo, es importante tener en cuenta que ninguno de estos métodos puede garantizar que se evite la detección avanzada de bots.
Entonces, ¿cuál es la solución definitiva? ¡Veámoslo a continuación!
Incorpore las soluciones de Bright Data
Bright Data es una excelente solución para eludir las sofisticadas medidas antibots. Se integra perfectamente en su proyecto con solo unas pocas líneas de código y ofrece una gama de soluciones para cualquier mecanismo antibots avanzado.
Una de sus soluciones es la API de rastreo web, que simplifica la extracción de datos de cualquier sitio web al gestionar automáticamente la rotación de IP y la Resolución de CAPTCHA. Esto le permite centrarse en el análisis de datos en lugar de en las complejidades de la recuperación de datos.
Por ejemplo, en nuestro caso, encontramos dificultades al intentar eludir el CAPTCHA de Glassdoor. Para solucionarlo, puede utilizar la API de Scraper de Glassdoor de Bright Data, que está diseñada específicamente para eludir este tipo de obstáculos y extraer datos del sitio web a la perfección.
Para empezar a utilizar la API del Scraper de Glassdoor, siga estos pasos:
En primer lugar, crea una cuenta. Visita el sitio web de Bright Data, haz clic en «Prueba gratuita» y sigue las instrucciones de registro. Una vez que hayas iniciado sesión, serás redirigido a tu panel de control, donde obtendrás algunos créditos gratuitos.
Ahora, vaya a la sección API del Scraper web y seleccione Glassdoor en la categoría de datos B2B. Encontrará varias opciones de recopilación de datos, como recopilar empresas por URL o recopilar ofertas de empleo por URL.
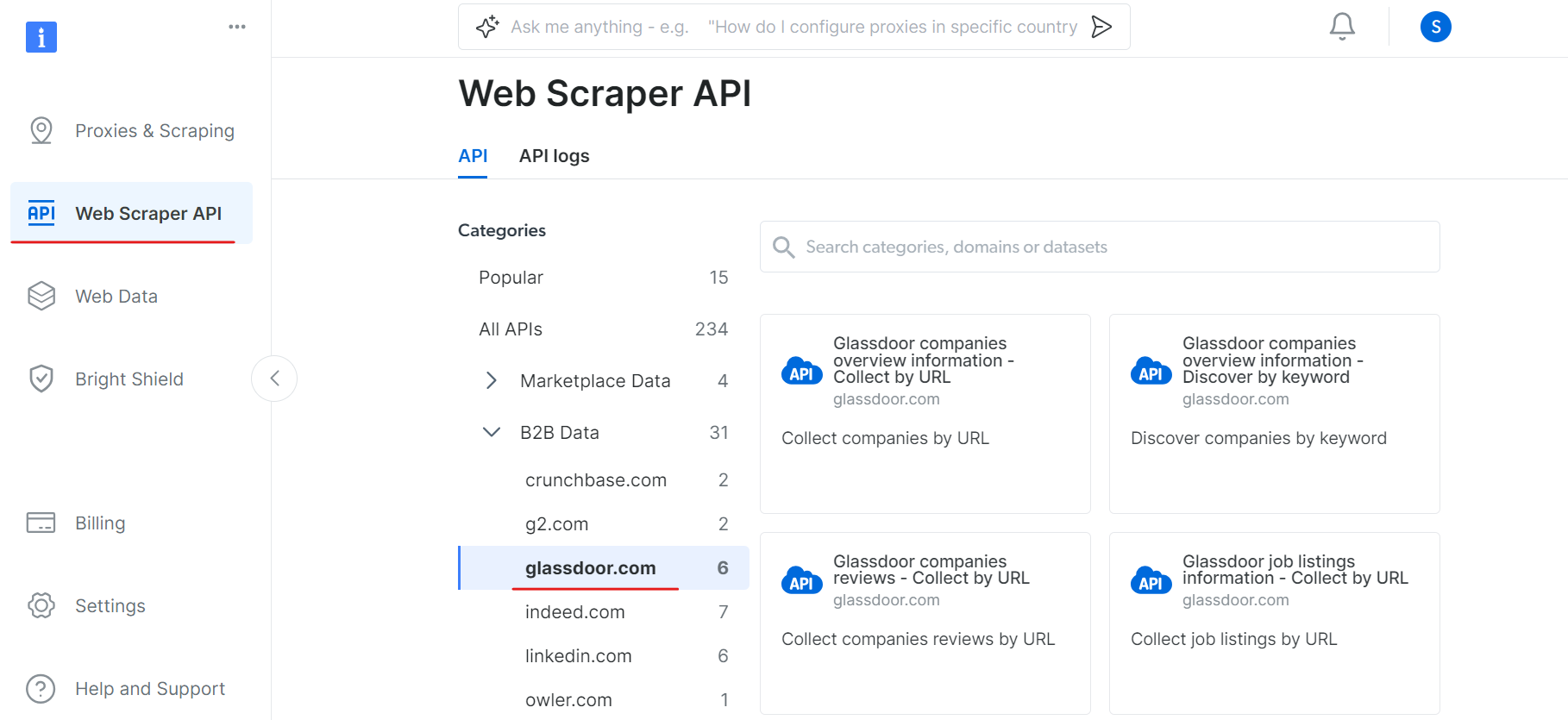
En «Información general de las empresas de Glassdoor», obtenga su token API y copie su ID de conjunto de datos (por ejemplo, gd_l7j0bx501ockwldaqf).
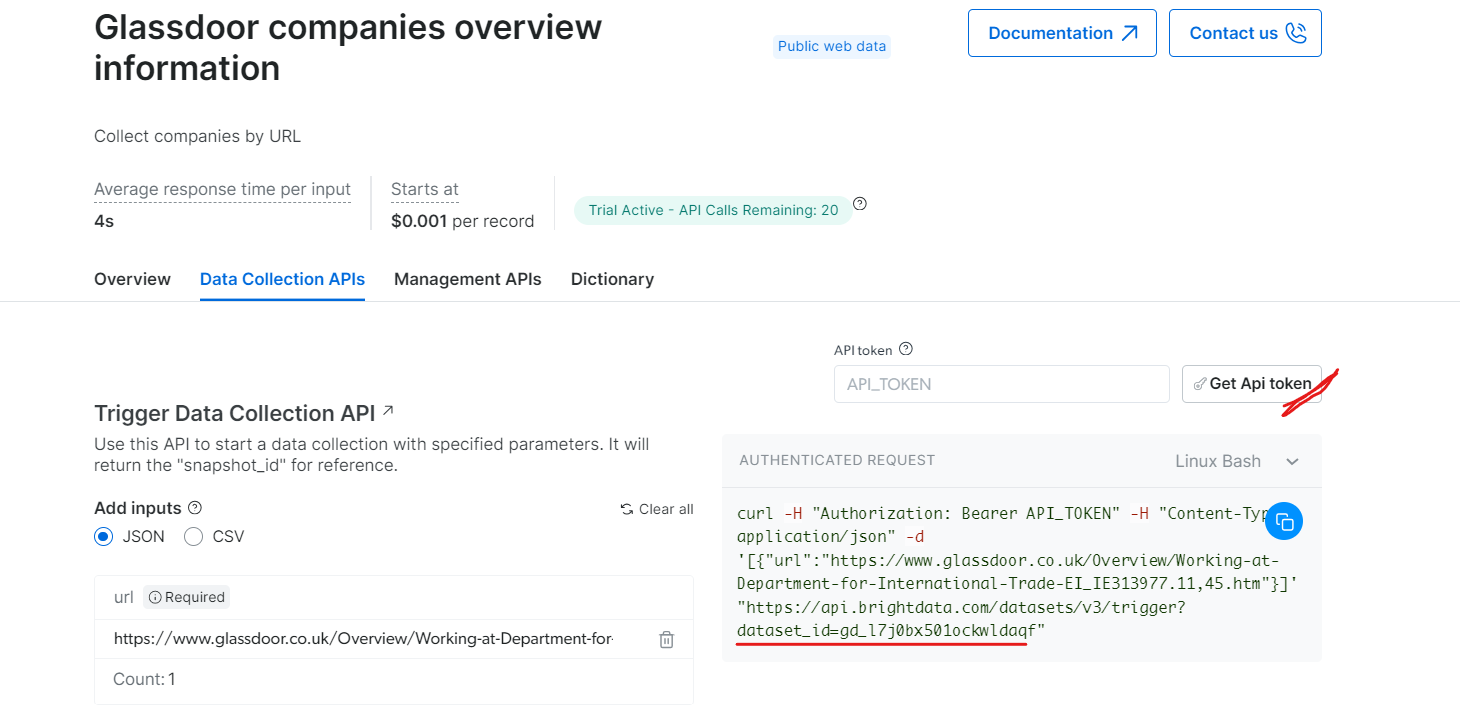
A continuación, le mostramos un sencillo fragmento de código que muestra cómo extraer datos de empresas proporcionando la URL, el token API y el ID del Conjunto de datos.
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Activa un conjunto de datos utilizando la API de BrightData.
Argumentos:
api_token (str): El token API para la autenticación.
dataset_id (str): El ID del conjunto de datos que se va a activar.
company_url (str): La URL de la página de la empresa que se va a analizar.
Devuelve:
dict: La respuesta JSON de la API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/conjuntos_de_datos/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)Al ejecutar el código, recibirá un ID de instantánea como se muestra a continuación:

Utilice el ID de instantánea para recuperar los datos reales de la empresa. Ejecute el siguiente comando en su terminal. Para Windows, utilice:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Para Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/conjuntos_de_datos/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"Después de ejecutar el comando, obtendrá los datos deseados.
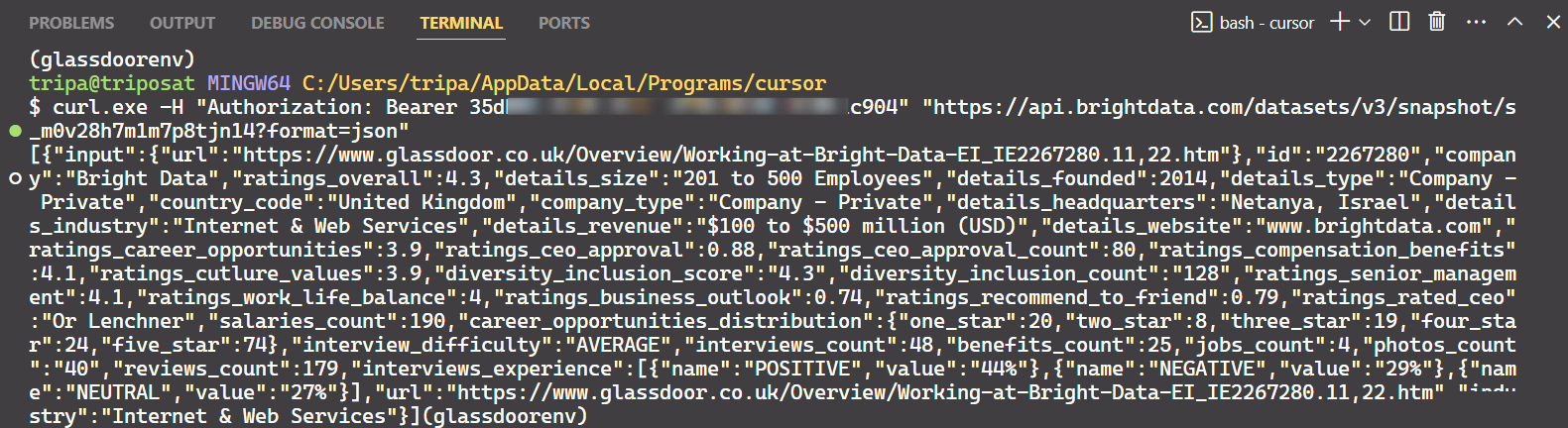
¡Eso es todo lo que hay que hacer!
Del mismo modo, puede extraer varios tipos de datos de Glassdoor modificando el código. He explicado un método, pero hay otras cinco formas de hacerlo. Por lo tanto, le recomiendo que explore estas opciones para extraer los datos que desee. Cada método se adapta a necesidades de datos específicas y le ayuda a obtener los datos exactos que necesita.
Conclusión
En este artículo se han analizado varios métodos de paginación que se utilizan habitualmente en los sitios web modernos, como la paginación numerada, los botones «cargar más» y el desplazamiento infinito. También se han proporcionado ejemplos de código para implementar eficazmente estas técnicas de paginación. Sin embargo, aunque el tratamiento de la paginación era una parte del Scraping web, superar la detección antibots suponía un reto importante.
Evadir las detecciones antibots avanzadas puede ser bastante complejo y, a menudo, produce diversos grados de éxito. Las herramientas de Bright Data ofrecen una solución optimizada y rentable, que incluye Web Unlocker, Navegador de scraping y API de Scraper para todas sus necesidades de Scraping web. Con solo unas pocas líneas de código, puede lograr una mayor tasa de éxito sin la molestia de gestionar intrincadas medidas antibots.
¿No le interesa en absoluto participar en el proceso de scraping? ¡Eche un vistazo a nuestro mercado de Conjuntos de datos!
Regístrate hoy mismo para obtener una prueba gratuita.





