

En este tutorial, verás:
- Qué es Qwen3 y por qué destaca como LLM
- Por qué es adecuado para tareas de web scraping
- Cómo utilizar Qwen3 localmente para el web scraping con Hugging Face
- Sus principales limitaciones y cómo superarlas
- Algunas alternativas a Qwen3 para el scraping basado en IA
Sumerjámonos.
¿Qué es Qwen3?
Qwen3 es la última generación de LLM desarrollada por el equipo Qwen de Alibaba Cloud. El modelo es de código abierto y se puede explorar libremente en GitHub, disponiblebajo la licencia Apache 2.0. Esto es ideal para la investigación y el desarrollo.
Las principales características de Qwen3 son:
- Razonamiento híbrido: Puede alternar entre un “modo pensante” para razonamientos lógicos complejos (como matemáticas o codificación) y un “modo no pensante” para respuestas más rápidas y de uso general. Esto le permite controlar la profundidad del razonamiento para obtener un rendimiento y una rentabilidad óptimos.
- Diversos modelos: Qwen3 ofrece un amplio conjunto de modelos, incluidos modelos densos (que van de 0,6B a 32B parámetros) y modelos de Mezcla de Expertos (MoE) (como las variantes 30B y 235B).
- Capacidades mejoradas: Presenta avances significativos en el razonamiento, el seguimiento de instrucciones, las capacidades de los agentes y el soporte multilingüe (que abarca más de 100 idiomas y dialectos).
- Datos de entrenamiento: Qwen3 se entrenó con un enorme conjunto de datos de aproximadamente 36 billones de tokens, casi el doble que su predecesor, Qwen2.5.
¿Por qué usar Qwen3 para Web Scraping?
Qwen3 facilita el web scraping automatizando la interpretación y estructuración de contenidos no estructurados en páginas HTML. Esto elimina la necesidad de analizar manualmente los datos. En lugar de escribir lógica compleja para extraer datos, el modelo entiende la estructura de la página por usted.
Confiar en Qwen3 para el análisis sintáctico de datos web es especialmente útil cuando se trata de desafíos comunes de raspado web como:
- Cambios frecuentes en el diseño de las páginas: Un escenario popular es Amazon, donde cada página de producto puede mostrar datos diferentes.
- Datos no estructurados: Qwen3 puede extraer información valiosa de texto desordenado y de formato libre sin necesidad de selectores codificados o lógica regex.
- Contenido difícil de analizar: En el caso de páginas con una estructura incoherente o compleja, un LLM como Qwen3 elimina la necesidad de una lógica de análisis personalizada.
Para profundizar en el tema, lea nuestra guía sobre el uso de la IA para el scraping web.
Otra gran ventaja es que Qwen3 es de código abierto. Eso significa que puede ejecutarlo localmente en su propia máquina de forma gratuita, sin depender de API de terceros o pagar por LLMs premium como el de OpenAI. Esto le da un control total sobre su arquitectura de scraping.
Cómo realizar Web Scraping con Qwen3 en Python
En esta sección, la página de destino será la página de producto “Affirm Water Bottle” del sandbox “Ecommerce Test Site to Learn Web Scraping“:
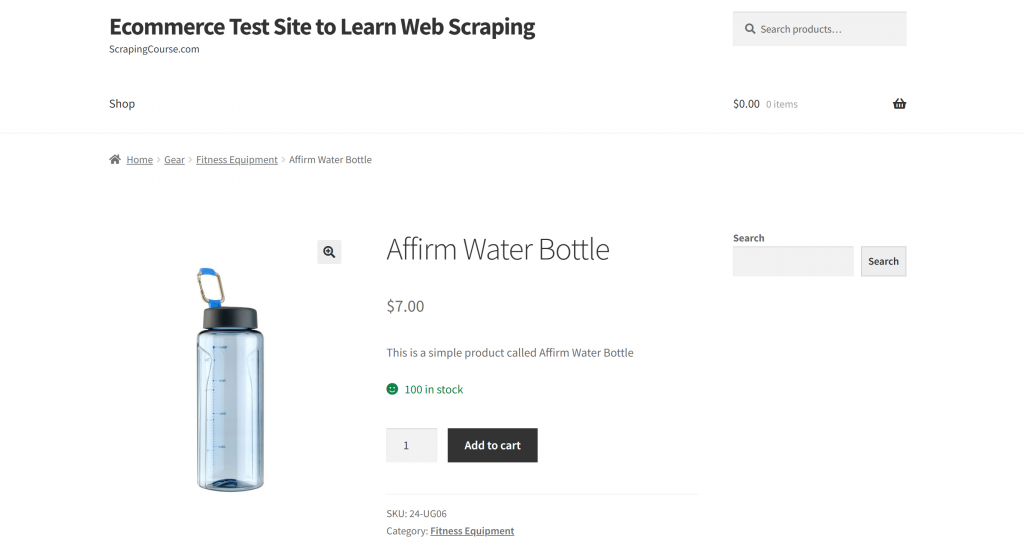
Esta página es un buen ejemplo porque las páginas de productos de comercio electrónico suelen tener estructuras incoherentes y mostrar distintos tipos de datos. Esa variabilidad es lo que hace que el raspado web de comercio electrónico sea especialmente difícil, y también donde la IA puede marcar una gran diferencia.
En este caso, utilizaremos un scraper basado en Qwen3 para extraer de forma inteligente información sobre productos sin necesidad de escribir reglas de análisis manual.
Nota: Este tutorial le mostrará cómo utilizar Hugging Face para ejecutar modelos Qwen3 localmente y de forma gratuita. Ahora bien, existen otras opciones viables. Estas incluyen conectarse a un proveedor LLM que aloje modelos Qwen3, o utilizar soluciones como Ollama.
Sigue los pasos que se indican a continuación para empezar a extraer datos web con Qwen3.
Paso 1: Configure su proyecto
Antes de empezar, asegúrate de que tienes Python 3.10+ instalado en tu máquina. En caso contrario, descárgalo y sigue las instrucciones de instalación.
A continuación, ejecute el siguiente comando para crear una carpeta para su proyecto de scraping:
mkdir qwen3-scraperEl directorio qwen3-scraper servirá como carpeta de proyecto para el web scraping utilizando Qwen3.
Navega a la carpeta en tu terminal e inicializa un entorno virtual Python dentro de ella:
cd qwen3-scraper
python -m venv venvCarga la carpeta del proyecto en tu IDE de Python preferido. Visual Studio Code con la extensión Python o PyCharm Community Edition son excelentes opciones.
Crear un archivo scraper.py en la carpeta del proyecto, que ahora debe contener:

En este momento, scraper.py es sólo un script Python vacío, pero pronto contendrá la lógica para el raspado web LLM.
A continuación, active el entorno virtual. En Linux o macOS, ejecute:
source venv/bin/activateDe forma equivalente, en Windows, utilice:
venv/Scripts/activateNota: Los siguientes pasos le guiarán a través de la instalación de todas las bibliotecas necesarias. Si prefiere instalarlo todo de una vez, puede utilizar ahora el comando que se indica a continuación:
pip install transformers torch accelerate requests beautifulsoup4 markdownify¡Impresionante! Su entorno Python está totalmente configurado para el web scraping con Qwen3.
Paso #2: Configurar Qwen3 en Hugging Face
Como se mencionó al principio de esta sección, utilizaremos Hugging Face para ejecutar un modelo Qwen3 localmente. Esto es ahora posible porque Hugging Face ha añadido recientemente soporte para modelos Qwen3.
En primer lugar, asegúrese de que se encuentra en un entorno virtual activado. A continuación, instale las dependencias necesarias de Hugging Face ejecutando:
pip install transformers torch accelerateA continuación, en tu archivo scraper.py, importa las clases necesarias de la biblioteca de transformadores de Hugging Face:
from transformers import AutoModelForCausalLM, AutoTokenizerAhora, usa esas clases para cargar un tokenizador y el modelo Qwen3:
model_name = "Qwen/Qwen3-0.6B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)En este caso, estamos utilizando el modelo Qwen/Qwen3-0.6B, pero puedes elegir entre más de 40 modelos Qwen3 disponibles en Hugging Face.
¡Impresionante! Ya tienes todo listo para utilizar Qwen3 en tu script Python.
Paso 3: Obtener el HTML de la página de destino
Ahora, es el momento de recuperar el contenido HTML de la página de destino. Puedes lograrlo usando un poderoso cliente HTTP de Python como Requests.
En su entorno virtual activado, instale la biblioteca Requests:
pip install requestsA continuación, en su archivo scraper.py, importe la biblioteca:
import requestsUtilice el método get() para enviar una petición HTTP GET a la URL de la página:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)El servidor responderá con el HTML sin procesar de la página. Para ver el contenido HTML completo, puede imprimir response.content:
print(response.content)El resultado debería ser esta cadena HTML:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Affirm Water Bottle – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>Ahora tienes el HTML completo de la página de destino disponible en Python. ¡Pasemos a analizarlo y extraer los datos que necesitamos usando Qwen3!
Paso nº 4: Convertir el HTML de la página a Markdown (opcional, pero recomendado)
Nota: Este paso no es estrictamente necesario. Sin embargo, puede ahorrarle mucho tiempo a nivel local (y dinero si utiliza proveedores de Qwen3 de pago). Por tanto, merece la pena tenerlo en cuenta.
Tómate un momento para explorar cómo otras herramientas de raspado web basadas en IA, como Crawl4AI y ScrapeGraphAI, manejan el HTML sin procesar. Verás que ambas ofrecen opciones para convertir HTML en Markdown antes de pasar el contenido al LLM configurado.
¿Por qué lo hacen? Hay dos razones principales:
- Rentabilidad: La conversión a Markdown reduce el número de tokens enviados a la IA, lo que le ayuda a ahorrar dinero.
- Procesamiento más rápido: Menos datos de entrada significa menores costes de cálculo y respuestas más rápidas.
Para más información, lea nuestra guía sobre por qué los nuevos agentes de IA eligen Markdown en lugar de HTML.
En este caso, como Qwen3 se ejecuta localmente, la rentabilidad no es importante porque no estás conectado a un proveedor LLM externo. Lo que realmente importa aquí es un procesamiento más rápido. ¿Por qué? Porque pedirle al modelo Qwen3 elegido (que es uno de los modelos más pequeños disponibles, por cierto) que procese toda la página HTML puede llevar fácilmente a una CPU i7 al 100% de uso durante varios minutos.
Eso es demasiado, ya que no quieres sobrecalentar o congelar tu portátil o PC. Así que reducir el tamaño de la entrada convirtiéndola a Markdown tiene mucho sentido.
Es hora de replicar la lógica de conversión de HTML a Markdown y reducir el uso de tokens.
En primer lugar, abra la página web de destino en modo incógnito para garantizar una sesión nueva. A continuación, haz clic con el botón derecho del ratón en cualquier parte de la página y selecciona “Inspeccionar” para abrir las DevTools. Ahora, examine la estructura de la página. Verás que todos los datos relevantes están contenidos en el elemento HTML identificado por el selector CSS #main:
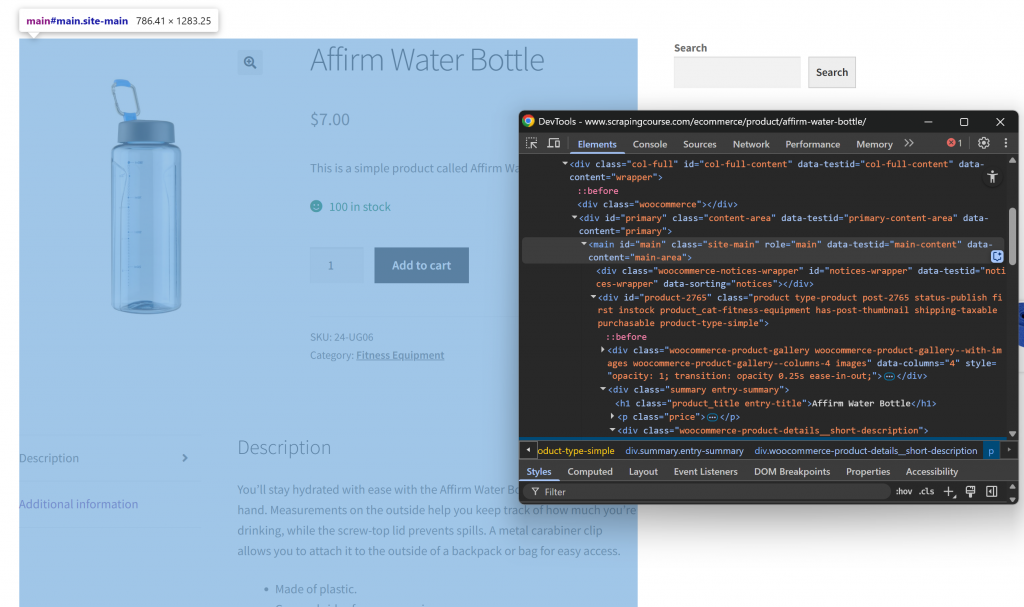
Al centrarse en el contenido dentro de #main en el proceso de conversión de HTML a Markdown, se extrae sólo la parte de la página con datos relevantes. Esto evita incluir encabezados, pies de página y otras secciones que no le interesan. De este modo, la salida final en Markdown será mucho más corta.
Para seleccionar sólo el HTML del elemento #main, necesitas una librería de análisis HTML de Python como Beautiful Soup. En tu entorno virtual activado, instálala con este comando:
pip install beautifulsoup4Si no estás familiarizado con su API, sigue nuestra guía sobre raspado web Beautiful Soup.
A continuación, impórtalo en scraper.py:
from bs4 import BeautifulSoupAhora, usa Beautiful Soup para:
- Analiza el HTML sin procesar obtenido con Requests
- Seleccione el elemento
#main - Extraer su contenido HTML
Implementa los tres micro-pasos anteriores con este snippet:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element
main_html = str(main_element)Si imprimes main_html, verás algo como esto:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
<div id="product-2765" class="product type-product post-2765 status-publish first instock product_cat-fitness-equipment has-post-thumbnail shipping-taxable purchasable product-type-simple">
<!-- omitted for brevity... -->
</div>
</main>Esta cadena es mucho más pequeña que la página HTML completa, pero aún así contiene unos 13.402 caracteres.
Para reducir aún más el tamaño sin perder datos importantes, convierte el HTML extraído a Markdown. En primer lugar, instala la biblioteca markdownify:
pip install markdownifyImportar markdownify en scraper.py:
from markdownify import markdownifyA continuación, utilízalo para convertir el HTML de #main a Markdown:
main_markdown = markdownify(main_html)El proceso de conversión de datos debe producir un resultado como el siguiente:
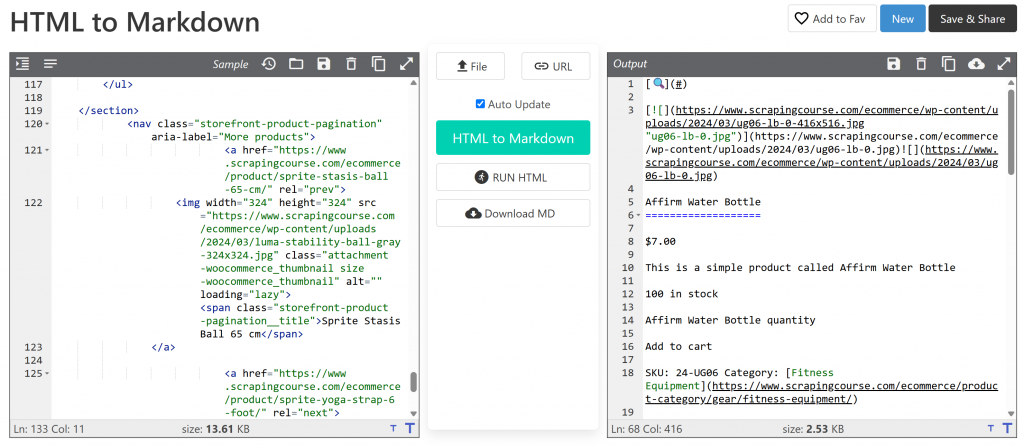
La versión Markdown ocupa unos 2,53 KB, frente a los 13,61 KB del HTML #main original. Esto supone una reducción de tamaño del 81%. Además, lo que importa es que la versión Markdown conserva todos los datos clave que necesitas raspar.
Con este sencillo truco, has reducido un voluminoso fragmento HTML en una cadena compacta Markdown. Esto acelerará mucho el análisis local de datos LLM a través de Qwen3.
Paso 5: Utilizar Qwen3 para el análisis de datos
Para conseguir que Qwen3 raspe los datos correctamente, necesitas escribir un prompt efectivo. Empiece por analizar la estructura de la página de destino:
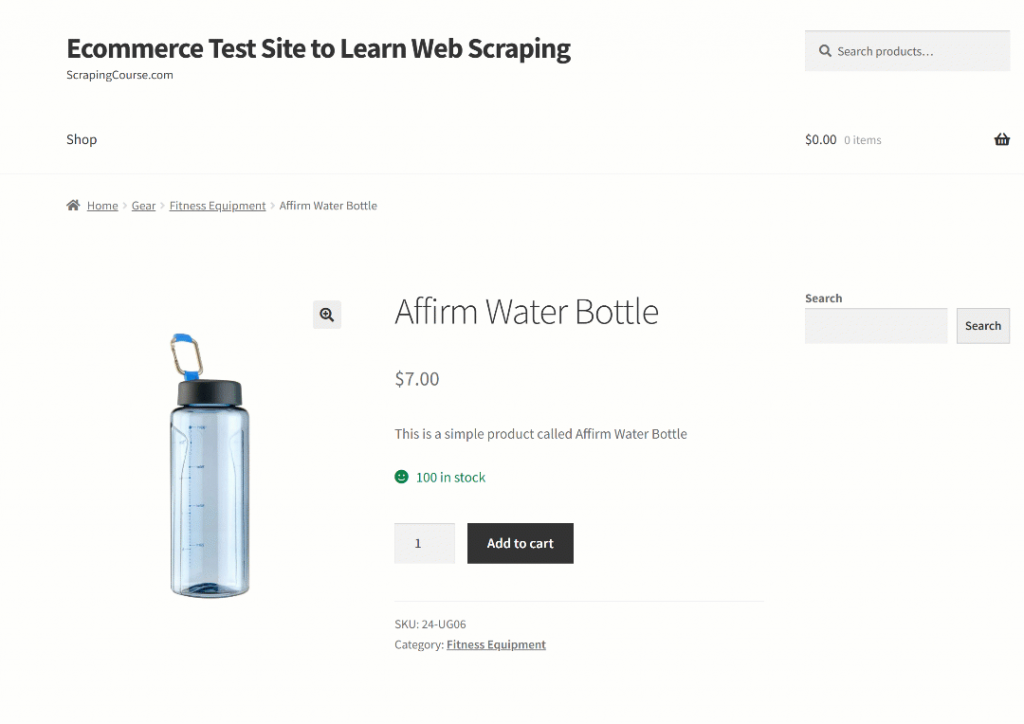
La parte superior de la página es idéntica para todos los productos. En cambio, la tabla “Información adicional” cambia en función del producto. Dado que es posible que desee que su solicitud funcione en todas las páginas de productos de la plataforma, podría describir su tarea en términos generales de la siguiente manera:
Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
<MARKDOWN_PRODUCT_CONTENT>Esta instrucción indica a Qwen3 que extraiga datos estructurados del contenido de main_markdown. Para obtener resultados fiables, es una buena idea hacer que su solicitud sea lo más clara y específica posible. Eso ayuda al modelo a entender exactamente lo que usted espera.
Ahora, utiliza Cara de Abrazo para ejecutar el prompt, como se explica en la documentación oficial:
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")El código anterior utiliza apply_chat_template() para formatear el mensaje de entrada y genera una respuesta del modelo Qwen3 configurado.
Nota: Un detalle clave es establecer enable_thinking=False en apply_chat_template(). Por defecto, esa opción está establecida en True, lo que activa el modo de “razonamiento” interno del modelo. Esta tarea es útil para la resolución de problemas complejos, pero innecesaria y potencialmente contraproducente para tareas sencillas, como el web scraping. Desactivarlo garantiza que el modelo se centre exclusivamente en la extracción, sin añadir explicaciones ni suposiciones.
Fantástico. Acabas de ordenar a Qwen3 que realice el web scraping en la página de destino.
Ahora, todo lo que queda es ajustar la salida y exportarla a JSON.
Paso nº 6: Convertir la salida Qwen3
La salida producida por el modelo Qwen3-0.6B puede variar ligeramente entre ejecuciones. Se trata de un comportamiento típico de los LLM, sobre todo de los modelos más pequeños como el utilizado aquí.
Así, a veces la variable product_raw_string contendrá los datos deseados como una cadena JSON sin formato. Otras veces, puede envolver el JSON dentro de un bloque de código Markdown, como este:
```jsonn{n "sku": "24-UG06",n "name": "Affirm Water Bottle",n "images": ["https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"],n "price": "$7.00",n "description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much you’re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",n "category": "Fitness Equipment",n "additional_information": {n "Activity": "Yoga, Recreation, Sports, Gym",n "Gender": "Men, Women, Boys, Girls, Unisex",n "Material": "Plastic"n }n}n```Para manejar ambos casos, puede utilizar una expresión regular para extraer el contenido JSON cuando aparezca dentro de un bloque Markdown. En caso contrario, trata la cadena como JSON sin procesar. A continuación, puede analizar los datos JSON resultantes al diccionario Python json.loads():
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)Allá vamos. En este punto, has convertido los datos obtenidos en un objeto Python utilizable. El último paso es exportar los datos a un formato más fácil de usar.
Paso 7: Exportar los datos extraídos
Ahora que tienes los datos del producto en un diccionario de Python, puedes guardarlos en un archivo JSON como este:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Esto creará un archivo llamado product.json que contendrá los datos estructurados de su producto.
¡Bien hecho! Tu Qwen3 web scraper está ahora completo.
Paso 8: Póngalo todo junto
Aquí está el código final de su scraper.py Qwen3 script de raspado:
from transformers import AutoModelForCausalLM, AutoTokenizer
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
import re
# The Qwen3 model to use for web scraping
model_name = "Qwen/Qwen3-0.6B"
# Load the tokenizer and the Qwen3 model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get the outer HTML of the selected element and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Define tge data extraction prompt
prompt = prompt = f"""Extract main product data from the HTML content below. Respond with a raw string in JSON format containing the scraped data in product attributes as below:nn
SAMPLE JSON ATTRIBUTES: n
sku, name, images, price, description, category + fields extracted from the "Additional information" section
CONTENT:n
{main_markdown}
"""
# Execute the prompt
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# Retrieve the output in text format
product_raw_string = tokenizer.decode(output_ids, skip_special_tokens=True).strip("n")
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)Ejecuta el script con:
python scraper.pyLa primera vez que ejecutes el script, Hugging Face descargará automáticamente el modelo Qwen3 seleccionado. Este modelo ocupa alrededor de 1,5 GB, por lo que la descarga puede tardar algún tiempo dependiendo de tu velocidad de Internet. En el terminal, verás una salida como:
model.safetensors: 100%|██████████████████████████████████████████████████████████| 1.50G/1.50G [00:49<00:00, 30.2MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████████| 239/239 [00:00<?, ?B/s]El script puede tardar un poco en completarse, ya que PyTorch estresará tu CPU para cargar y ejecutar el modelo.
Una vez que el script finalice, creará un archivo llamado product.json en la carpeta del proyecto. Abra este archivo y debería ver los datos estructurados del producto de la siguiente manera:
{
"sku": "24-UG06",
"name": "Affirm Water Bottle",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/ug06-lb-0.jpg"
],
"price": "$7.00",
"description": "You’ll stay hydrated with ease with the Affirm Water Bottle by your side or in hand. Measurements on the outside help you keep track of how much youu2019re drinking, while the screw-top lid prevents spills. A metal carabiner clip allows you to attach it to the outside of a backpack or bag for easy access.",
"category": "Fitness Equipment",
"additional_information": {
"Activity": "Yoga, Recreation, Sports, Gym",
"Gender": "Men, Women, Boys, Girls, Unisex",
"Material": "Plastic"
}
}Nota: El resultado exacto puede variar ligeramente debido a la naturaleza de los LLM, que pueden estructurar el contenido raspado de diferentes maneras.
¡Et voilà! Su script acaba de transformar contenido HTML sin procesar en JSON limpio y estructurado. Todo gracias a Qwen3 web scraping.
Superar la principal limitación de este enfoque del Web Scraping
Claro, en nuestro ejemplo, todo funcionaba sin problemas. Pero eso es sólo porque estábamos raspando un sitio de demostración construido específicamente para ese propósito.
En el mundo real, la mayoría de los sitios web son conscientes del valor de sus datos públicos. Por lo tanto, a menudo implementan técnicas anti-scraping que pueden bloquear rápidamente las solicitudes HTTP automatizadas realizadas con herramientas como requests.
Además, este enfoque no funcionará en sitios con mucho JavaScript. Esto se debe a que la combinación de peticiones y BeautifulSoup funciona bien para páginas estáticas, pero no puede manejar contenido dinámico. Si no estás familiarizado con la diferencia, echa un vistazo a nuestro artículo sobre contenido estático vs dinámico.
Otros posibles bloqueadores son las prohibiciones de IP, los limitadores de velocidad, la huella digital TLS, los CAPTCHA y otros. En resumen, el web scraping no es fácil, especialmente ahora que la mayoría de los sitios web están equipados para detectar y bloquear rastreadores y bots de IA.
La solución es utilizar una API de Web Unlocker construida para el moderno web scraping con peticiones. Este servicio se encarga de todo lo difícil, como rotar IPs, resolver CAPTCHAs, renderizar JavaScript y evitar la protección contra bots.
Todo lo que tiene que hacer es pasar la URL de la página de destino al punto final de la API de Web Unlocker. La API devolverá HTML totalmente desbloqueado, incluso si la página depende de JavaScript o está protegida por sistemas anti-bot avanzados.
Para integrarlo en tu script, sólo tienes que sustituir la línea requests.get() del Paso #3 por el siguiente código:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the payload with the target URL
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/affirm-water-bottle/", # Replace this with your target URL on a different scraping scenario
"format": "raw"
}
# Send the request
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)
# Get the unlocked HTML
html_content = response.textPara más detalles, consulte la documentación oficial de Web Unlocker.
Con un Web Unlocker instalado, puede utilizar Qwen3 con confianza para extraer datos estructurados de cualquier sitio web: se acabaron los bloqueos, los problemas de representación y los contenidos que faltan.
Alternativas a Qwen3 para Web Scraping
Qwen3 no es el único LLM que puede utilizar para el análisis automatizado de datos web. Explora algunos enfoques alternativos en las siguientes guías:
- Web Scraping Con Gemini: Tutorial Completo
- Web Scraping Usando Perplexity: Guía paso a paso
- LLM Web Scraping con ScrapeGraphAI
- Cómo crear un raspador de IA con Crawl4AI y DeepSeek
- Web Scraping con LLaMA 3: Convierta cualquier sitio web en JSON estructurado
Conclusión
En este tutorial, aprendiste cómo ejecutar Qwen3 localmente usando Hugging Face para construir un raspador web potenciado por IA. Uno de los mayores obstáculos en el raspado web es ser bloqueado, pero eso se solucionó utilizando la API Web Unlocker de Bright Data.
Como se ha comentado anteriormente, la combinación de Qwen3 con la API Web Unlocker permite extraer datos de prácticamente cualquier sitio web. Todo ello sin necesidad de lógica de análisis personalizada. Esta configuración muestra solo uno de los muchos casos de uso potentes que hace posible la infraestructura de Bright Data, ayudándole a crear canalizaciones de datos web escalables e impulsadas por IA.
¿Por qué detenerse aquí? Considere la posibilidad de explorar las API de Web Scraper:puntos finales dedicadospara extraer datos web frescos, estructurados y totalmente conformes de más de 120 sitios web populares.
Regístrese hoy mismo para obtener una cuenta gratuita de Bright Data y empiece a construir con soluciones de scraping preparadas para la IA.




